儘管都是模型,但預測模型目的在於預測未來,所以開發方式也會和描述型模型有所差異。
起始階段要確認的事情跟之前差不多。
商業意圖是否明確:商業意圖不是指明確的需求,而是想利用這個預測模型做什麼。例如「想預測使用者會不會點擊」,這只能算是需求;「想透過提高使用者點擊率提高使用者觀看數」這樣才是比較完整的商業意圖。因為使用者可能會提出無法滿足商業意圖的需求,這時候做了也是白做,所以最重要的事情就是確認商業意圖。
需求:不管預測人數、預測點擊、預測營收都是單純的預測目標。如果商業意圖還不明確的話,就還需要在回到上一步多著墨,至少要需要變成一個比較明確方向的問題,才有辦法往下走。
資料來源是否足夠:這關乎到「能不能回答問題」,那如何判斷需求可否被預測?很多人(特別是老闆)會覺得模型無所不能,什麼都可以預測。儘管現在預測模型種類繁多,但標準很簡單 - 「有標注的資料是否夠多?」現在大多數的預測模型都是需要 ground true(亦即標準答案),來做為訓練資料,如果一個問題手上有的標注資料不夠、或是這個問題根本無法很好的被標注,那就表示這個問題做起來風險很高(或做不出來)。
預測模型在設計上就有很多選擇了,最主要就是要區別到底要預測什麼
接著就是照一些小細節去選擇對應的模型。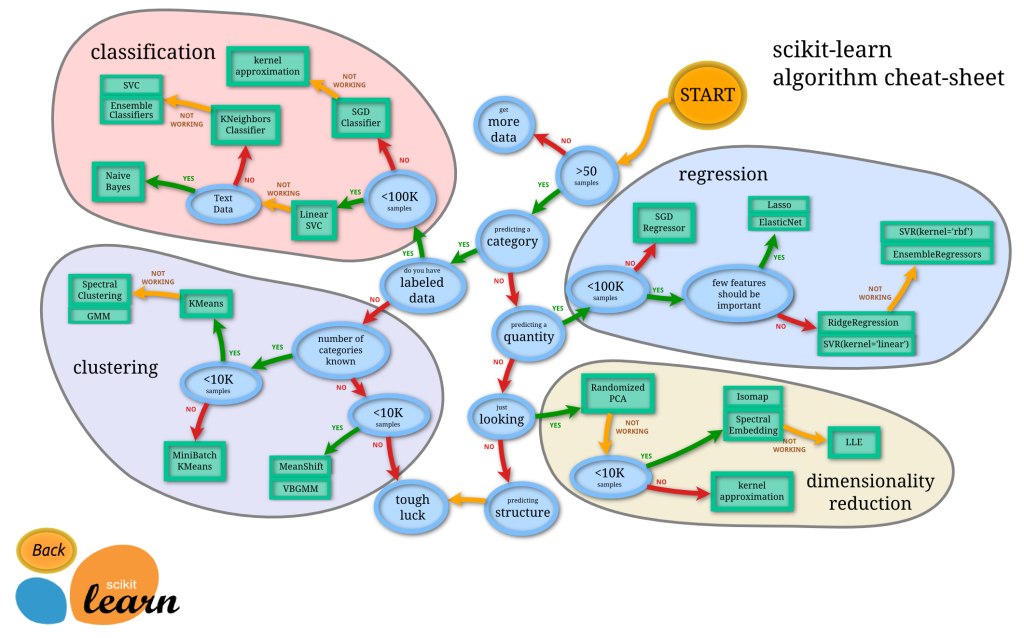
(https://bigdataanalyticsnews.com/machine-learning-with-python-a-revolution-in-the-field-of-data-analytics/)
