本文目標
CPU 的快取被設計來解決記憶體存取過慢的問題。

透過上圖的記憶體階層圖可以發現:
可能會有人問說: 那我幹嘛不加大 Cache 或是 Register 的大小?
答案很簡單: 價格太貴了。
筆者隨手抓了一顆 CPU (Intel i7-8700k) 的資料來看:
Speed: L1 > L2 > L3
根據上面的數據就可以看出 Cache 大小大約是 MB 級,若要將大小擴充到 GB 級甚至是 TB 級,那計算機應該就是有錢人的玩具了。
以目前主流市場來看,記憶體為 GB 級,硬碟為 GB/TB 級。
回到開頭,CPU 中的 Register 數量不多且容量更小,只能供 CPU 做運算,無法再提供其他用途使用(儲存更多記憶體位址或是重要資料)。
若沒有快取的設計,CPU 就需要反覆的讀取記憶體 (RAM)以取得需要的資料。
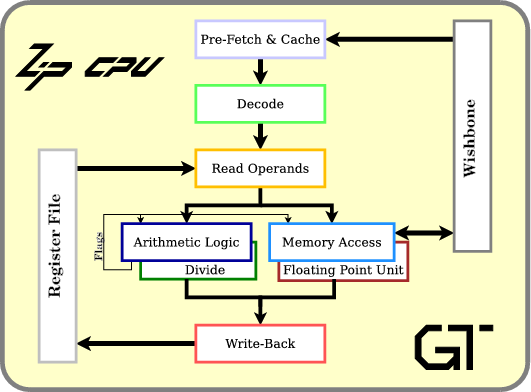
上圖為處理器流水線的設計,方便下文解說。
至於 CPU pipeline 我會額外用一篇文章詳細介紹。
有了 Cache,CPU 就可以在指令執行之前進行 data prefetch,將需要用到的資料事先取出來。不過,也因為 Cache 的成本關係,我們無法將所有資料都保存到 Cache 上。因此,下面也會提到 Cache 如何選擇要存放的資料。
cache line 是 cache 的最小單位。
cache set 則是 cache line 的集合,用程式來表示的話就像是這樣:
cache_set = ["cache_line", "cache_line", "cache_line"]
cache = ["cache_set", "cache_set", "cache_set"]
因為成本上的考量,Cache 的大小都是有限的,所以要設計快取機制來決定哪些 Data 需要被快取。
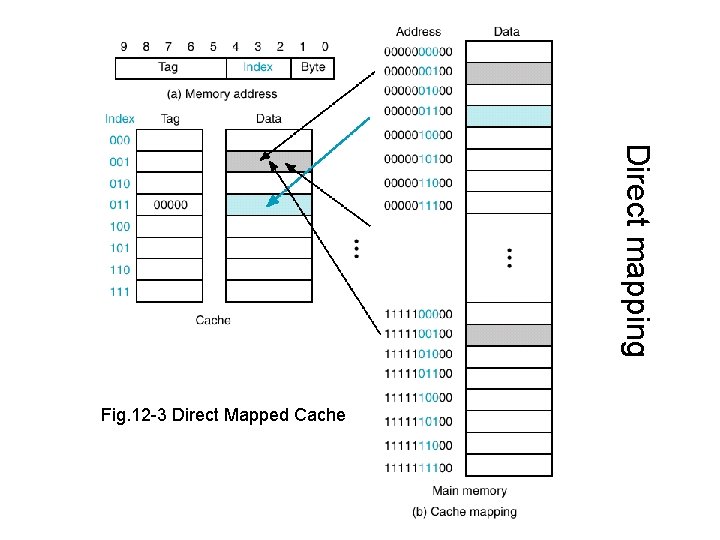
圖片取自該連結。
Direct Mapped 的機制會將資料直接映射到 Cache line 上面,我們可以想像一下,一個班級有 1 - 50 號,所以 Cache 也分配了 50 個位置 (第一個位置只有座號為 1 號的同學能夠入座)。
這時如果有 20 個班級,就有可能造成多個來自不同班級卻同號碼的學生爭搶一個位置,讓彼此不斷的被替換出去。
比起 Direct Mapped 的機制,Fully Associative 就簡單多了,它會分配 50 個不需按照座號入座的位置,所以可以讓不同班級座號相同的學生同時待在 Cache 當中。
不過這麼做的缺點也很明顯,如果要尋找特定的同學,最差的情況下我們需要查找 50 個位置才能得知這位同學是否有入座。
Fully Associative 雖然可以避免掉同學之間不斷換掉彼此的情況,卻增加了查詢的效率,為了改良這些缺點,電腦科學家提出了另一個方法 - N-way Set Associative。
該方法可以想成將 50 個位子拆分成 5 組,每組有 10 個位置,第一組可以讓任一班級的 1 - 10 號同學入座,以此類推。
Cache miss 有三種情況:
又稱為 cold start misses,第一次存取未曾在 cache 內的 block 而發生的 cache miss,這種 miss 是不可避免的。
因為在程式執行期間,cache 無法包含所有需要的 block 而產生的 cache miss。發生在一個 block 被取代後,稍後卻又需要用到。
發生在 set-associative 或 direct-mapped caches,當多個 blocks 競爭相同的 set,也稱作 collision misses。
當 conflict misses 發生,有三種方法替換方法
將集合中最早進入的區塊加以取代,實作上非常容易,不過也容易將重要資料替換掉。
挑選集合中隨機一個區塊替換掉。
取代掉最不常用的資料,這種替換策略在實作上會比 FIFO 要來的複雜,但可以避免頻繁使用的資料被換掉。
除了 CPU 中使用了 Cache,我們更可以在現今大大小小的資訊設備或是應用上看到 Cache 的影子,以作業系統的檔案系統為例:
我們都知道磁碟的速度是非常慢的,如果所有資料都是等系統要用時才去磁碟上讀取,整個作業系統的 IO 延遲會非常高。為了解決這個問題,作業系統端會在檔案系統中實作一層 Buffer cache,將一些資料存放在 RAM 當中,至於替換機制就可以採納 LRU 策略,讓作業系統可以隨時取得常用的資源。
Cache 的出現可以大幅度的提升處理器的效率,不過,在多核心的世代,Cache 也為資料的同步帶來了一些麻煩。假設一顆處理器之中有 4 個實體核心,每個核心都有獨立的 Cache,當複數個實體核心都 Cache 了一筆資料並對其做了修改,這樣不就讓資料發生非預期的運算結果了嗎?
談到這邊,學習過系統程式的同學可能會想到: 那我用 Lock 的機制保護這些資料呢?這樣是不是就可以保護這些資料的正確性了?
如果你有這個想法非常好,不過換個方式思考,Lock 的實作也是仰賴記憶體變數做紀錄,如果今天多個實體核心的 Cache 都保存了同一道鎖的狀態 (未上鎖),這樣不就又讓複數個核心存取同一筆資料了嗎?
談到這邊,會出現兩種觀眾:
這邊就讓筆者賣個關子,等到學習完作業系統的知識後再回頭學習 Lock 與它的演進版本吧!


 iThome鐵人賽
iThome鐵人賽