「鮭魚均,因為一場鮭魚之亂被主管稱為鮭魚世代,廣義來說以年齡和臉蛋分類的話這應該算是一種 KNN 的機器學習,不正經的數據分析師,畢業後把人生暫停了半年,在 Google 和 AWS 辦過幾場演講,緩下腳步的同時找了份跨領域工作。偶而慢跑、愛跟小動物玩耍。曾立過很多志,最近是希望當一個有細節的人。」
之前的內容許多都是限制在指定影片的情況下,如果說我今天需要抓取一個變動資料,這時候我們就必須想想是否有新的解決方法跟可能性,這篇是 Python - 數位行銷的 Youtube 分析教學系列文章的第 12 篇,也是我參加 2021 iThome 鐵人賽中系列文章的第 12 天。
系列文章:Python — 數位行銷分析與 Youtube API 教學
昨日回顧:Youtube Data API 教學 - 頻道區塊分類 channelSections
在過去的資料 part 種類文章文章中,我們曾經有提到要如何抓取影片內部的相關資訊,但這一切的前提都是在指定影片的情況下,如果說我今天需要抓取一個變動資料,或者是說有新的影片不斷地加進來,這時候我們可能就需要使用其他的方法來解決這個問題了 playlistItems().list 的出現就是要解決這樣子的問題,俗話說理工男嗎就是有問題要解決問題,沒問題要創造問題。playlistItems().list 功能包含了播放清單內影片的發佈時間(publishedAt)、影片標題(title)、影片描述(description)、影片縮圖(url)等等之類的訊息,只要新的影片加入到播放清單中,就能夠抓到相關的新影片資訊。
今天找的範例頻道是人跟文字都優美又時尚的捨藺 "Serene Vitale" 來作為這次程式範例的介紹,身為 Serene 的小粉絲,從之前在 Duke 分享紐約時尚實習生時就一直有在 Follow 她,對於美學穿搭都很有自己的想法與概念,是我很喜歡的影音創作者。我們從頻道的播放清單中,能看見 Serene 有4個不同的播放清單。
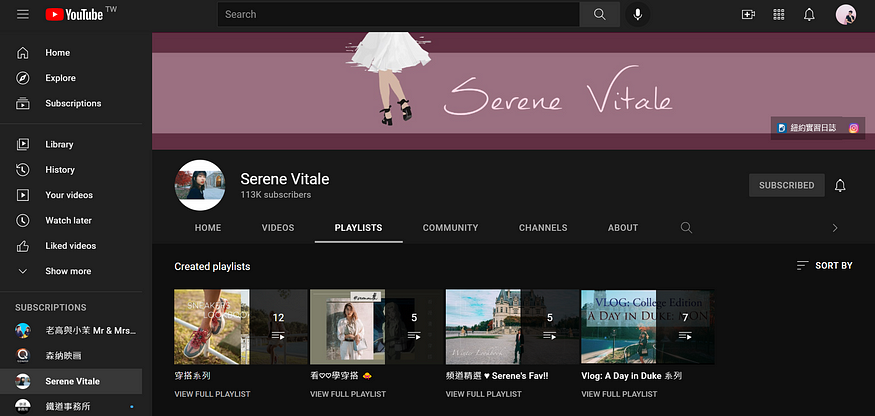
我們在點進去穿搭影片的播放清單後,能看見影片右邊,開啟了「穿搭系列」這個播放清單,從網址中得知 list 播放清單的 id 為 "PLxIOMmf0q1jj05_88uNFAqMEmOrwoGLdc",可以把這個資訊記下來,而前面的 v 則代表目前這部影片的 video ID "sUHeGzC0nKs"
在 Python 中使用 playlistItems().list() 方法中,設定參數 part= "snippet", 輸入 playlistId,與之前不同的是這邊多設定了一個 maxResults 為 50,預設為 5 但我們可以設定其最大值,maxResults 設定可以為 (0-50)。
def youtube_playlistItems():
request = youtube.playlistItems().list(
part= "snippet",
playlistId= "PLxIOMmf0q1jj05_88uNFAqMEmOrwoGLdc" ,
maxResults = 50
)
response = request.execute()
for i in range(len(response['items'])):
print(response['items'][i]['snippet']['title'])
