上一篇談到從 .gitlab-ci.yml 開始建立關卡及工作,而後依序分派到工作佇列,等待 GitLab Runner Server 上的 Runner 來承接工作的這段過程,可以怎麼讓流水線跑得更快一些。接下來將繼續往下談,當 Runner 接到工作之後,可以怎麼讓它更快地完成工作?
首先,可以先思考,當 GitLab Runner 承接到工作後,直到工作執行完成,期間它做了哪些事情?
在官方的文件上尋覓了許久,一直沒能找到談論各種 GitLab Runner 在承接工作後做了哪些事情的生命週期 (Lifecycle) 描述,所以這邊挑了個人比較熟悉的 Docker 作為 Runner executor ,手動作了一個簡單的實驗,把目前已知在 .gitlab-ci.yml 上有配置設定後,Runner 上就需要跟著做一些工作的流程全都加在一起,像是下載工作成品、建立工作成品、重置快取、建立快取等等的都湊在一個工作之中(有興趣可以直接查看執行結果)。
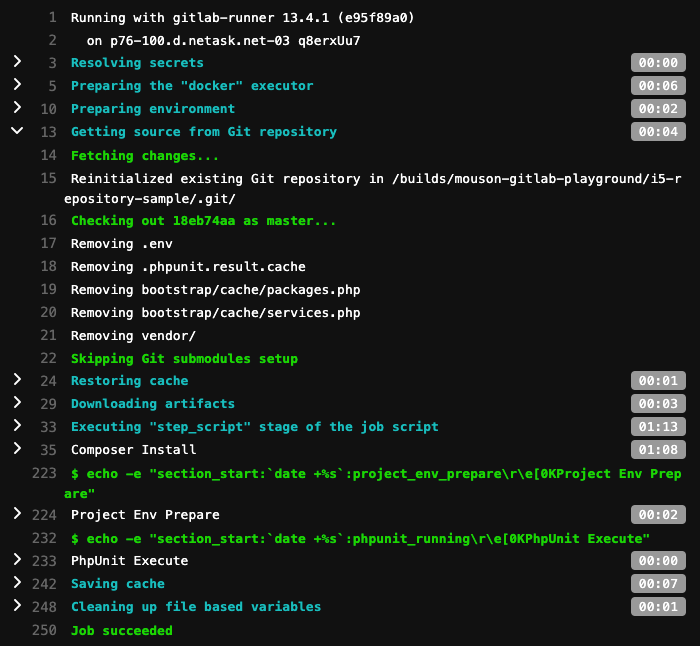
如上圖的工作程序,在這個 Runner 承接了工作之後,總共有這幾個階段:
有了這些程序的過程,就可以逐一討論這每一個階段可以怎麼加速:
當 GitLab Runner 承接工作之後,僅只是在該 Runner 上執行工作,這些工作可能還需要一些外部支援,以 Docker Executor 來說,如果執行的環境沒有工作需要的 Docker Image,那就必須透過網路將 Docker 下載回來;如系統定義的快取檔案不放在 Runner 本地,也需要再次的從網路下載,這些都需要透過網路連線,因此 Runner 與需要的外部資源間的網路環境、品質會影響到整個 Runner 完整將工作執行完成的速度。
如上一段提到的,當本地沒有使用到的 Docker image 的暫存系統就需要再次的從 Docker registry 上面取得,除網路環境好可以加速取得的速度外,使用的 Docker Image 如果也可以小一點,那麼對於整個 Runner 的執行效率也是有幫助的。
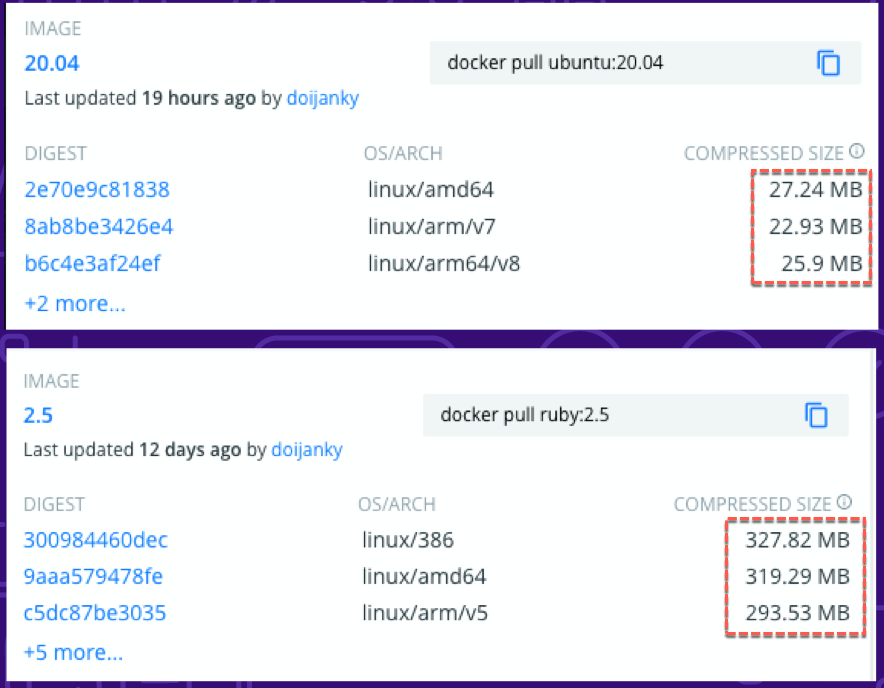
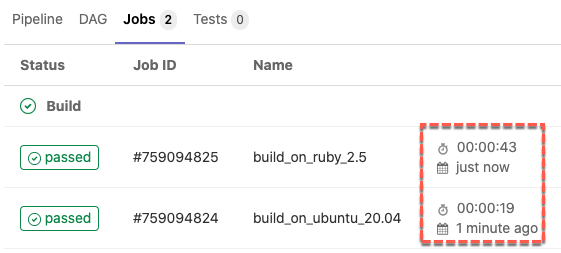
