一. 介紹
Bert全名為Bidirectional Encoder Representation from Transformers,目前Bert與其他以BERT為基底的模型都還是目前的主流模型之一,各位可以參考SQUAD2.0: https://rajpurkar.github.io/SQuAD-explorer/ 有需多為BERT衍生的模型所以BERT是非常重要重要的工具
二. 模型架構
從英文全名來看,BERT就是Transformer的encoder,他就是下圖self-attention疊了12層的樣子: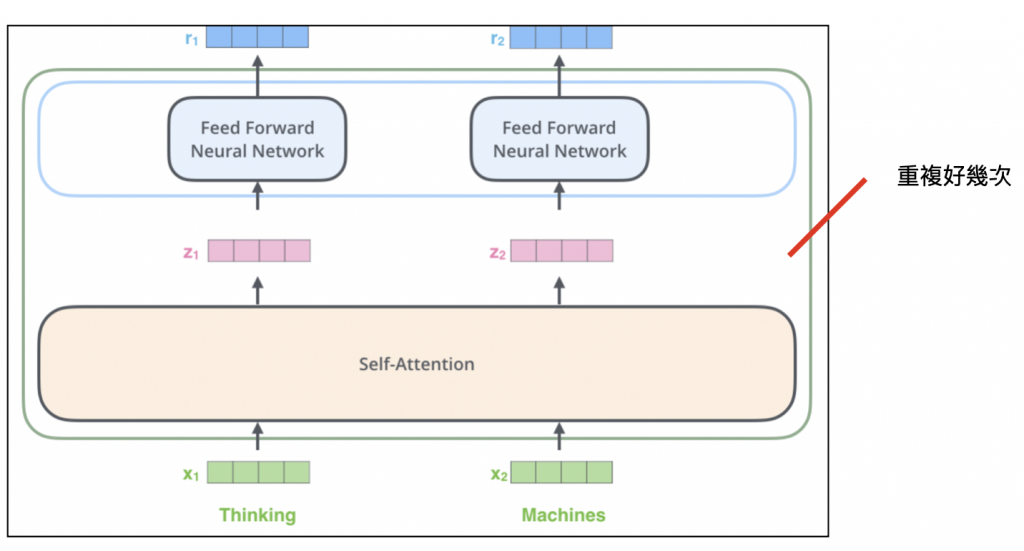
模型架構就是跟transformer的encoder一樣,BERT的目的就是為了得到好的句子編碼~~
三. 訓練
接者來說說他的訓練原理,他分為2個訓練:
這個任務可以看成'克漏字填充',隨機將一個句字中的一些詞轉換成[Mask]這個標記,但這些標記為[MASK]的詞大約佔10%。
以一個句子來說,如果原句是"我今天很帥",那麼可能會調整成 : 80%的 "我今天很[Mask]" + 10%的 "我今天很帥" + 10%的 "我今天很情",藉由調整不同頻率的句子,讓BERT學會了解句子。
在這個訓練任務中,主要是讓 BERT 去理解 NLI (蘊含推理,判斷上下句間是否為相連)任務,因此需要輸入前後不同的兩句。像是'海水退了'與'就知道誰沒穿褲子',這2句就是相連的句子~~
以上就是BERT簡單的介紹,明天會開始實作~~
((我知道最近內容真的很少QQ,未來會慢慢補齊的

