那我們要開始著手處理我們的資料集了,今天會先做資料前處理的部分,其實不管是機器學習或是深度學習,只要是資料分析,我們的處理步驟都大同小異,都是先了解資料的特性,進行一些前處理,再去選擇模型來訓練,那我們就開始吧!
# 雲端執行須執行這行,取得權限
from google.colab import drive
drive.mount('/content/drive')
# 雲端執行須執行這行,變更環境路徑
os.chdir("//content/drive/MyDrive/AOI")
os.getcwd()
我們要讀取的資料有兩個,一個是train.csv,裡面包含了圖片的ID及Label,另一個是圖片檔。
data_path = "/content/drive/MyDrive/AOI"
train_list = pd.read_csv(os.path.join(data_path, "train.csv"), index_col=False)
data_path = "/content/drive/MyDrive/AOI/train_images" #路徑掛載到存放圖片的資料夾路徑
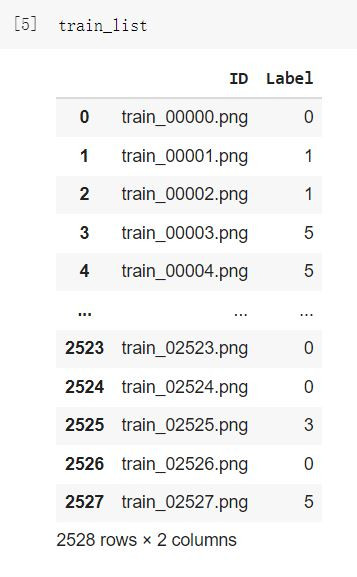
img = cv2.imread(os.path.join(data_path, train_list.loc[0, "ID"]))
print(f"image shape: {img.shape}")
print(f"data type: {img.dtype}")
print(f"min: {img.min()}, max: {img.max()}")
plt.imshow(img)
plt.show()
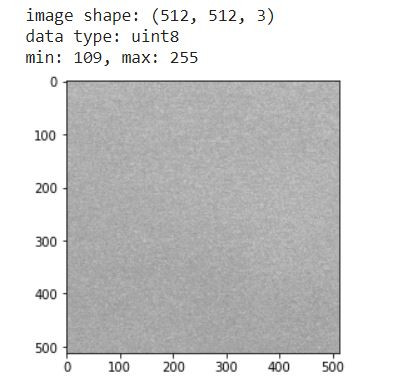
normal_list = train_list[train_list["Label"]==0]["ID"].values
void_list = train_list[train_list["Label"]==1]["ID"].values
horizontal_defect_list = train_list[train_list["Label"]==2]["ID"].values
vertical_defect_list = train_list[train_list["Label"]==3]["ID"].values
edge_defect_list = train_list[train_list["Label"]==4]["ID"].values
