經過不懈的努力!我們終於來到此次專案時做的最後一個章節,前三個部分我們已經算是達成任務,成功訓練出一個模型來做瑕疵的檢測,而今天呢?算是一個追求更完美的步驟,讓模型"好,還要更好"!
先來看看我們將結果上傳至平台後的得分。
準確度是我們還可以接受的範圍,但模型大小、載入時間以及推論速度似乎還有一些進步空間,今天我們就以這兩方面來做加強。
這是一個最直接的方法,但如果要維持其速度以及尺寸的話,盡量也選擇一些輕量的模型,像是MobileNetV2, MobileNetV3, SqueezeNet...等,或許可以發現比較適合的模型。
我們在前面的章節也介紹過動態學習率的好處,再使用過後我們成功讓模型的準確度提升了0.5個百分點,程式如下:
#動態學習率
from tensorflow.keras.callbacks import ReduceLROnPlateau
LR_function=ReduceLROnPlateau(monitor='val_acc',
patience=5,
# 5 epochs 內acc沒下降就要調整LR
verbose=1,
factor=0.5,
# LR降為0.5
min_lr=0.00001
# 最小 LR 到0.00001就不再下降
)
然後把它放進Callbacks裡面在訓練時執行
callbacks_list = [LR_function]
這是減少模型參數、縮小模型相當實用的辦法,我們在DAY23也有介紹過,程式碼實現如下:
pip install -q tensorflow-model-optimization
import tensorflow_model_optimization as tfmot
prune_low_magnitude = tfmot.sparsity.keras.prune_low_magnitude
batch_size = 16
epochs = 3
validation_split = 0.2
num_images = train.shape[0] * (1 - validation_split)
end_step = np.ceil(num_images / batch_size).astype(np.int32) * epochs
# Define model for pruning.
pruning_params = {
'pruning_schedule': tfmot.sparsity.keras.PolynomialDecay(initial_sparsity=0.50,
final_sparsity=0.80,
begin_step=0,
end_step=end_step)
}
model=tf.keras.applications.MobileNet(weights='imagenet',input_shape=(128, 128, 3), include_top=False)
x = layers.GlobalAveragePooling2D()(model.output)
outputs = layers.Dense(6, activation="softmax")(x)
model=Model(inputs=model.inputs,outputs=outputs)
#Pruning
model_for_pruning = prune_low_magnitude(model, **pruning_params)
修剪成功後,我們在將模型拿去訓練,就大功告成了,我們來看看修剪後的成果: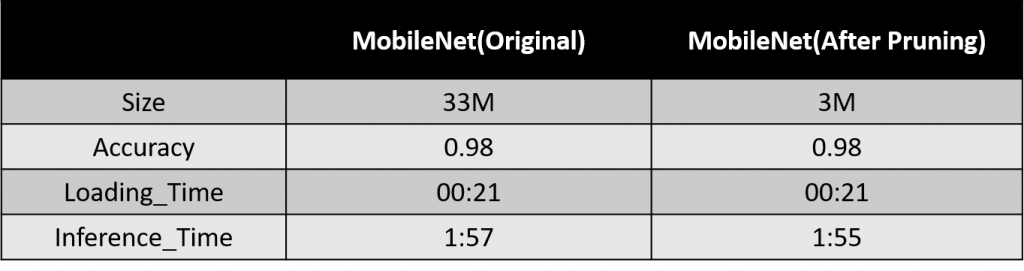
可以看到在準確率不變的狀況下,我們成功將模型縮小成10倍。
先釐清一個觀念,你們覺得讓模型"一次預測1張照片,跑五百次預測500張",跟"一次預測10張照片,跑50次預測500張"是一樣快的嗎?答案是否定的,讓我們看看再更改了預測方式之後,推論速度進步了多少。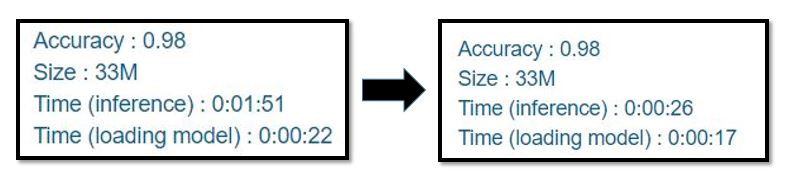
速度上可以說是差得非常多,將近一分半的時間,透過這個實驗我們知道,盡可能讓模型一次預測多張照片,效果會比一次預測一張來的好。
我們在儲存模型時通常會存為.h5的檔案,這個檔案會包括模型的架構以及權重,但我們也可以試著把架構與權重分開儲存,來看看會發生什麼結果:
#儲存架構
from keras.models import model_from_json
json_string = model.to_json()
with open("model.config", "w") as text_file:
text_file.write(json_string)
#儲存權重
model.save_weights("model_weight.h5")
執行上方的程式碼後我們會得到兩種檔案,一種是模型的架構,另一種是權重,見下圖:
經實驗,分開儲存後得到的模型會比原來的小,載入時間也會提升,下圖為比較:
以上是這次比賽中我們用來優化模型的一些方法,其實在用了這些方法後我們已經可以得到一個不錯的分數了,當然如果想要再進一步的話,也還有許多方法等著你們去發掘、去嘗試,小編就擔任一個引路人的腳色,希望能有拋磚引玉的效果,我們這次的專案時做就到這邊告一段落,希望大家的學習都有收穫。


 iThome鐵人賽
iThome鐵人賽