資料是機械學習重要的核心,用於生產的機械學習必須考量大量且快速的資料情境,使用自動化、可擴展的資料分析、驗證以及監控方法相當重要。 TensorFlow Data Validation (TFDV) 為 Google 開源的資料驗證模組,可做為用於生產的機械學習組件之一,也可以融入您在筆記本的研究流程。

圖片來源 TFX
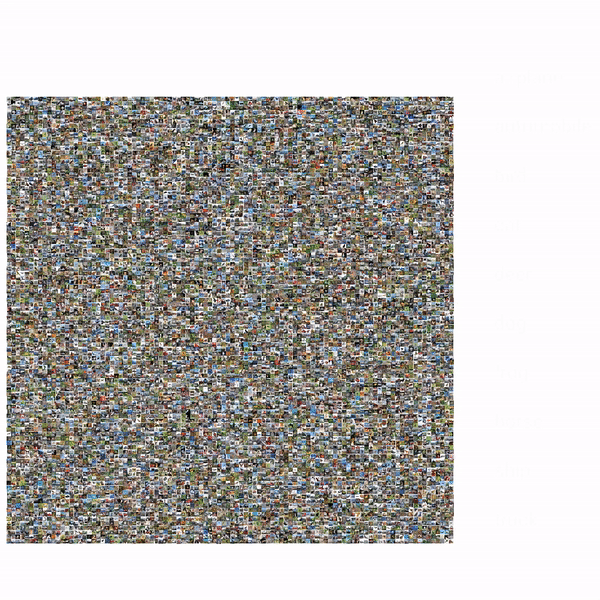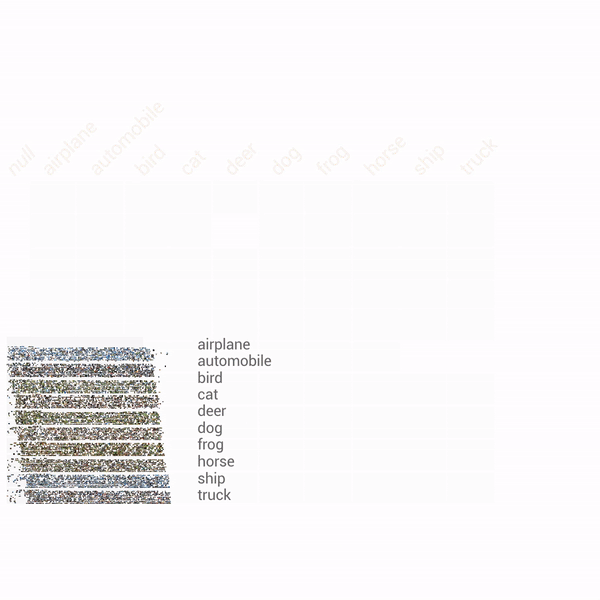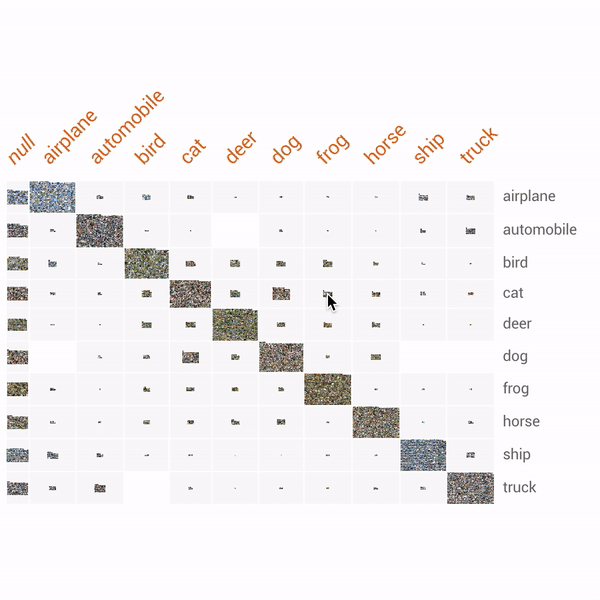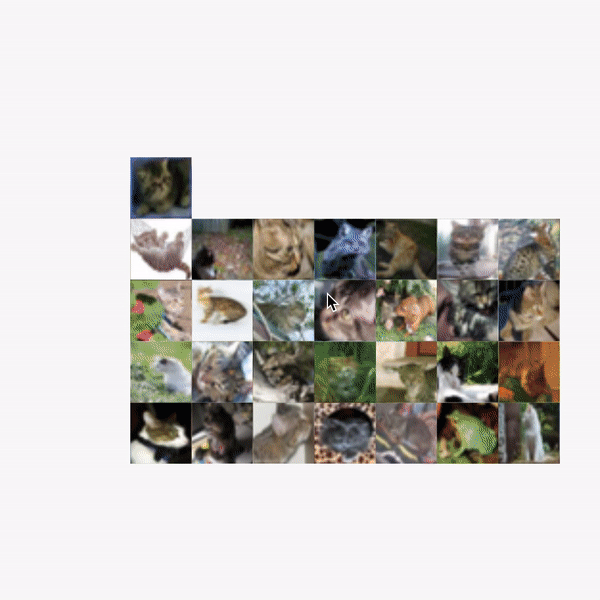
功能介紹引用 TFDV官方教學文件,也提供 Colab 實作範例  可直接執行,您可以相互參照。
可直接執行,您可以相互參照。
tensorflow-data-validation 模組。
!pip install tensorflow-data-validation
csv、DataFrame 與TF Record,變成可用統計數據。
tfdv.generate_statistics_from_csv
tfdv.generate_statistics_from_dataframe
tfdv.generate_statistics_from_tfrecord
tfdv.visualize_statistics()