particle_list = train_list[train_list["Label"]==5]["ID"].values
label=[normal_list,void_list,horizontal_defect_list,vertical_defect_list,edge_defect_list,particle_list]
plt.figure(figsize=(12, 6))
for i in range(6):
plt.subplot(2, 3, i+1)
img = cv2.imread(os.path.join(data_path, label[i][i]),0)
plt.imshow(img,cmap='gray')
plt.axis("off")
plt.title(f"img shape: {img.shape}")
plt.suptitle(f"Variety of samples", fontsize=12)
plt.show()
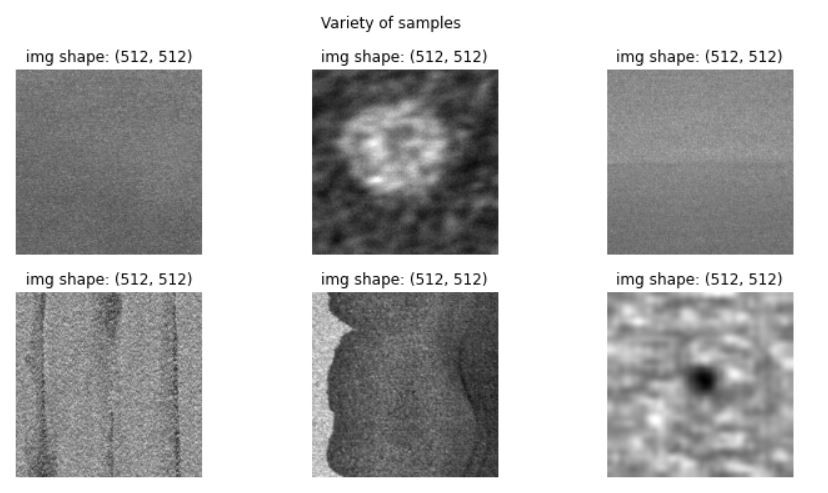
plt.figure(figsize=(12, 6))
for i in range(6):
plt.subplot(2, 3, i+1)
img = cv2.imread(os.path.join(data_path, label[i][i]),0)
plt.hist(img.reshape(-1), bins=50)
plt.xlabel("pixel value", fontsize=7)
plt.ylabel("Frequency", fontsize=7)
plt.suptitle(f"Variety of samples", fontsize=12)
plt.show()
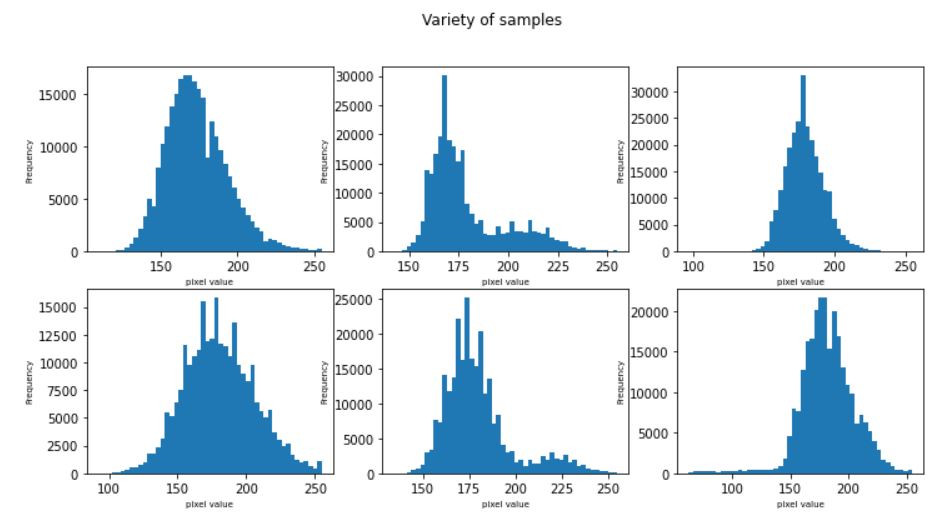
還記得我們前面提過的值方圖均衡化(Histogram Equalization)和局部均衡化(createCLAHE)嗎?我們來試試效果在這邊如何。
#Histogram Equalization
equalize_img = cv2.equalizeHist(img)
plt.figure(figsize=(14, 9))
plt.subplot(2, 2, 1)
plt.imshow(img, cmap="gray")
plt.axis("off")
plt.title(f"Original")
plt.subplot(2, 2, 2)
plt.imshow(equalize_img, cmap="gray")
