最鄰近點規則(以下簡稱為KNN,因為每個人對此的中文稱呼不一樣)是在一個地方上有很多個點,將所有點都分類好,而產生不同的區域。若之後有新的點加入,則計算該未知點至其他的所有已知點的距離,得知該點較為偏向哪種區域。
舉例來說,有一個二維座標,上面6個樣本,每個樣本分布在不同的遊戲種類,目前就兩個種類分別是動作類以及愛情類,x軸象徵格鬥,y軸象徵交往,分數越高表示其在遊戲中比例越重。其比重以及分佈如下。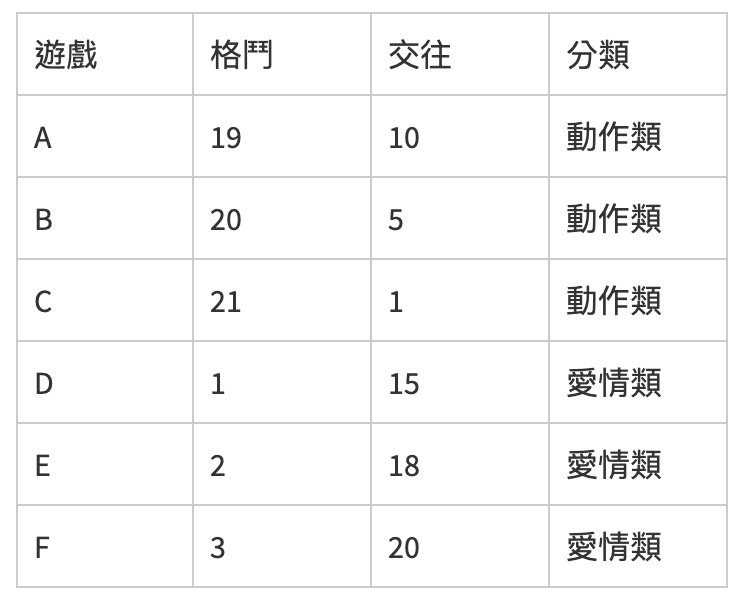
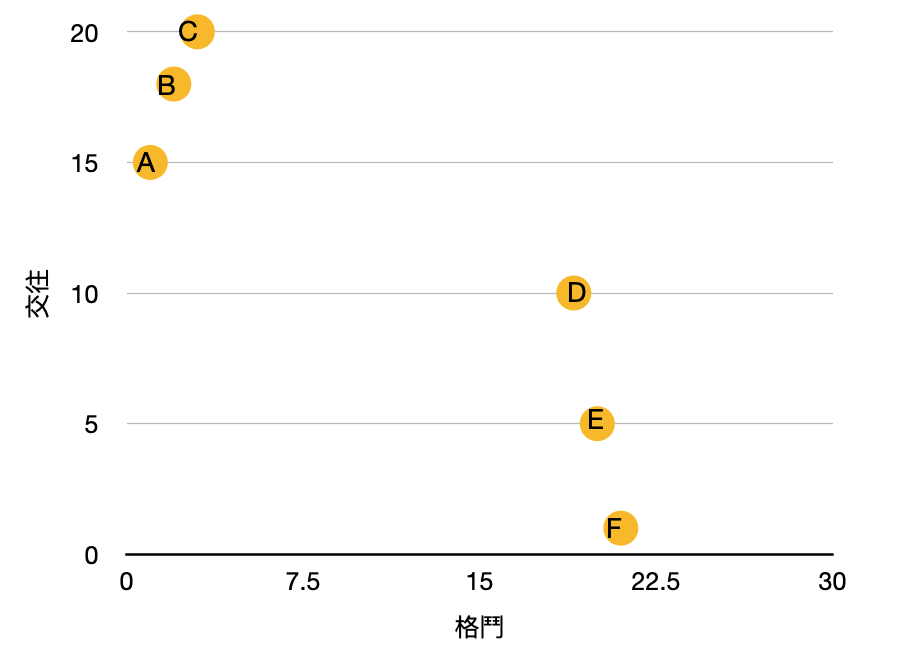
如今有個樣本G加入,其格鬥15,交往4,計算它與A、B、C、D、E、F之間的距離分別為:3、4、5、14、13、12,若取前四個接近的樣本,則有三個為動作類,一個是愛情累,因此判斷G距離動作類較為接近,把 G歸類在動作類遊戲。
這方法用在歸類上很方便,但是如果其中一個種類的樣本數很多,可能在一定距離以內,該種類樣本數較多,因此就被歸類在較多的樣本數中了,但並非有最接近的樣本,示意圖如下:中間正方形是未知的樣本,可以看到紅圈是距離下AB有的樣本數,顯然A有更接近正方形,可是其樣本數反而B比較多,因此未知的樣本就會被歸類在B區。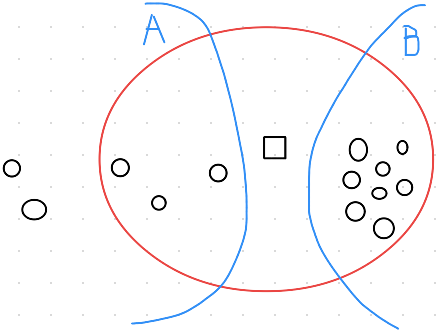
用這方法可以很輕鬆的機器學習,但如果當樣本數多、區域多的時候,可能分類的效果就沒那麼好了。


 iThome鐵人賽
iThome鐵人賽