模型當然也有純理論的介紹方法,但實務上是很難單談模型的,今天這篇會介紹過去常用、也滿泛用的不需要使用機器模型的分析手法以及對應的商業需求。
(https://classlesdemocracy.blogspot.com/2018/07/personal-profile-sample.html)
整個資料分析的報告架構就如同說故事般,透過數據引導聽眾建立對於消費者的想像。故事的第一頁通常會描寫時間季節,寫到人物時也只會初步描述人物的年齡長相,資料分析的第一個環節也由這邊展開......
以消費者資料庫為例,分析之前先確認要分析的資料期間,是最近一年有消費者消費者? 還是歷史以來的消費者? 以第一次接觸資料來說,可以先分析歷史以來的消費者以及最近一年的消費者,好處是可以知道整體的消費者樣貌,並且從整體以及今年的資料比較中了解消費者有沒有轉變。
確定好分析的時間後,接著就會就各個人口變項觀察消費者的樣貌。通常我們在描述一個人的樣貌的時候,可能會說黑色短髮、身高160公分、體重60公斤、30歲男性上班族等等特性,然後透過每個人對於這些特性的了解,我們可以大致想像口中描述的人的樣貌,但這是對一個人的描述。資料庫分析或是統計分析,也是在描述消費者樣貌,但是不同的是分析對象並非"單一個人",而是"一群人"。如果我要介紹我辦公室的同事,或許有辦法跟你一一介紹,但是如果我需要介紹幾百人、幾千人、甚至幾萬人的時候,我就不可能用這種一一介紹的方式,而是會用組成結構的方式來描述這群人。例如,這一群人平均身高165公分,平均70公斤,有一半男生、一半女生。你可以發現,我所介紹的特性與剛剛介紹一個人的時候並無不同,只是我所描述的並非單一個人的狀況,而改用一些所謂"統計"術語(例如平均、百分比)來介紹這"一群人"的人狀況。以下我們將介紹兩種最常用來描述消費者輪廓的統計術語。
大部分的人對於平均數的想像其實更貼近統計上"眾數"的概念,而非真正的平均數。例如當我說A團體平均身高160公分的時候,腦海中會直覺的想像這一群人大部分都是在160公分上下。但是如果有個B團體裡面有十個人身高180公分,十個人身高140公分,這個B團體平均身高也是160公分。或是如果有個C團體,一個人身高200,另外幾個人身高都150的時候,C團體平均身高也會是160公分。那如果我們直接說A、B、C三個團體平均身高都160公分時,會容易誤導聽故事的人對於這三個團體的想像。因為一般人對於統計的不熟悉,以及誤用,所以研究者更需要注意這種情形,來選擇適合的描述方式,避免誤導聽眾。
但是在描述百分比的時候,會建議標一下實際數值在旁邊以供參考,然後選擇想要強調的重點來使用百分比或實際數值。比如說:"我們家會員有10萬人每年只消費一次",這是個聽起來很大的數字,但是說不定這10萬每年只消費一次的會員只占整體會員的0.1%,這時候就可以不用強調100萬這個實際數字。又或者"我們有30%的消費者不喜歡紅色的上衣",但是這個調查的母體只是個總共10人的焦點座談會,這時候就可以用實際人數來代替百分比。兩者的使用單純視需求而定。
人口描述是最簡單,但是也最基本、最重要的分析。透過人口描述可以初步了解、觀察消費者的樣貌,提供想像的基礎,事後其他的分析都是從這些分析中延伸出來。當然,描述的方法當然不只有平均數和百分比而已,要用什麼統計值來描述資料純粹就資料的性質和需求而定。雖然我們常說數字不會說謊,但是選擇要使用何種數字以及何種解釋方式的,終究是人,這點我認為才是研究人員最為重要,也最難拿捏的地方。
(https://17growth.net/pareto-principle/)
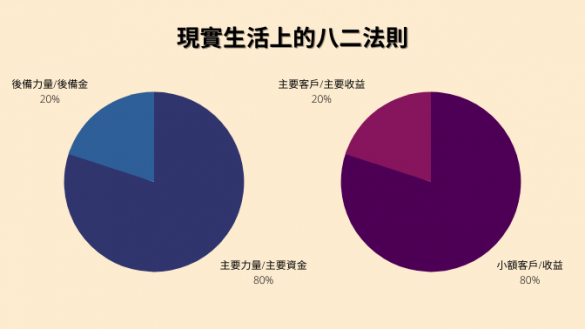
有天老總提了個要求,希望重新設定VP客戶分群,希望將客戶分成幾群來擬定行銷策略。CRM分析一個很重要的精神就是幫客戶分群,於是這個工作理所當然地落到我們的頭上。一般我們都會利用客戶的貢獻程度來將客戶分群,但是傳統上到底要切成幾群,或是要怎麼分一直沒有個依據(通常是依據直覺),所以這次我們就利用很紅的八二法則來將客戶分群。
