分區(Partitioning)
對數據或數據庫進行分區是指將數據集分成多個部分並分別存儲。這是聚合和推斷攻擊的對策(countermeasure)。
正規化(Normalization)
數據庫規範化的最初目的是減少數據重複以節省存儲空間並增強數據完整性。
聚合(Aggregation)
數據匯總導致的機密性問題很常見。聚合是指組裝或組合不同的數據單元。這可能是數據處理(尤其是關係數據庫)中的問題。關係數據庫中的授權通常在表或視圖級別上實現。如果基於表授予了授權,則限制對錶記錄的子集的訪問是不可行的。為此,應使用表記錄子集的視圖。
聚合功能(Aggregate Functions)
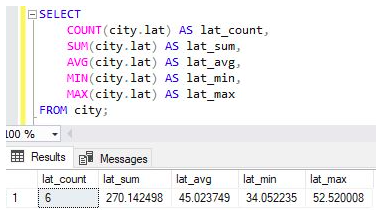
SQL,Excel和其他軟件提供了所謂的集合函數,例如Sum(),Average(),Count(),Max()和Min()等。這些函數正在處理“一組數據, ”而不是“單個數據記錄”,因此由於“聚合”而導致數據洩露。
您需要了解SQL查詢以實現Alice所做的事情,即SELECT MIN(Salary)FROM Payrolls。由於“薪資”表包含所有員工的薪水,因此匯總函數MIN(Salary)將包括所有薪水。SQL查詢的結果直接顯示所有員工中的最低工資;愛麗絲無需推斷或推論得出她的最低工資。
術語(Terminologies)
推論(Inference):從已知信息派生新信息。推論問題是指這樣的事實,即可以在不清除用戶的級別上對導出的信息進行分類。推斷問題是用戶從他們獲取的合法信息中推斷出未經授權的信息。
聚合(Aggregation):處理敏感信息時,組合或合併不同數據單元的結果。以一個敏感度級別聚合數據可能會導致以較高敏感度級別指定總數據。
多重實例化(Polyinstantiation):多重實例化允許一個關係包含具有相同主鍵的多個行;多個實例通過其安全級別進行區分。
參照完整性(Referential integrity):如果所有外鍵都引用現有的主鍵,則數據庫具有參照完整性。
實體完整性(Entity integrity):關係中的元組不能對任何主鍵屬性具有null值。
粒度(Entity integrity):可以限制訪問對象的程度。粒度既可以應用於對像上允許的動作,也可以應用於被允許對對象執行那些動作的用戶。
來源:NIST SP 800-8(已淘汰)
參考
. 學習SQL:聚合函數
資料來源: Wentz Wu QOTD-20201230
 卓建全(Cho,Chien-Chuan)
卓建全(Cho,Chien-Chuan)

 iThome鐵人賽
iThome鐵人賽