tfdv.infer_schema
tfdv.display_schema


statisticsserving_stats可檢測訓練服務偏差,previous_statistics可檢測偏移。
tfdv.validate_statistics
tfdv.visualize_statistics(
lhs_statistics=eval_stats,
rhs_statistics=train_stats,
lhs_name='EVAL_DATASET',
rhs_name='TRAIN_DATASET'
)

將徵測到的異常呈現及說明,輕鬆寫意。
tfdv.display_anomalies
# Check eval data for errors by validating the eval data stats using the previously inferred schema.
anomalies = tfdv.validate_statistics(statistics=eval_stats, schema=schema)
tfdv.display_anomalies(anomalies)

在 Google TFDV 說明簡報中,您可以看到左方為 資料與 Schema,右方紅字為對照 Schema 的差異。
您可以依您的 Domain Knowledge 決定對異常採取的措施。如果異常表明數據錯誤,則應修復底層數據。否則,您可以更新納入 Schema 以納入。
TFDV 的異常處理參數請見官方文件,異常可能歸類於資料型態的問題、未知 Domain 出現、超過數值邊界值範圍。
如果已經發現異常 Domain 處理,官方範例可以參考,其一是放寬異常特徵的看法,其二將該特徵納入Domain。
# Relax the minimum fraction of values that must come from the domain for feature company.
company = tfdv.get_feature(schema, 'company')
company.distribution_constraints.min_domain_mass = 0.9
# Add new value to the domain of feature payment_type.
payment_type_domain = tfdv.get_domain(schema, 'payment_type')
payment_type_domain.value.append('Prcard')
另外您也可以透過Pandas操作DataFrame的方式整理資料,像是df.dropna()、df=df[df['some_column']<100]進行篩選與過濾。Pandas 快速指引可以參閱10分鐘的Pandas入門-繁中版。
再次檢視異常處理情形:
# Validate eval stats after updating the schema
updated_anomalies = tfdv.validate_statistics(eval_stats, schema)
tfdv.display_anomalies(updated_anomalies)

# 對 payment_type 特徵加入 skew 比對
payment_type = tfdv.get_feature(
schema,
'payment_type'
)
payment_type.skew_comparator.infinity_norm.threshold = 0.01
# 對 company 特徵增加 drift 比對
company=tfdv.get_feature(
schema,
'company'
)
company.drift_comparator.infinity_norm.threshold = 0.001
skew_anomalies = tfdv.validate_statistics(
train_stats,
schema,
previous_statistics=eval_stats,
serving_statistics=serving_stats
)
tfdv.display_anomalies(skew_anomalies)

schema_file,將schema存為*.pbtxt,完整程式參見官方範例。
tfdv.write_schema_text(schema, schema_file)
在探索式資料分析 EDA 之中, TFDV 可以檢測並輸出調整後的 Schema。在生產流程之中,可以用Schema與生產中的資料統計資訊進行驗證,對比與檢測可能出現的 Data Drift 與 Skew ,並據以修正。
您可以完成持續跨日的追蹤數據,例如有了第1日 schema 與統計資訊,可進行與 t 日的比對。。



