今天來做一個爬蟲的功能,以爬取鐵人賽的所有參賽者的標題及名稱為目標
先點開鐵人賽的選手列表頁面,首先可以觀察到如果是使用報名順序來排列的話在url上面會多一個order的key,其value=signup,再來每個頁面只會顯示10則訊息,但今天的目標是要找到所有的參賽者,所以需要一頁一頁往下點,也會觀察到點到別的頁面時在url上也會多一個page的key。
此時已經觀察好網頁顯示的規則了,就可以打開Chrome的工具來尋找要爬取的tag name了,在開始寫code之前先下載一個Laravel 專用的爬蟲套件,回到VSCode下指令
composer require symfony/dom-crawler
為了專注在爬蟲這件事情上面也是用Command的方式來製作速度會比較快
php artisan make:command crawlWeb
protected $signature = 'crawler:web';
protected $description = 'Participating title and contestants';
引入讀取HTML套件及網頁解析套件
use GuzzleHttp\Client;
use Symfony\Component\DomCrawler\Crawler;
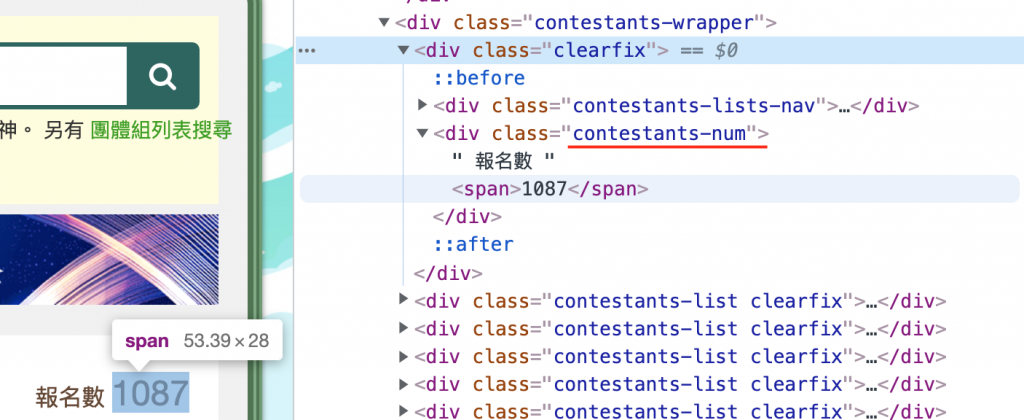
為了解決每一頁的url不一樣的問題,必須先做第一次的爬取,算出要爬的頁面數量,用Chrome可以觀察到報名數使用了div tag來包裝,並給予class = contestants-num,並且在數量的地方又用了span tag來包裝。
$path = 'https://ithelp.ithome.com.tw/2021ironman/signup/list';
$client = new Client;
$content = $client->get($path)
->getBody()
->getContents();
$crawler = new Crawler();
$crawler->addHtmlContent($content);
$number = (int) $crawler->filterXPath('//div[contains(@class, "contestants-num")]')
->filterXPath('//span')
->text();
$crawler = null;
$client此物件負責將整個HTML爬取回來crawler此物件利用tag來解析HTML
使用text function 提取出來的資料會以字串的方式呈現,但我需要的是數字,所以在前方加上(int)
來固定型別
crawler物件使用完之後就沒用了,將其設為null釋放記憶體避免後續記憶體不足
接著觀察每個專題的配置
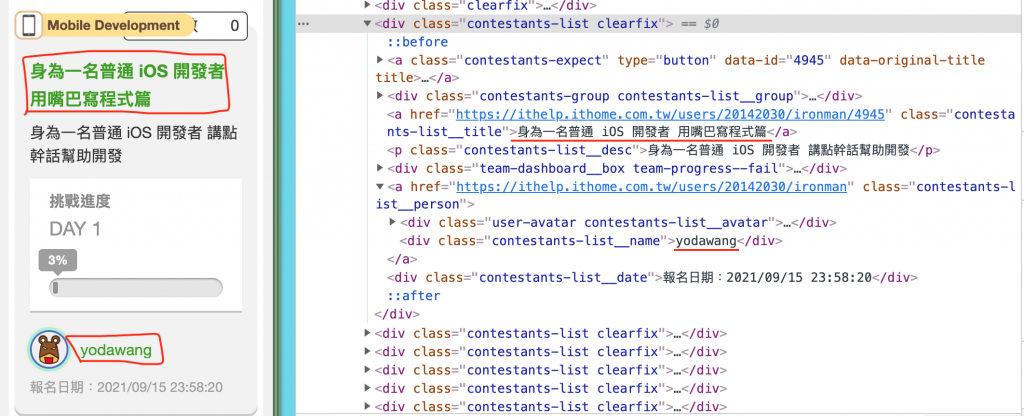
每個專題都會被一個div tag包裝,並且以 class = contestants-list clearfix 來做為識別,