八二法則又稱為80/20或是帕雷托法則(資料來源http://zh.wikipedia.org/zh-tw/%E5%B8%95%E9%9B%B7%E6%89%98%E6%B3%95%E5%88%99),簡單來說就是20%的客戶貢獻80%的業績,既然大部分的業績都是少數客戶創造的,他們自然可以稱之為品牌的VIP,享有特別的待遇。
80/20法則的概念非常簡單,但是不確定適不適用於我們公司,是我們就分別計算三年每個客戶的消費金額,分別計算人數以及消費金額的百分位數,觀察消費額第80th的金額落在累積人數中的哪個位置,就知道多少消費者創造80%的業績。以我們公司來說,大約是25%的消費者可以創造80%的業績,雖然不是準確的80/20,但是也差不了多少,而且三年的比例也都差不多,可見我們公司大約是80/25的狀況。
八二法則將客戶分成兩塊之後,我們想再進一步做更細緻的分層,於是另外觀察前百分之一的消費者貢獻的比例以及前50%消費者的貢獻比例(分別貢獻了45%和90%,社會真是不公平不是嗎 ?)如此我們就順利將消費者切成四塊,並且分別得知人數比例以及貢獻程度,之後我們就能依照不同的客群來擬訂行銷策略。
客戶分層是每家廠商都會做的策略,但是在切消費族群的時候是如果單純依靠經驗(直覺)很容易會發生誤判,如果能配合CRM資料就能跟精準的了解每個消費族群的界線,對於客戶分群或是行銷策略都能更貼近實際的狀況。

(http://www.whatlauralovesuk.com/2015/12/instagram-tags-this-december.html)
DATA MINING 最重要的觀念也是最常用的功能就是集群(Cluster)和關聯(Correlations)。在分析資料時,可以透過消費者(或產品)不同的特性來加以集群或測量關聯,例如 35-44 歲消費者的消費模式類似的分群,或年紀越高購衣頻次越高這樣的關聯分析。集群或關聯本身操作都很容易,難的事前的準備工作,也就是將消費者(或產品)標上不同的特性。能蒐集的特性越多,能分析的東西也就越多。
消費者的特性通常在資料庫開始就設定好了,例如性別、年齡、消費次數、最近消費日期等等,當然我們也可以透過POS系統計算出一些更詳細的消費者屬性,例如購物週期、購物類別等等。但是另外一些人格特質、生活風格甚至媒體使用行為,或其他產品使用行為,就難以從資料庫中挖掘。這時候可以透過另外的調查,適度地做些資料 fusion(資料融合),來取得會員資料庫中沒有的資料,以便做更多的分析。不過 data fusion 是另外一門學問,將來也會開專文來說明。
而產品的特性,除了一些基本的重量、尺寸外,其他難以量化的特性,例如風格、設計元素,就要用 TAG 的方式來加以建立了。TAG直譯為標籤,也就是用文字化的方式(質性)的方式來說明產品特性,並切成一個個分開獨立的元素。例如我們將一件褲子,除了它的材質、尺寸外,另外加上幾個標籤像是:獨立的、叛逆的、風格強烈的、歐洲風、花紋。如此一來我們就有更多的變項能夠分析消費者的購買行為,比如說某個或某類的消費者,都很常購買具備「狂野」TAG 的服飾,未來在推薦上或是商品組合上,就能更精準地將具有狂野特性的服飾推薦給消費者。
很經典的例子就是 NETFIX,他們之所以能快速掌握消費者喜好的節目,就是在每個影集掛上成堆的 TAG,當消費者看了幾部影集之後,就能透過 TAG 之間的關聯性,推斷使用者喜愛的電影、電視風格,在尋找有相同 TAG 元素的影集推薦給消費者,造成消費者的高黏著性和收視率。
TAG 的建立可以是封閉式的--如讓產品設計者登錄 TAG;或是開放的--讓消費者自由的添加新的TAG。前者的優點是容易管理,後者的優點是更貼近消費者的使用概念。TAG的用途在於將原本難以量化的產品特性變成一個個獨立可以分析的元素,當抽象的元素變成可分析的變項後,DATA MINING 就可以介入發揮其效用。
很多人在談感情的時候,常常因為愛,所以付出許多;而通常付出越多,這份感情也更珍貴,也越捨不得放棄這段感情。這是基於人們本性上對於損失的厭惡(或者可說是沉沒成本謬誤),所以當我投入越多的金錢或情感,這個關係也相對更為重要。而消費者與品牌的關係,是不是也會有這樣的聯結呢?
