接續昨天的內容,今天要實作使用爬蟲技術,根據給定的小說網址,抓取其書名和作者資訊。
這次會使用兩個套件:
pip install requests
pip install BeautifulSoup4
import requests
page = requests.get("http://www.jjwxc.net/onebook.php?novelid=3397298")
print(page.text)
print("encoding: " + page.encoding)
使用GET方法取得網站的HTML,但在中文網站上有時會出現亂碼問題: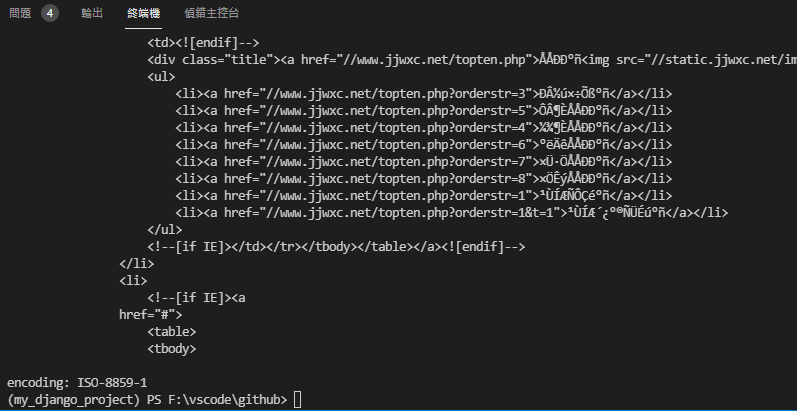
主要原因在於requests雖然會自動判斷網頁,但有可能會判斷錯誤。
如此範例中,使用page.encoding顯示requests的編碼方式為ISO-8859-1,但實際打開HTML,在head中標示使用gb18030。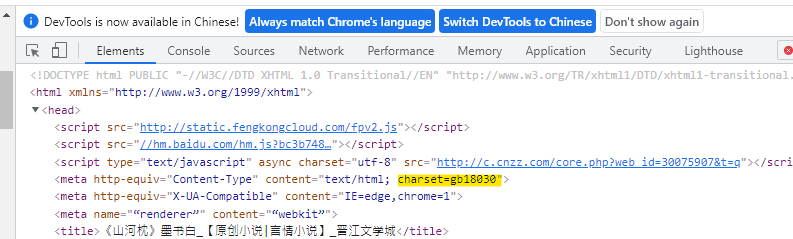
因此只要將page.encoding手動設定和HTML內相同的編碼,即可解決亂碼問題。
import requests
page = requests.get("http://www.jjwxc.net/onebook.php?novelid=3397298")
page.encoding = 'gb18030'
print(page.text)
print("encoding: " + page.encoding)
在取得HTML後,接下來我們就可以使用BeautifulSoup進行解析。
soup = BeautifulSoup(page.content, 'html.parser')
其中的'html.parser'為指定BeautifulSoup使用的解析器,不同的解析器產出的結果都不同;回傳的soup,則是是經過解析後產生的樹狀結構物件。
接著回到chrome瀏覽器,在書名的部分點擊右鍵,選擇「檢查」,在開發者工具中會看到書名使用標籤,且其屬性itemprop為articleSection。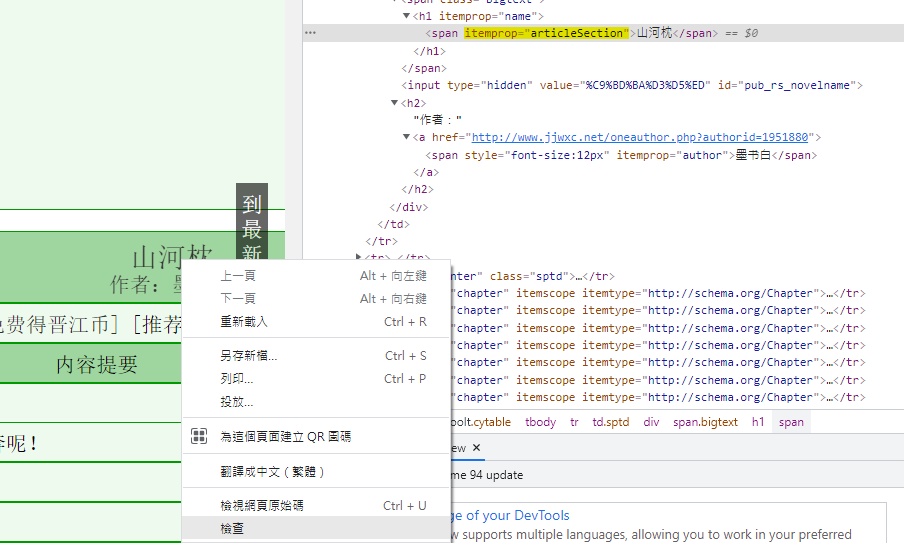
了解抓取目標的標籤屬性後,即可透過soup.find()方法找到該標籤:
title_tag = soup.find("span",itemprop="articleSection")
print(title_tag)

使用print()確認內容,發現find()回傳內容會包含HTML標籤,故再使用正規表示式處理,擷取所需的文字。
完整程式:
import requests
from bs4 import BeautifulSoup
import re
page = requests.get("http://www.jjwxc.net/onebook.php?novelid=3397298")
page.encoding = 'gb18030'
soup = BeautifulSoup(page.content, 'html.parser')
title_tag = soup.find("span",itemprop="articleSection")
author_tag = soup.find("span", itemprop="author")
title = re.compile(r'>(.*)<').search(str(title_tag))
print(title.group(1))
author = re.compile(r'>(.*)<').search(str(author_tag))
print(author.group(1))


 iThome鐵人賽
iThome鐵人賽