昨天提到了怎麼開發預測模型,但模型絕對不是開發完就好,後續還有非常多的事情得做。

模型在部署時真的非常麻煩。
Build 出來的模型往往就是一個不能直接執行的檔案(如 .pickle)。這個模型還不像 Java 程式會把所有套件封裝在裡面直接執行就好,要部署 .pickle 檔還需要使用對應的套件才能將模型跑起來;如果給的是 .ipython 或 Ipython Notebook 檔案那就更可怕了(抖)。
這邊有一堆討厭 Ipython Notebook 的人:
I hate notebooks, change my mind
Why I don’t like Jupyter Notebooks
5 reasons why jupyter notebooks suck
雖然難聽,但是還是要說:不會使用套件管理工具的人別出來害人了!!。

總之怎麼讓程式可以從開發人員手上順順利利執行並部署,就是在做 ML(或是任何資料分析程式)最重要的問題。特別是 ML 或分析套件的選用往往因開發人員而異,如果確保不同人的開發環境都能與部署環境一致成了最需要被解決的問題。
通常需要顧到:
Container 技術幫助我們部份解決了這些環境問題,讓開發者可以將應用封裝在 Image 裡面,並將 Image 搬到不同環境上來執行。
除了環境之外,另外一個需要考量的就是模型版本控管的問題。模型如同程式一樣會需要更新,這也可以透過 Image 的技術將不同版本的模型連同環境一同打包,來確保模型在訓練以及部署的環境能夠一致。
評估方式可以大致分為 Offline 和 Online 評估
Offline
泛指非即時的評估方式,除了上線前的評估之外,上線後也可以長期監控模型的指標,觀察有沒有因為時間讓效果減少Model Drift。
Online
指即時的比較模型,讓模型上線前得到小部分的真實資料做金絲雀部署;或是同時間就部署兩到三個模型在線上,即時的比較效果並自動篩選出效果最好的模型。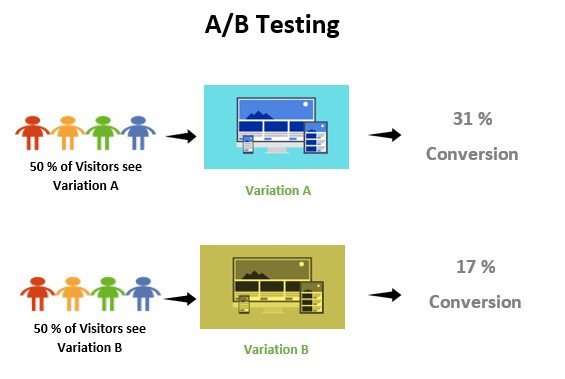
(http://www.adapttransformation.com/devops-toolchain/monitor/ab-testing/)
評估指標的話就會根據模型種類而定。下圖是針對分類模型最常使用的 Confusing Metrics。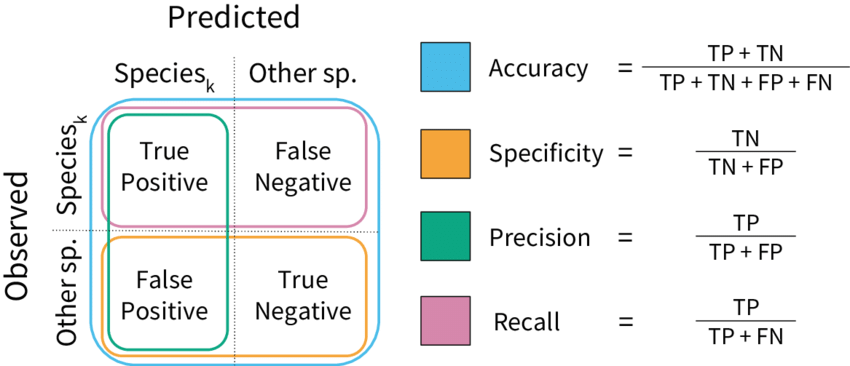
(https://www.researchgate.net/figure/Model-performance-metrics-Visual-representation-of-the-classification-model-metrics_fig1_328148379)