if __name__ == '__main__':
youtube_playlistItems()
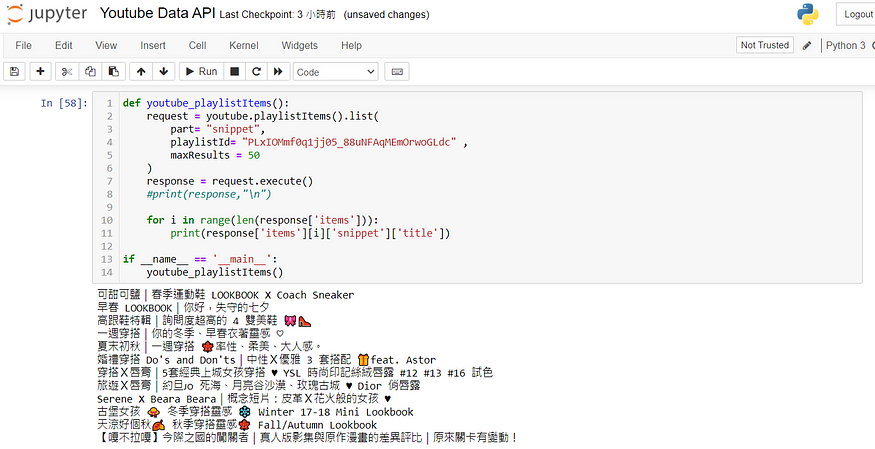
從上方可以得知「穿搭系列」這個播放清單中有 12 部影片,但是當我們對照出來後會發現這個播放清單只有 11 部影片,這剛好是個很好的範例,在最底下有一部 (1 unavailable video is hidden),代表就是其中一部影片是隱藏狀態,可能是因為設為私人影片了,但是從 API 資料中還是能夠看見這部影片,為 "旅遊X唇膏|約旦?? 死海、月亮谷沙漠、玫瑰古城 ♥ Dior 俏唇露"
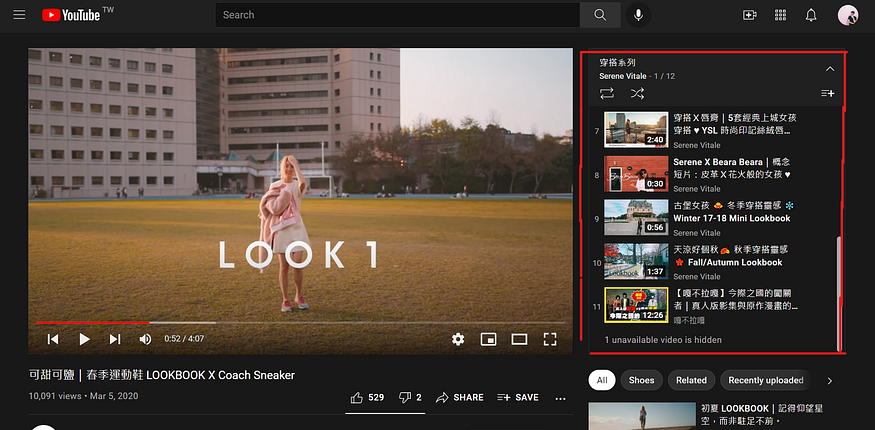
在response 的資料取用中,我們可以設定為標題資料 (title)、影片簡介(description)或是發布時間(publishedAt) 等等的資料,我們就可以從播放清單中一部部的把影片資料抓取出來。
def youtube_playlistItems():
request = youtube.playlistItems().list(
part= "snippet",
playlistId= "PLxIOMmf0q1jj05_88uNFAqMEmOrwoGLdc" ,
maxResults = 50
)
response = request.execute()
#print(response,"\n")
for i in range(len(response['items'])):
print(response['items'][i]['snippet']['title'])
print(response['items'][i]['snippet']['description'])
print(response['items'][i]['snippet']['publishedAt'])
if __name__ == '__main__':
youtube_playlistItems()
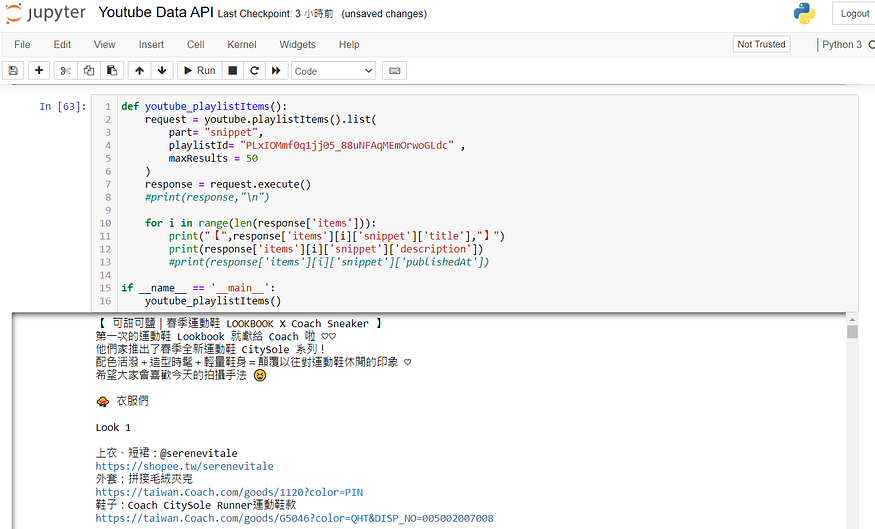
再次打開影片與影片中的內容對照一下,標題、簡介還有發布日期都正確,代表抓取資料是成功的,整體資料沒有什麼問題,今天的內容教學很順利(?)
這項功能對於時常需要更新播放清單資料的使用者而言非常的好用,你可以更快速更方便的進行資料的追蹤與實踐,謝謝你的閱讀,以下是其所需要花費的 Quota 數:
如果有時間也歡迎看看我的夥伴們的文章:
lu23770127 — SASS 基礎初學三十天
10u1 — 糟了!是世界奇觀!
juck30808 — Python — 數位行銷分析與 Youtube API 教學
HLD — 淺談物件導向與Design Pattern介紹
SiQing47 — 前端?後端?你早晚都要全端的,何不從現在開始?
【鮭魚均】 現職是 200 多萬訂閱 Youtuber 的數據分析師,專長在 Python 的開發與使用,大學雖然是資訊背景但總是斜槓跑到商管行銷領域,以工作角度來說的話,待過 FMCG、通訊軟體、社群影音產業,也算是個數位行銷體系出生的資訊人。這 30 天鐵人挑戰賽會從數位行銷角度去重新切入數據分析這件事情,期待這個資本主義的社會中,每個人能在各個角力間不斷沖突而漸能找到一個平衡點回歸最初的統計建立最終的初心。
下一篇:Youtube Data API 教學 - 告一個段落