為了證明這件事情,我們將消費者在品牌的消費當成消費者的成本,以是否繼續購買來觀察消費者是否維持或放棄這段關係,目的是想要知道是否消費者投入越多,維持關係(繼續在品牌消費)的機率也就越高。
這個問題對於行銷相當關鍵,一般來說,開發新客戶的成本是維繫舊客戶的5倍。留住越多舊客戶,相對來說也節省了相當多的開發客戶成本。如果我們知道當消費者投入越多,留住的機率也越高時,我們就可以透過各種行銷方案吸引消費者達到留住的消費門檻,來降低客戶的流失率。
所以我們要做的事情有兩個。
實作上我是以第一年的消費來做區分,來觀察第一年各累積消費的客戶在第二年持續消費(或流失)的機率。結果發現,當消費者的年消費越高,次年流失的機率越低;除此之外,也有邊際效益遞減的情況出現。也就是說,當消費者的年消費從零開始增加時,能夠大幅增加隔年繼續消費的機率,但是這個效益會逐漸減少,當消費者消費更多時,隔年繼續消費的機率不再有明顯的提高。如此一來我們就能透過各種不同的行銷方案來有效提升消費者的品牌忠誠度,並且可以事先估計消費者明年持續消費的機率。
BIG DATA在行銷研究中其中一個重要應用就是將消費者分群,再依照不同族群的特性擬定不同的行銷策略以達到更精準的行銷策略及更佳的行銷效益。這樣分群 > 擬訂策略 > 效益評估是個標準的行銷研究流程,這篇文章只會提到第一個步驟-分群其中的某種方式而已。
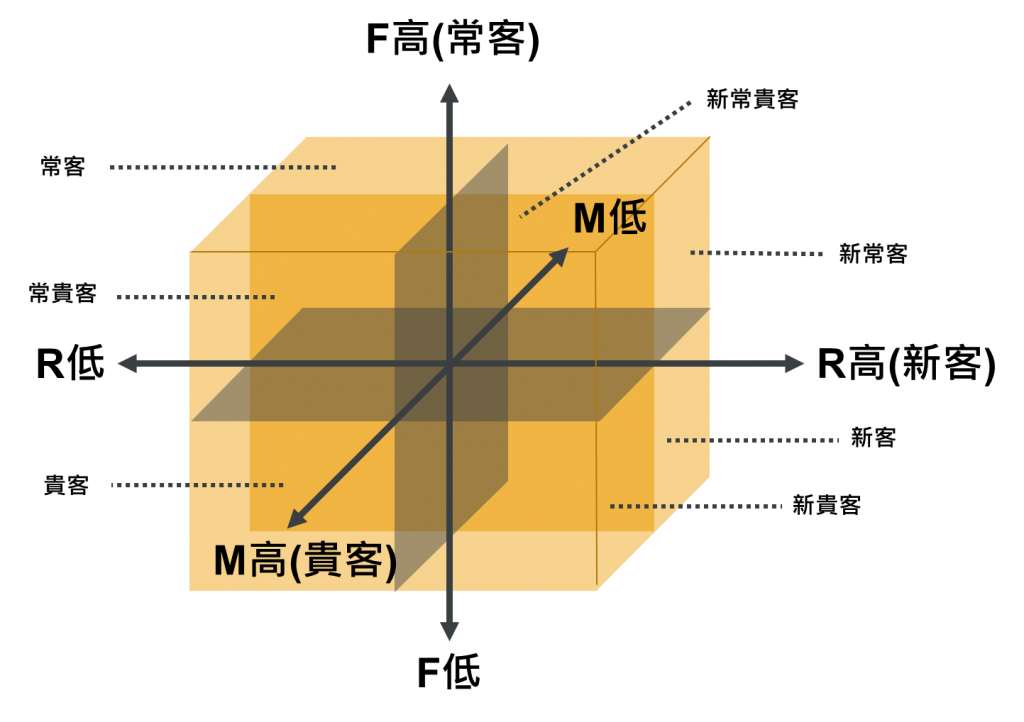
分群的方式千千百百種,可以依照年齡分、性別分、地區分,要依照什麼來分端看需求和消費者特性來說,沒有一定的方式。今天要介紹的RFM模型,是使用R(最近消費日期)、F(消費頻次)、M(消費金額)來做使用者分群,使會員資料庫分析中常用的分析模型。
RFM模型將消費者依R>F>M來區分成不同的族群,做法是先將R分成五等分後,再將每個等分裡的消費者依照F和M再區分成五等分,所以最後會有125個群組。但是實務上我們並不會真正設計125種不同的行銷方案,我們可以簡單的分成4群或9群,再來設計。每一個分群都代表不同類型的消費態度和習慣,也可以依此來設計相對應的行銷方式。
RFM模型的原理很簡單,而分群只是行銷的第一步,如何幫各族群命名,和針對族群設計策略才是重點,這個可以留到後續輔助或自動決策章節來討論。