plt.axis("off")
plt.title(f"Histogram")
plt.subplot(2, 2, 3)
plt.hist(img.reshape(-1), bins=50)
plt.xlabel("pixel value", fontsize=14)
plt.ylabel("Frequency", fontsize=14)
plt.subplot(2, 2, 4)
plt.hist(equalize_img.reshape(-1), bins=50)
plt.xlabel("pixel value", fontsize=14)
plt.ylabel("Frequency", fontsize=14)
plt.show()
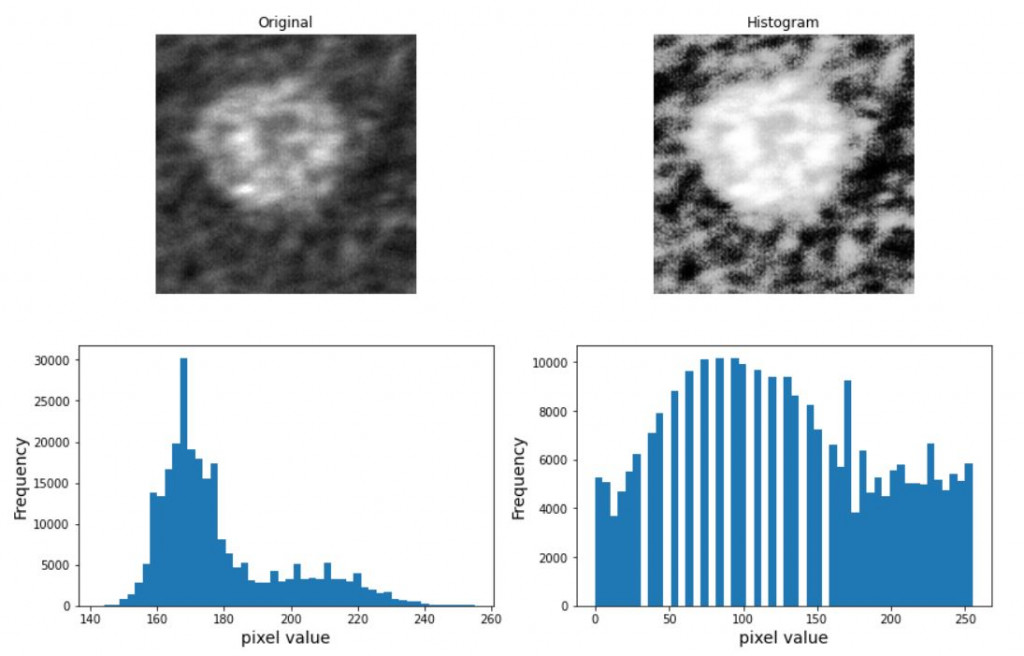
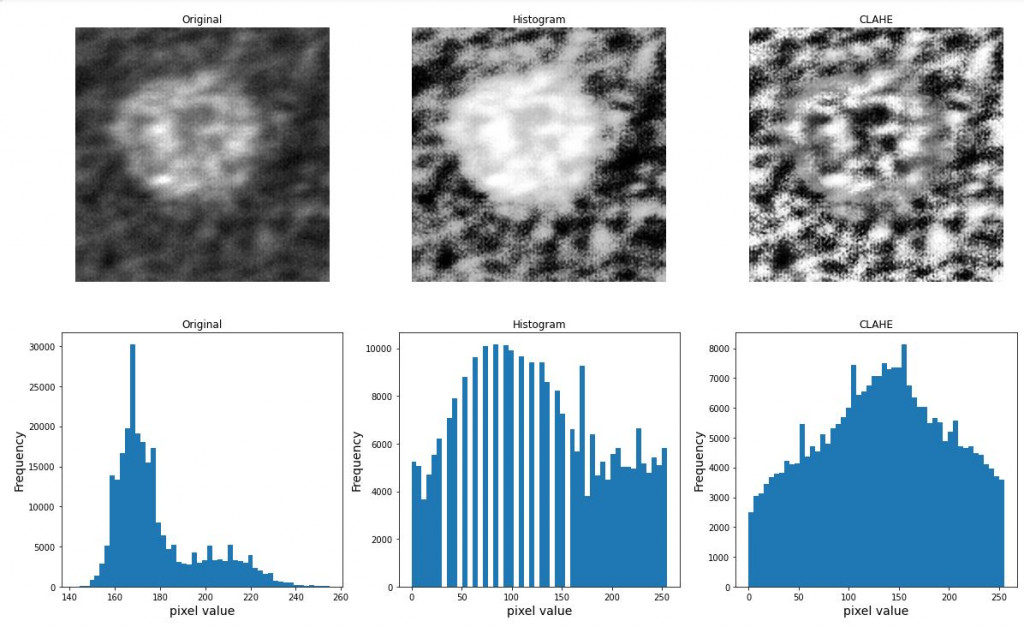
#CreateCLAHE-局部均衡化
clahe = cv2.createCLAHE()
clahe_img = clahe.apply(img)
plt.figure(figsize=(20, 12))
plt.subplot(2, 3, 1)
plt.imshow(img, cmap="gray")
plt.axis("off")
plt.title(f"Original")
plt.subplot(2, 3, 2)
plt.imshow(equalize_img, cmap="gray")
plt.axis("off")
plt.title(f"Histogram")
plt.subplot(2, 3, 3)
plt.imshow(clahe_img, cmap="gray")
plt.axis("off")
plt.title(f"CLAHE")
plt.subplot(2, 3, 4)
plt.hist(img.reshape(-1), bins=50)
plt.xlabel("pixel value", fontsize=14)
plt.ylabel("Frequency", fontsize=14)
plt.title(f"Original")
plt.subplot(2, 3, 5)
plt.hist(equalize_img.reshape(-1), bins=50)
plt.xlabel("pixel value", fontsize=14)
plt.ylabel("Frequency", fontsize=14)
plt.title(f"Histogram")
plt.subplot(2, 3, 6)
