X_Data = ['good', 'bad', 'worse', 'so good']
y = [1.0, 0.0, 0.0, 1.0]
count = 0
Encoding = dict()
for words in X_Data:
for char in words:
if char not in Encoding.keys():
Encoding[char] = count+1
count = count+1
X_squence = []
for words in X_Data:
temp = []
for char in words:
temp.append(Encoding[char])
X_squence.append(temp)
# 補數字將長度改成一樣
from tensorflow.keras.preprocessing.sequence import pad_sequences
X = pad_sequences(X_squence, maxlen=8, padding='post', value=0)
import numpy as np
y = np.array(y)
# 建構網路
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, SimpleRNN, Dense
RNN_Model = Sequential()
RNN_Model.add(Embedding(input_dim=11, output_dim=11, input_length=8))
RNN_Model.add(SimpleRNN(30))
RNN_Model.add(Dense(2))
# 訓練模型
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.losses import SparseCategoricalCrossentropy
adam_op = Adam(learning_rate=0.001)
loss_op = SparseCategoricalCrossentropy()
RNN_Model.compile(optimizer=adam_op, loss=loss_op, metrics=['acc'])
RNN_Model.fit(X, y, epochs=30, batch_size=2)
# 預測
np.argmax(RNN_Model.predict(X), axis=-1)
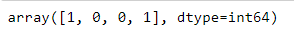
y
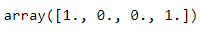
講解一些演算法,ex:爬山演算法,運用程式讓同學了解運作原理。
 aheating0918
aheating0918