除了每次模型訓練時的迭代之外,在部署後也需要持續的改善。模型都是根據過去的使用者行為來建模及預測,當使用者會一直產生新的行為,即便短期看不出來,但是時間一久,用舊資料訓練的模型會無法解釋新的狀況。通常我們會將改變原因分為:
資料飄移(Data Drift):表示資料的分佈改變。例如原本 OTT 平台都是以男性使用者為主,所以訓練出來的模型會呈現男性的視角。如果因為某些行銷事件湧入大量女性使用者,就會讓平台的預測模型沒辦法對這些新的資料特徵有好的預測。
概念飄移(Concept Drift):表示變項之間的關係改變。當模型的目標變項或是特徵值的概念轉變時,就會發生概念飄移。像是因為 Covid-19 造成行業內天翻地覆的變化,讓許多視訊、遠端軟體出現爆量的使用者,這時候原本的模型也無法派上用場。
由於這些原因,我們會設置監控指標,或是定時的讓模型「學習」新的資料,讓模型保持在比較跟得上時代的狀態。
下圖是非常經典由 Google 發表的「機器學習的技術債」一文,裡面就有提到訓練模型只是在做 ML 系統中的非常非常小一塊。今天我們將介紹模型訓練好之後的事情,最近也非常熱的 MLOps。其熱門程度看今年鐵人賽就知道,有非常多大大在談這個議題,本文只是短短的幫各位大大做個開場白而已:)
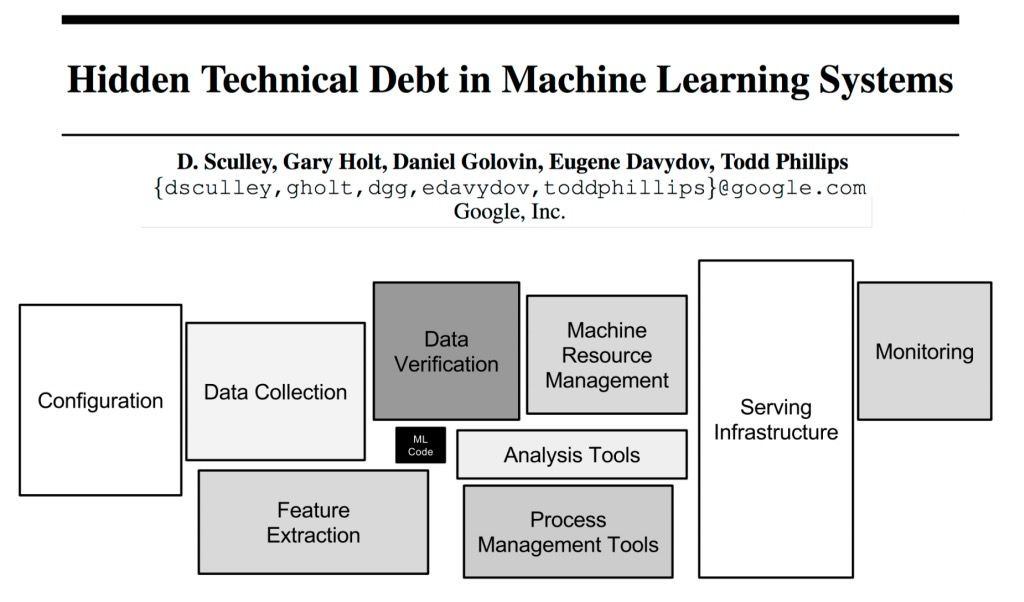
https://papers.nips.cc/paper/2015/file/86df7dcfd896fcaf2674f757a2463eba-Paper.pdf
https://www.docear.org/papers/a_comparative_analysis_of_offline_and_online_evaluations.pdf
https://saikatkumardey.com/predictive-model-performance-offline-and-online-evaluations
https://towardsdatascience.com/model-drift-in-machine-learning-models-8f7e7413b563
http://www.adapttransformation.com/devops-toolchain/monitor/ab-testing/
https://machinelearning101.readthedocs.io/en/latest/_pages/05_model_metrics.html
https://en.wikipedia.org/wiki/Concept_drift
https://zhuanlan.zhihu.com/p/406281023