在這邊以 GitLab 官方提供的免費 Runner 為例,其提供的通常預設是 ruby:2.5 的 Docker Image,如執行的 Docker Image 可以替換成如 ubuntu:20.04 執行速度上就會有一個層級的差異,如下圖,執行相同 script,僅差別在用不同 Docker Image 的兩個工作,ruby:2.5 執行了 43 秒,但使用 ubuntu:20.04 僅花費 19 秒。
在小型的專案中 Git 物件可能不多,一旦變成大型專案光是 Git Commit 的數量動輒上萬個,這樣的專案如要完整的 clone 可能都需要花費很長一段時間,如果需要在較大型的 Repo 上建立建立 CI 流程,那麼 Runner 從 Git Repo 上取得原始碼的這段時間就必須要重視。
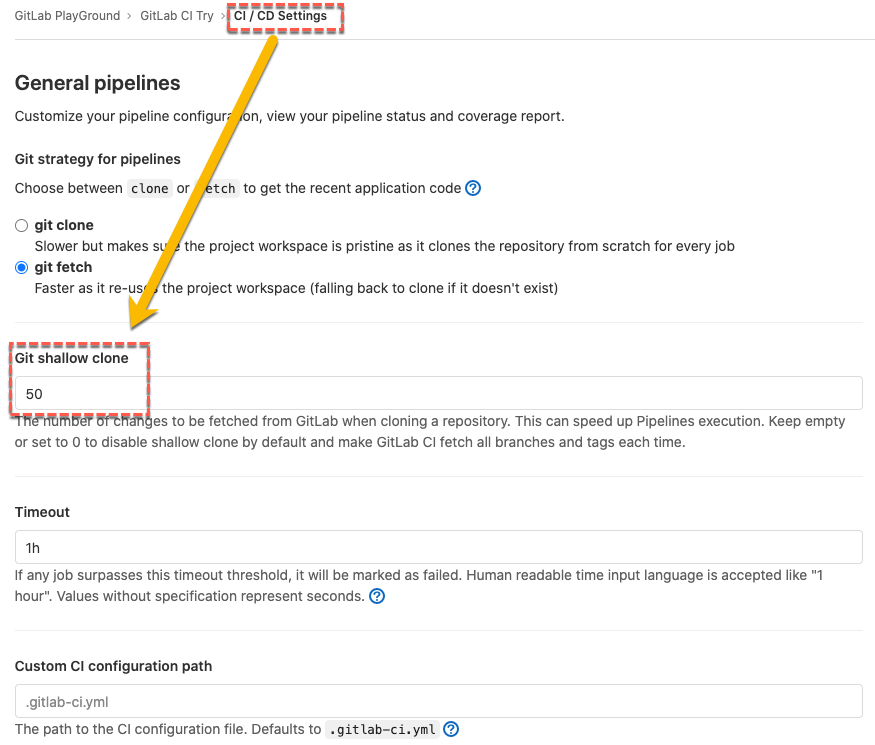
在 GitLab 的「Settings -> CI/CD -> General pipelines」段落下,有一個 「Git shallow clone」選項,其就是在設定,每次只取得該分支最後的幾個變更,GitLab 目前預設為 50 個,如果是可以調整的。
現階段許多程式語言都會有自己的相依套件管理工具,在 Script 執行時都會再次的執行套件下載動作,使用的套件們的大小也關係著工作完整執行完成的速度。因此也可以思考:
快取的設定可以參考:Day 24
有些時候,執行的工作是可以考慮拆組後使用 GitLab 的平行化執行處理的。像是大型的單元測試案例,像是單元測試,小專案數量不多的測試案例可能無感,但專案持續的變大如果單元測試數量多到全部執行完成需要一小段時間,那麼就可以開始思考,這些單元測試是否可以拆分?是否都是必要執行的測試?如可以拆分,則可以思考,使用的單元測試是否可以套用 GitLab 提供的平行化處理機制。
平行處理可以參考:Day 17
GitLab Runner 上面調教的方法其實還有蠻多還沒談論到的,在這篇會持續的更新,把各種可以讓 Runner 跑得更快的方法統一記錄在這裡,也期待如果有朋友有其他的想法也歡迎分享。
我是墨嗓(陳佑竹),期待這系列的文章能夠讓人有些幫助。