plt.hist(clahe_img.reshape(-1), bins=50)
plt.xlabel("pixel value", fontsize=14)
plt.ylabel("Frequency", fontsize=14)
plt.title(f"CLAHE")
plt.show()
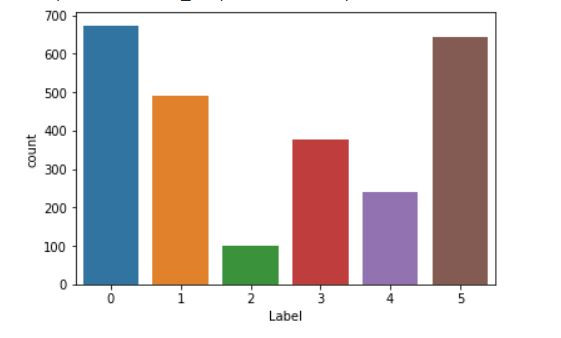
再切割資料前我們也順便看一下資料的分布狀況
train_list["Label"].value_counts()
sns.countplot('Label', data=train_list)
#切分資料
from sklearn.model_selection import train_test_split
train,valid= train_test_split(train_list,test_size=0.2,random_state=666)
#重製index
train.reset_index(drop=True,inplace=True)
valid.reset_index(drop=True,inplace=True)
#改變Label型態
train["Label"]=train["Label"].astype("str")
valid["Label"]=valid["Label"].astype("str")
上圖我們發現資料分布好像不是很平均,2類跟4類的樣本數有點偏少,這邊我使用的方法是增加較重懲罰職權重給樣本數少的類別,讓訓練的時候模型會更加注重這些樣本,藉此來達到平衡的目的。
unique, counts = np.unique(y_train.values, return_counts=True)
print("unique ", unique)
print("counts: ", counts)
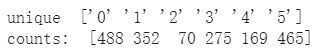
#adjust weight
from sklearn.utils.class_weight import compute_class_weight
class_weights = compute_class_weight('balanced',unique,y_train)
print(class_weights)
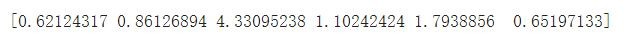 .
.
前處理的部分我們就到這邊告一段落,稍微了解了一下圖片的特性,下一章節我們就要開始做資料增強以及訓練模型了,加油,我們已經完成一半了!

