一. 前言
這篇是word2vec的paper,網址:https://arxiv.org/pdf/1301.3781.pdf
其實文字轉向量這件事在很久之前就有許多人在研究,但過去研究的花費時間過高、架構也很複雜,paper中也有提到NNLM(Feedforward Neural Net Language Model)這種方法,於是呢,作者就決定提出一個架構簡單,但又可以表示詞的方法,word2vec就這樣誕生了,他也分成2種方法: CBOW(Continuous Bag-of-Words)與skip-gram。
二. CBOW(Continuous Bag-of-Words)
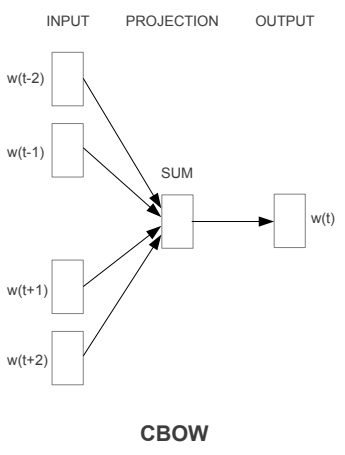
下圖就是CBOW的模型,圖來自原paper,是一個類神經網路的模型,只是只有一層hidden layer,其方法就是利用上下文來預測中間的詞出現的機率是多少,以下圖來說的話可以當成現在有五個詞,利用前兩個詞(w(t-1)跟w(t-2))與後兩個詞(w(t+1)跟w(t+2))來預測中間詞(w(t))出現的機率,輸入及輸出層都是以one-hot representation來表示的,藉由不斷的訓練(SGD以及Backpropagation來調整權重)input到projection的權重,最後這些權重就變成了詞向量。
三. skip-gram
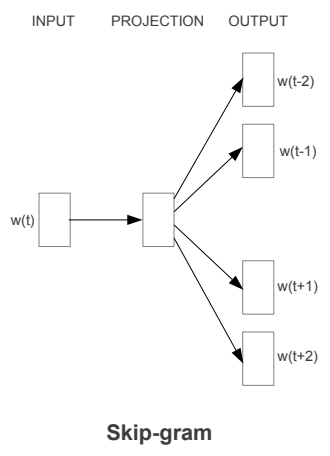
第二個word2vec的模型是skip-gram,架構圖如下圖,其訓練方式與CBOW相同,輸入及輸出層也都是one-hot representation的形式,但整體概念是用中間詞來訓練上下文出現詞的機率,跟CBOW剛好相反。以剛剛的句子“我 今天 很 帥”,就是我用 “今天” 來預測 “我” 及 “很”這2個詞出現的機率,在最大化機率的過程中也訓練了從input層到到projection層的權重。
四. 優缺點
通常來說,cbow的方式需預測的詞較少,花費的時間較短,訓練時的詞向量較為平均; 而skip-gram預測的詞較多,但花費的時間長,遇到僻詞出現次數較少時,多次的訓練會使詞向量相對的更加準確。
明天會以gensim來實作word2vec

