
走過了資料分析、演算法選擇後,
我們得知了有些可以改善模型的方向:
為了解決資料不平衡的問題,
昨天嘗試過資料增強,
但效果不是很明顯,
今天我將嘗試調整類別權重(class weight)。
現在我們從損失函數(loss function)下手,
以最簡單的Mean Squared Error舉例: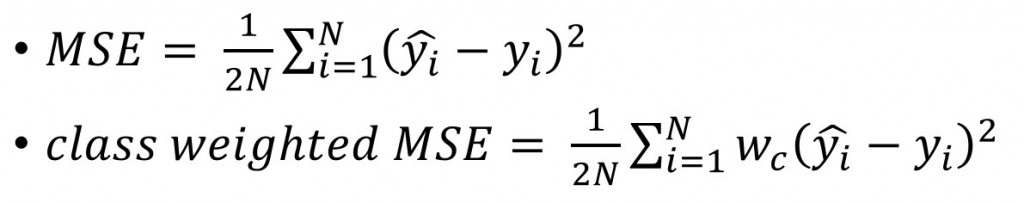
我們現在有N筆資料,y^是預測值;y是實際值,
對於每一筆資料i來說,我們去計算預測值和實際值差的平方,
然後取平均值。(為什麼要除以2? 因為導數比較好看 :D)
class-weighted MSE就是在計算第i筆資料時乘以一個權重,
如果這個權重比較大,那這筆資料的loss就會影響整體loss較多。
由於最佳化理論就是在想辦法降低loss,
所以當某一類別佔據大部分的loss時,
最佳化方法降低loss時,就是在特別學習該類別的資料。
對於資料量較少的類別(像是罕見疾病),
我們預設模型在學習辨識它們時會有困難(因為給他學的材料不夠多),
所以把資料量少的類別權重提升就對了!
在實務上有一個簡單地決定類別權重的方式,
那就是把每一類權重設成該類資料量的倒數。
例如:
| 類別 | 資料量 | 類別權重 |
|---|---|---|
| A | 1 | 1 |
| B | 10 | 0.1 |
| C | 100 | 0.01 |
以下是我的實作方式,
如果有更簡單的方式歡迎提出XD
class_sample_size = [np.where(y_train == c)[0].shape[0]
for c in range(len(emotions.keys()))]
max_class_size = np.max(class_sample_size)
class_weight = [max_class_size/size for size in class_sample_size]
class_weight = dict(zip(emotions.keys(), class_weight))
# class_weight =
# {0: 1.8060075093867334, 1: 16.548165137614678, 2: 1.7610446668293873, 3: 1.0, 4: 1.4937888198757765, 5: 2.275307473982971, 6: 1.4531722054380665}
上面做成一個dictionary是因為keras.fit()下參數的時候需要。
hist1 = model.fit(X_train, y_train_oh, validation_data=(X_val, y_val_oh),
epochs=epochs, batch_size=batch_size, class_weight=class_weight)
訓練出來的模型就叫做EFN_classWeight。
拿來和EFN_base(baseline)做比較:
模型 | 訓練時長(秒) | acc | loss | val_acc | val_loss
------------- | ------------- | ------------- | -------------
EFN_classWeight | 2557 | 0.931 | 0.315 | 0.603 | 1.844
EFN_base | 2004 | 0.952 | 0.139 | 0.617 | 1.905
結果準確率居然降低了
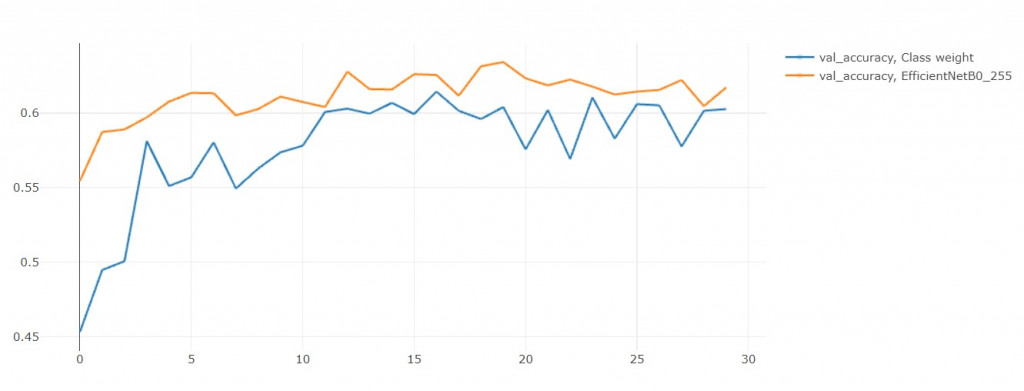
loss果然是降低了!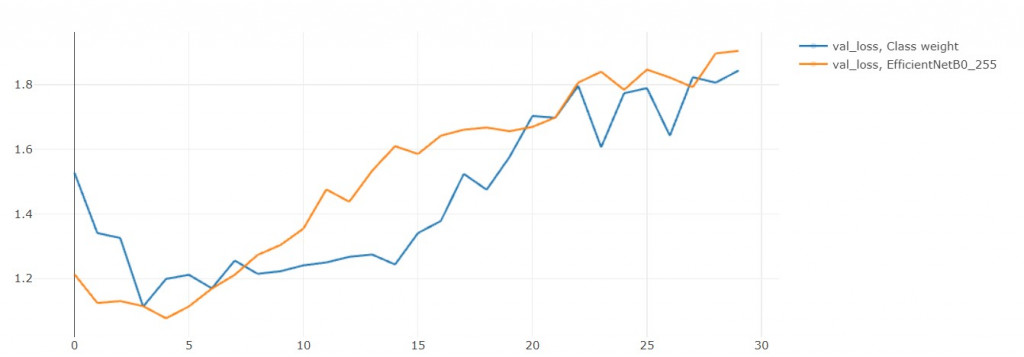
雖然說驗證集準確率降低了,
但不要忘記這是因為我們還沒"訓練完全",
從train_loss和val_loss的趨勢來看: over fitting的現象減緩了,
如果再繼續訓練個10 epochs可能就能在acc上超越EFN_base了!
