InnoDB將索引分成Cluster Index & Secondary Index,認識前面的主索引(PK)後,今天來看當我們建表時自己建立的index又是如何執行的~
前面提到Cluster Index只能有一個,因為資料表紀錄的排序方式會根據設定的Cluster Index排序分佈,而Secondary Index(我們自己建立的欄位index),根據需求建立不會只能有一個(1~N個)~
ps.為何這邊都會寫Cluster Index(PK) -> 個人覺得比較好辨識,因為一般來說我們建表時都會順便把Primary key訂好,可以說PK基本上就是Cluster Index。
當然這是有設定的狀態,沒設表PK參考前一天了解主索引架構中知道Cluster Index是如何選擇的~
Q: 因為建立index能提高查詢資料的速度,是不是多建一點在各個欄位就好?
A: 當然不行
前面有提到索引是占空間的,雖然合適的index能提升查詢速度,但相反的會降低表數據更新速度。
因為當你建立了一組index等於另外生成一個Secondary Index結構,當有異動到相關的表數據時,需同時更新索引。
建立一個合適的index時需同時考慮到欄位重複值高低及如何搭配欄位去達到更佳的查詢效果等等...,當然日後使用頻率也是一大重點。
非聚集索引 Secondary Index (二級索引) 是什麼?
一樣採用B+Tree來作為組織結構,但不同的是Secondary Index的葉節點內容存放的不是主鍵值的對應資料,而是儲存key和clustered key(PK)值,找到後再去clustered index找資料行數據。
ps. 建立Secondary Index不會重新組織主索引結構喔~
在範圍查詢時存取row data時不一定是循序讀。
簡單流程
ex. 建立index(name) -> 查詢name=siang的紀錄
(先) 從Secondary Index找到資料對應的主鍵。
(後) 回Cluster Index根據主鍵找到具體數據行。
假設有以下資料表user的結構&索引 primary key (id) / secondary index (name)
id | name | status | account
------------- | -------------
1 | shawn | 1 | xxxxxx
... | ... | ...| ...
26 | siang | 1 | a1234
ex. 要找siang這筆資料的所有欄位紀錄~
select * from user where name = 'siang';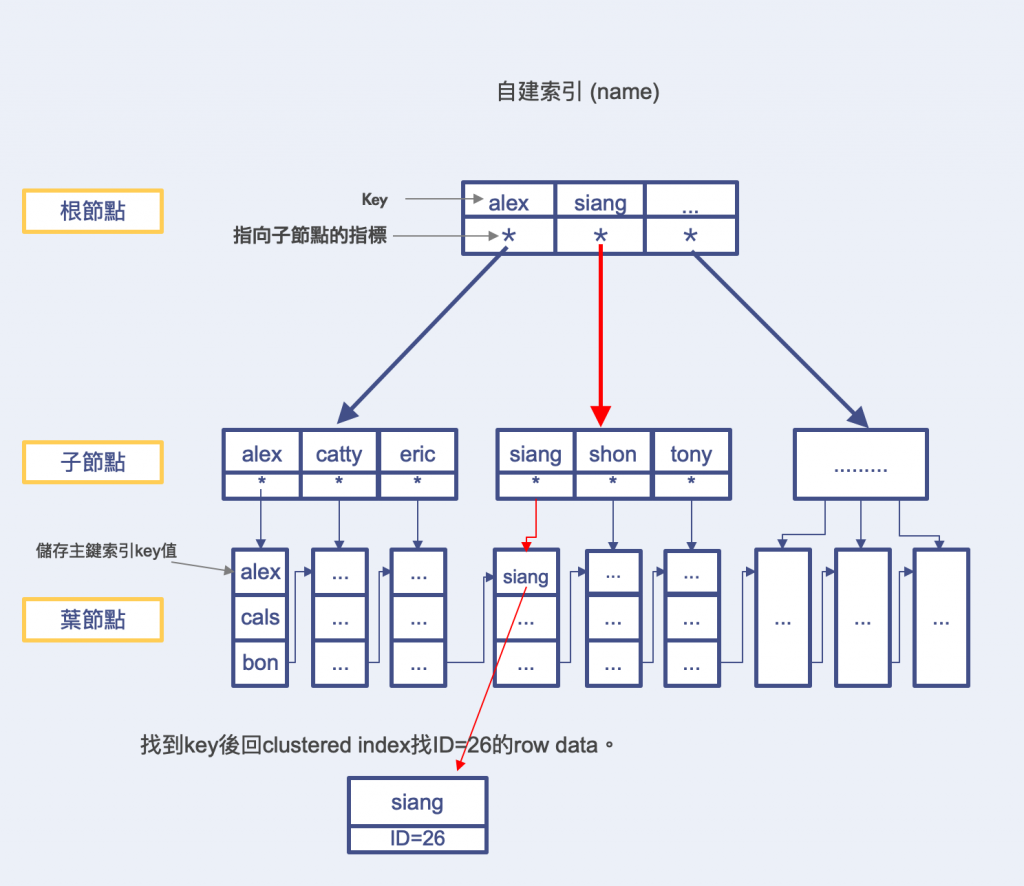
