接著來講講怎麼取得 browser 目前網頁中的本文內容,然後再把它轉給昨天介紹字典 App。
網頁內容千奇百怪,如果直接抓取整個網頁的所有文字,其中會有很多不必要的資訊:像是標題,側邊欄,其他相關文章連結說明,留言,等等等。
這時,之前開發好的閱讀模式就可以派上用場了。閱讀模式正是把不相干的元件都去除,只留下真正重要的內容。如果先在網頁上套用閱讀模式,再抓取文字內容,就可以得到比較純正的內容。把這些內容再拿去翻譯就不會顯示雜亂無章。
閱讀模式功能採用的 Readability.js 很好心的提供了一個 textContent 的變數,讓我可以直接拿到裡頭的純文字部分。(第 563 行)

下面的程式碼片段則是在將網頁先切換成閱讀模式,然後才去取得裡頭的文字部分:
suspend fun getRawText() = suspendCoroutine<String> { continuation ->
if (!isReaderModeOn) {
injectMozReaderModeJs(false)
evaluateJavascript(getReaderModeBodyTextJs) { text -> continuation.resume(text.substring(1, text.length-2)) }
} else {
evaluateJavascript(
"(function() { return document.getElementsByTagName('html')[0].innerText; })();"
) { text -> continuation.resume(text) }
}
}
實作上述三個環節後,就大功告成啦。由於這功能只支援 Onyx 的設備,所以我在工具列中加了一個全文翻譯的按鈕,但目前只有在 Onyx 的設備中才會顯示。
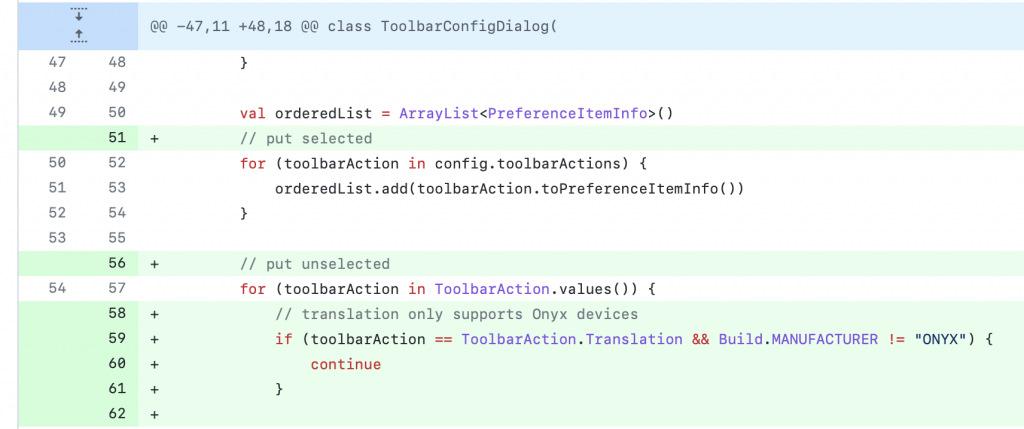
第 59 行判斷設備是否 Manufacturer 為 ONYX,如果是的話,就表示這是文石生產的設備,這時才會在工具列設定中出現在這個功能讓使用者選擇。
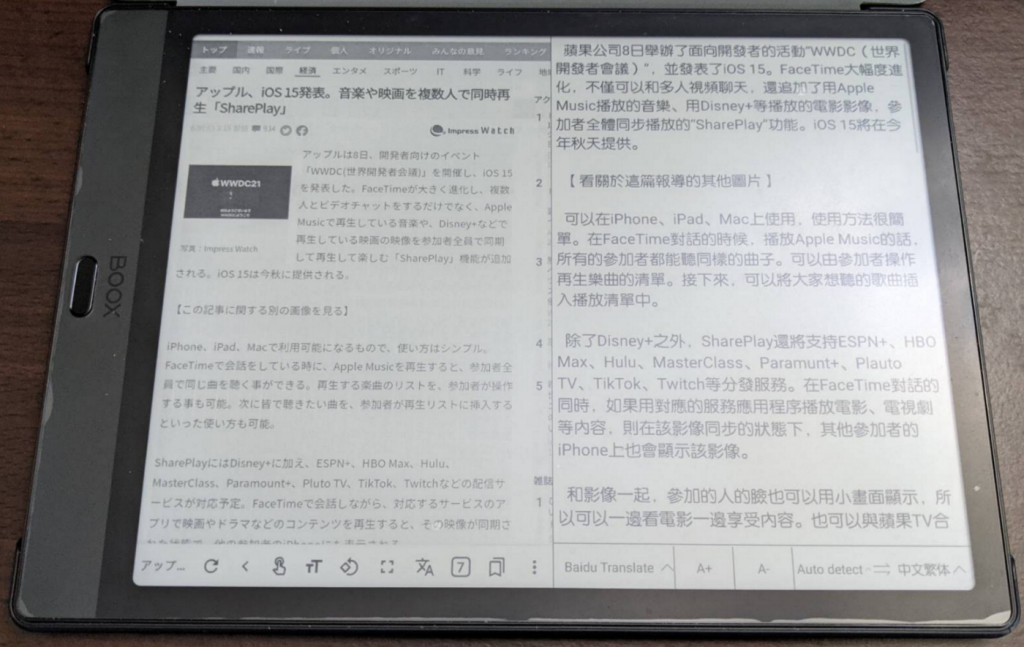
https://github.com/plateaukao/browser/releases/tag/v8.9.0
在後續幾篇會再介紹到如何加入 Google Translate 網頁的全文翻譯方式。這麼一來,就可以不用只受限於 Onyx 的設備。因為那部分內容有點複雜,所以也是會分成幾篇來講解。

