之前在Glue 上進行資料存取時都是使用 S3,而今天我們要透過 Glue Job 將 S3 資料儲存到 Redshift
首先我們先準備資料,這次我是使用 Day 17 的運算結果,每個 User 最喜歡的前五名商品清單,我將它放到新的 S3 路徑下,並且將他切成三等份每一份大約 30 萬筆資料,因為這次要模擬每天都有新的資料新增到 s3 並且要同步到 Redshift,所以第一天的資料路徑為 s3://it.sample.s3/toRedshiftFile/20201001/top5-1.csv
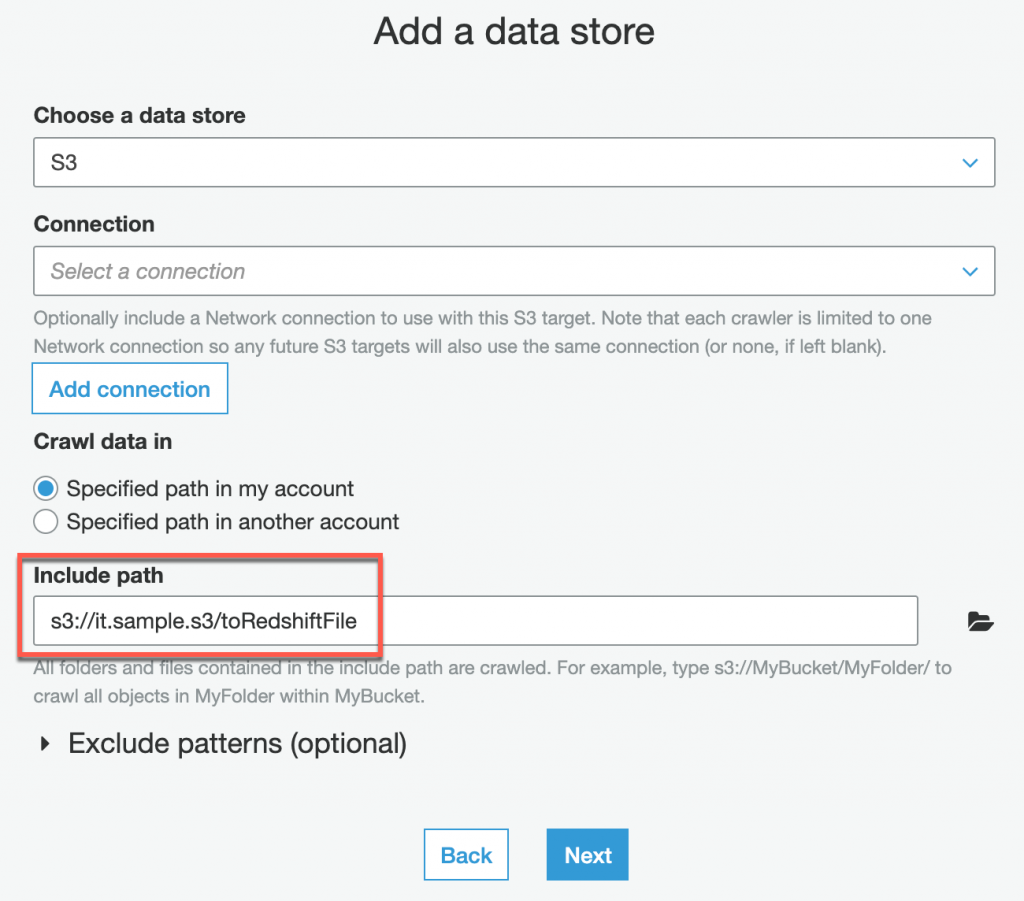
創建新的 Crawler(top5-crawler),詳細創建方法可以參考 Day 7,這裡會列出不同需要調整的步驟, Crawler 第三步驟的 Include path 需要修改為 s3://it.sample.s3/toRedshiftFile