如果是 Deep Learning 的話,也是根據需求來選擇相應的結構,像是
影片/影像辨識:走 CNN 路線
聲音/文字辨識:走 LSTM 路線
對抗訓練:走 GAN 路線
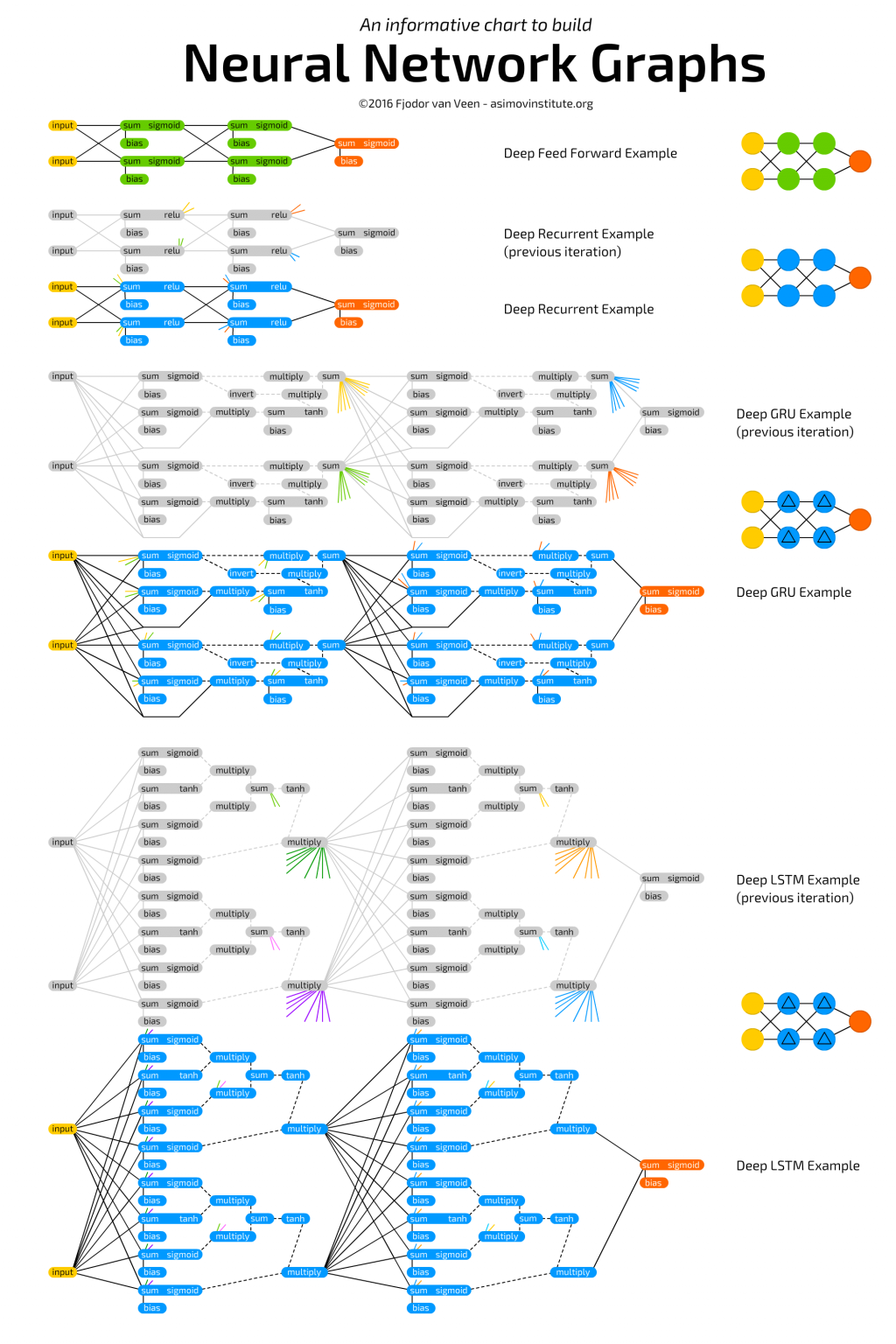
(https://www.techwebspace.com/9-ways-to-become-the-macgyver-of-deep-learning/)
總之細節很多,就有待各位大大來補充。
在開發預測模型上,步驟就比較複雜。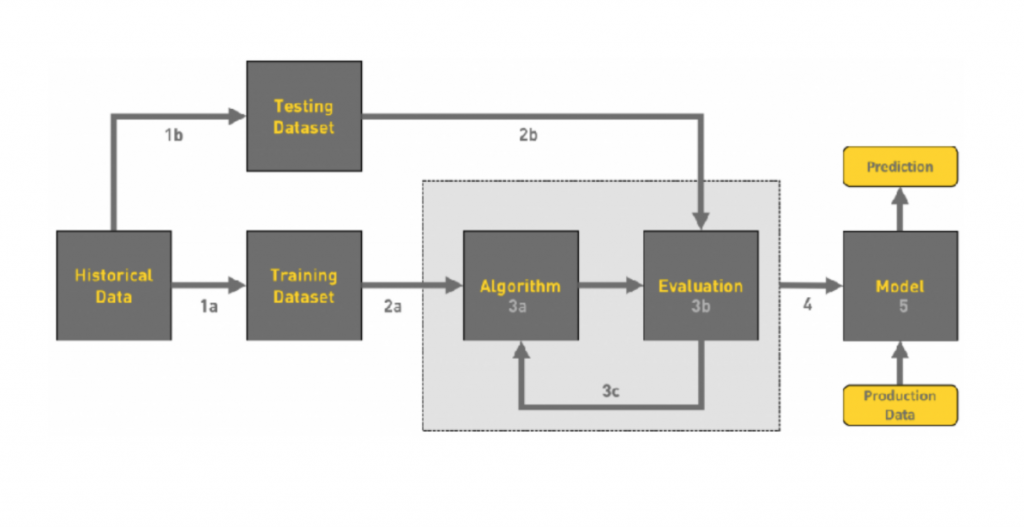
在做預測模型時,通常會先使用過去的資料,接著將資料分為 Traning Set(1a) 和 Testing Set(1b)。
接著會使用 Training Set 代入演算法來訓練模型(2a)。接著我們會用訓練好的模型來做資料驗證(有些套件會將Training Dataset 分成 Training Set 和 Evaluation Set(3b)),透過這樣的過程來優化演算法的參數。並透過之前分出去的 Testing Set 來驗證不同演算法的優劣。
最後我們會選出最好的模型進入正式環境(4,5),並用來預測正式資料。
ML 模型部署部分是最近最熱門的題目 - MLOps 值得用一整篇來寫。