因為每一頁會有十個專案,將十個專案爬取回來後利用each及匿名函式來做資料處理,每個專案底下的專案名稱會使用div tag包裝,並以 class = contestants-list__title用來識別,作者則是 class = contestants-list__name。
取得報名者數量之後就可以推斷出頁面數量了,使用for迴圈來爬取每一頁的資訊
for ($page = 1; $i < $number / 10 + 1; $page++) {
$path = 'https://ithelp.ithome.com.tw/2021ironman/signup/list?order=signup&page=' . $page;
$content = $client->get($path)
->getBody()
->getContents();
$crawler = new Crawler();
$crawler->addHtmlContent($content);
$projects = $crawler->filterXPath('//div[contains(@class, "contestants-list clearfix")]');
$projects->each(function($node) {
$projectName = $node->filterXPath('//a[contains(@class, "contestants-list__title")]')
->text();
$author = $node->filterXPath('//div[contains(@class, "contestants-list__name")]')
->text();
$message = '標題 : ' . $projectName . ' 作者 : ' . $author;
$this->info($message);
});
$crawler = null;
sleep(1);
}
接著就可以下指令開爬
php artisan crawler:web
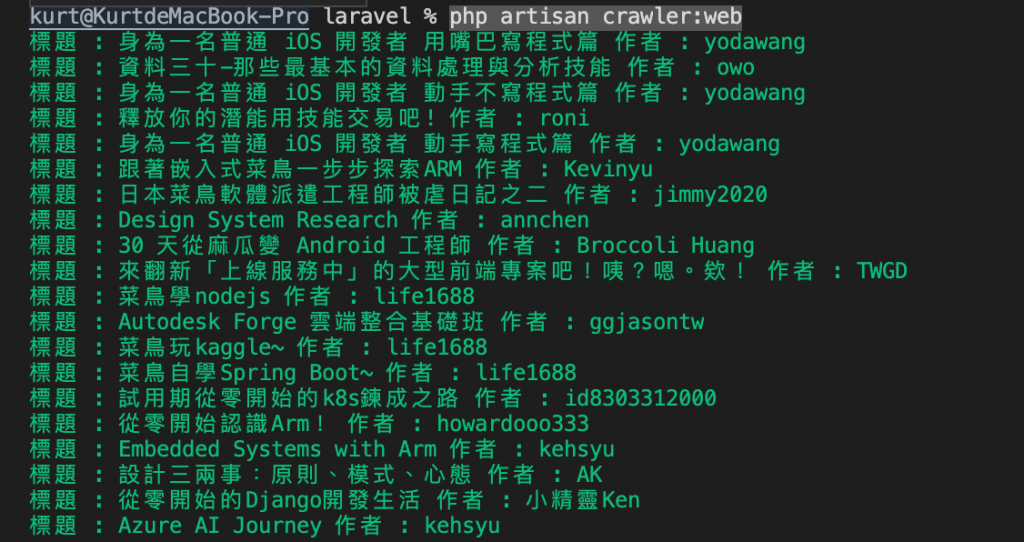
this->info()這個 function 可以字串直接輸出在terminal上,還有line、comment、question、warn、error等用法,詳細可至官方網站查看文件。
sleep(1)代表每撈取一頁的資料會暫停一秒鐘,避免同時間太多request打向server,有可能會因次被認為是DDOS而被封鎖。
今天的project算是爬蟲的入門,至少可以爬取一些完全沒有防檔的頁面,後續還會有進階的前置驗證、動態頁面無法爬取等困難點,有興趣可以再自行深入研究。
今天的介紹就到這邊結束了,希望可以趕快結束強力過敏頭昏腦脹的今天,謝謝觀看的各位,請記得按讚分享開啟小鈴鐺,你的支持會讓按讚數+1。


 iThome鐵人賽
iThome鐵人賽