
如果你的需求是想要累積集滿幾個subscriber再開始推送資料,這時候就是ConnectableFlux派上用場的時候了。某種程度上這跟Hot pubisher高度相關,也可以視作Hot vs Cold part 3
有兩種方式面可以將Flux轉為ConnectableFlux
publish :會根據consumer的消化速度來發送資料(backpressure),類似之前Sinks.Many.multicast,是Hot publisher,當執行connect之後的subscribe只會收到最新的資料。當所有Subscriber停止要資料的時候,publisher也將停止推送資料。replay: 會將過去的資料緩存下來,類似之前Sinks.Many.replay也是Hot publisher,可以調整保存資料的數量以及時間,來讓之後的Subscriber能取得。publish()則第二的的訂閱無資料,replay(2)指定保留兩筆資料,則能發現是保存最新的兩筆資料。Flux<Integer> source =
Flux.range(1, 5)
.doOnSubscribe(s -> System.out.println("subscribed to source"));
ConnectableFlux<Integer> co = source.publish();
co.subscribe(System.out::println, e -> {}, () -> {});
System.out.println("done subscribing");
Thread.sleep(2000);
System.out.println("will now connect");
co.connect();
co.subscribe(System.out::println, e -> {}, () -> {});
/*
done subscribing
will now connect
subscribed to source
1
2
3
4
5
*/
Flux<Integer> source =
Flux.range(1, 5)
.doOnSubscribe(s -> System.out.println("subscribed to source"));
ConnectableFlux<Integer> co = source.replay(2);
co.subscribe(System.out::println, e -> {}, () -> {});
System.out.println("done subscribing");
Thread.sleep(2000);
System.out.println("will now connect");
co.connect();
co.subscribe(System.out::println, e -> {}, () -> {});
/*
done subscribing
will now connect
subscribed to source
1
2
3
4
5
4
5
*/
ConnectableFlux提供了幾個方法來控制publisher是否需要推送資料,而不是單純像是一般的publisher是透過subscribe觸發。
connect():手動控制,可以自訂需求邏輯判斷已經有足夠的訂閱數再透過connect()來讓publisher開始推送資料。autoConnect(n):自動控制,傳入參數n為訂閱數,當訂閱數等於n則開始推送資料。refCount(n):另外一個方向的控制,剩餘還在訂閱的數量若小於參數N,則停止推送資料。refCount(int, Duration):類似於grace period,有使用過k8s的人可能比較好理解,就是當訂閱數小於N之後再經過傳入的時間都沒有再讓訂閱數大於N才會停止推送資料。cache並不會將Flux轉為ConnectableFlux,但常常會混為一談,因為cache的作用也是將Flux變成Hot pubisher,並且會緩存資料讓之後才訂閱的也能拿到資料,預設會無上限的保留,但也提供參數可傳入用來限制保存的數量,看到這邊是不是覺得似曾相似,某種程度上cache就等於 replay().autoConnect(1),一個訂閱者就自動connect,也跟replay一樣會保留資料。
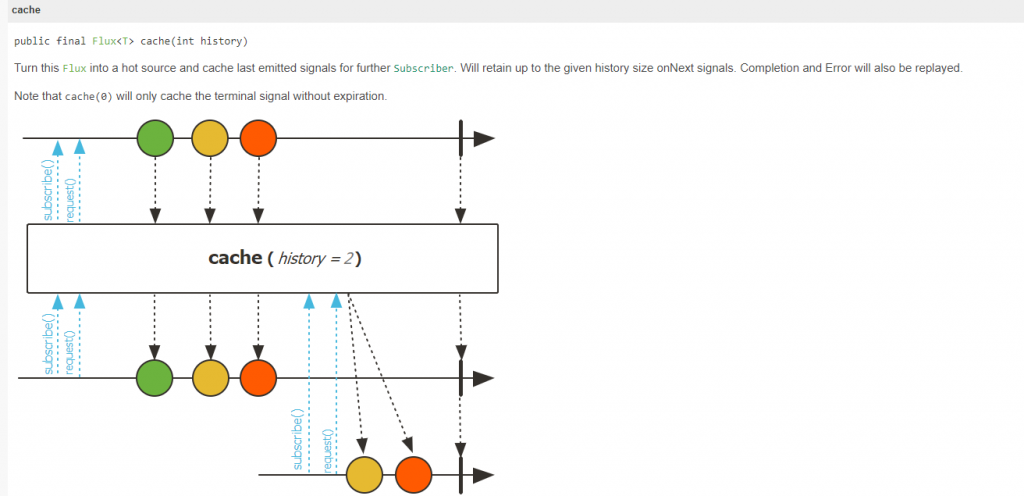
cache() vs replay() 的差異就是 replay()可以根據需求選擇connect()的時機點或是其他ConnectableFlux所提供的方法來控制邏輯,cache()則是當有第一個訂閱者就自動connect()。replay() vs publish() 的差別在於publish()並不會保存資料,也就是connect後的訂閱者就只能拿到最新的資料而不會是全部資料,反之replay()則是可以根據傳入的參數決定要保存多少資料。