覆蓋索引
上面可以看到我們要查找id= 26,name= siang的所有數據行,需要進行二次查詢回clustered index找。
那如果要查詢的欄位資料只要從secondary index就能取得,則會直接從secondary index的leaf node取值返回數據內容,稱為覆蓋索引。
Example table: user
-資料準備-
CREATE TABLE `user` (
`id` bigint(20) NOT NULL,
`name` varchar(100) DEFAULT NULL,
`account` varchar(50) NOT NULL,
`Status` tinyint(5) NOT NULL,
PRIMARY KEY (`id`), -> (clustered index)
KEY `name` (`name`) -> (secondary index)
)
insert into user (id,name,account,status) values(1,'shawn','qq111',1),(2,'eric','w11zx',2),(3,'edwin','x12a1',2),(4,'shen','v2111',2),(5,'siang','a1234',1);
mysql> select * from user;
+----+-------+---------+--------+
| id | name | account | Status |
+----+-------+---------+--------+
| 1 | shawn | qq111 | 1 |
| 2 | eric | w11zx | 2 |
| 3 | edwin | x12a1 | 2 |
| 4 | shen | v2111 | 2 |
| 5 | siang | a1234 | 1 |
+----+-------+---------+--------+
5 rows in set (0.00 sec)
看一下查詢語法分析explain:
PS. 查詢SQL前只要加上explain能幫助你了解這句SQL使用到什麼索引等相關幫助SQL優化的資訊!!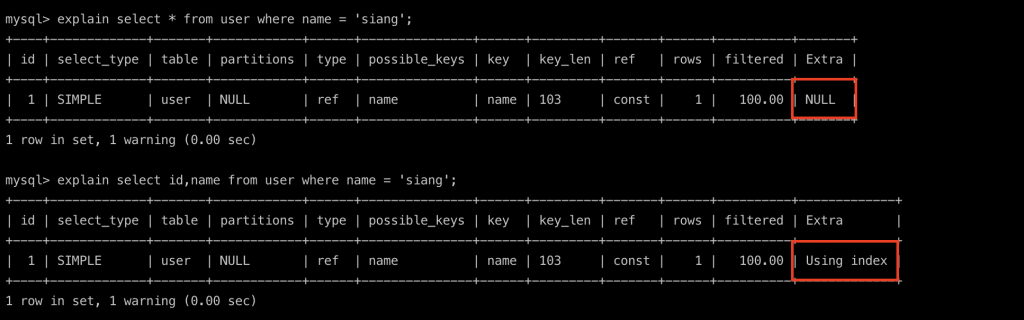
當查找id,name時,因為secondary index就有資訊能返回(Using index),不必在回clustered index找其他欄位內容。
了解這些基礎索引知識後,能幫助日後建表時提供一些方向。
不過合適的index的建立與優化又是另一個課題了~