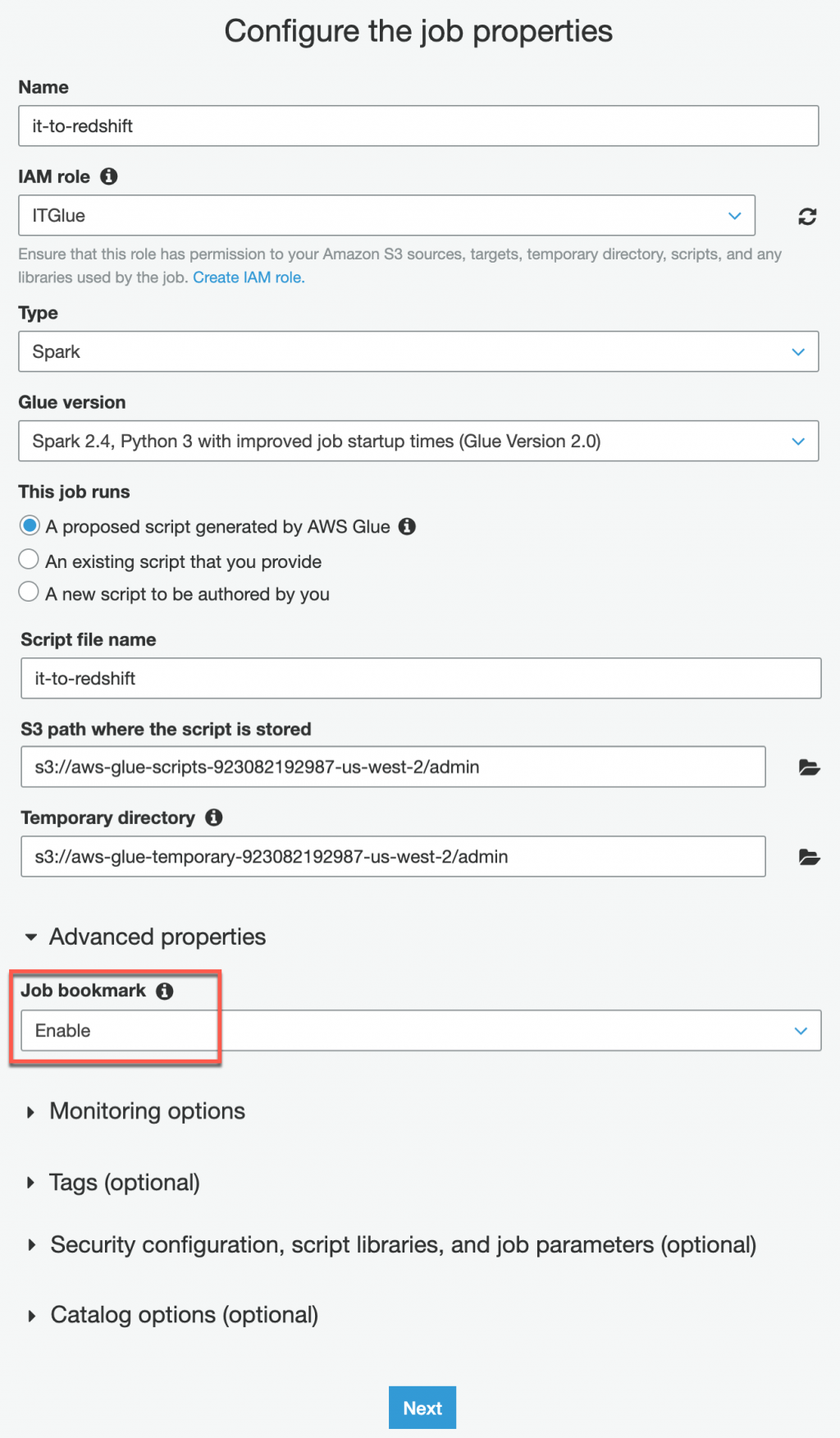

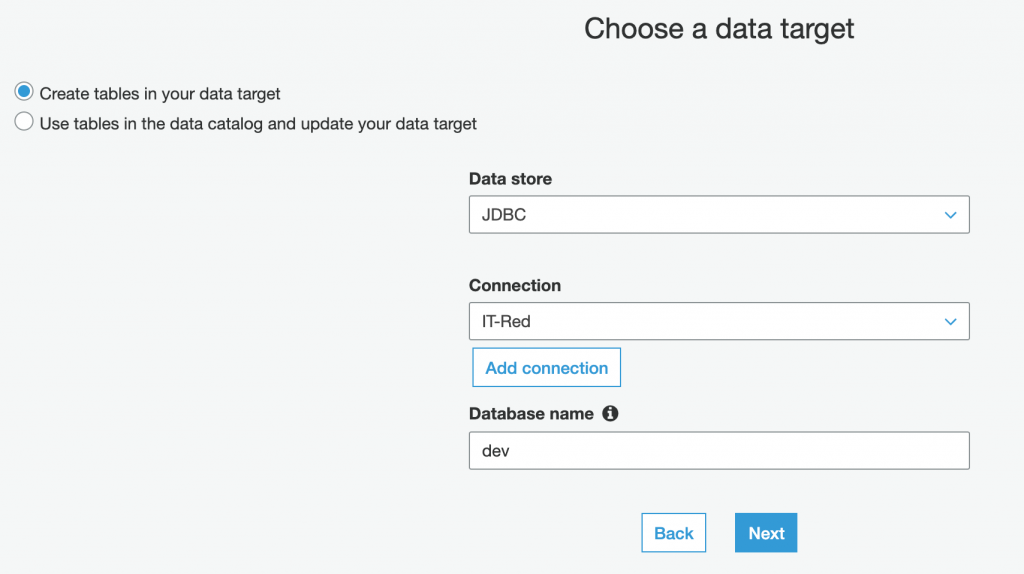
datasink4 = glueContext.write_dynamic_frame.from_jdbc_conf(frame = dropnullfields3, catalog_connection = "IT-Red", connection_options = {"dbtable": "top5", "database": "dev"}, redshift_tmp_dir = args["TempDir"], transformation_ctx = "datasink4")


 iThome鐵人賽
iThome鐵人賽