今天和明天的主題會以講解程式碼為主,其中 TF-IDF 演算法主要來自莫煩 Pythton。
莫煩 Python 原版程式碼: https://github.com/MorvanZhou/NLP-Tutorials
我修改過的版本: https://gitlab.com/graduate_lab415/nlp/-/blob/master/main.py
不確定我改了哪些東西(我也不記得了QQ),大部分應該只有加上印 log 的部分吧。
很重要,再提醒一次,中文要做 TF-IDF 要先經過斷詞,作法請參考前天的文章。 今天的 code 建議大家可以搭配 debug 模式使用,一行一行執行可以更清楚運作的步驟唷。
v2i = {'word': index}
i2v = {index: 'word'}
代表一個詞在一篇文章(一個句子)中出現的頻率。
def get_tf(method="log"):
"""term frequency: how frequent a word appears in a doc"""
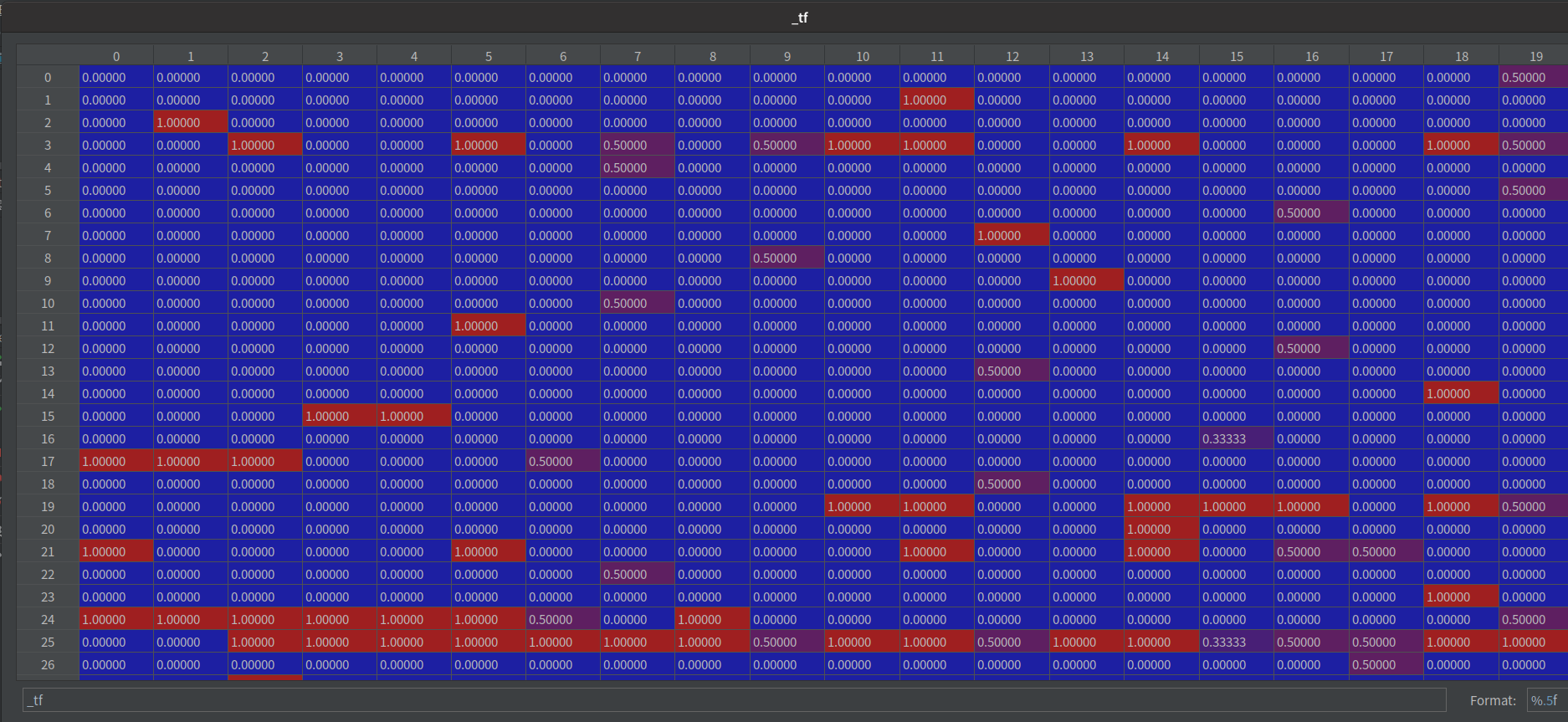
_tf = np.zeros((len(vocab), len(docs)), dtype=np.float64) # [n_vocab, n_doc]
for i, d in enumerate(docs_words):
counter = Counter(d)
for v in counter.keys():
_tf[v2i[v], i] = counter[v] / counter.most_common(1)[0][1]
weighted_tf = tf_methods.get(method, None)
if weighted_tf is None:
raise ValueError
return weighted_tf(_tf)
先建一個2維矩陣 _tf = [詞數, 句子數]
依序填入
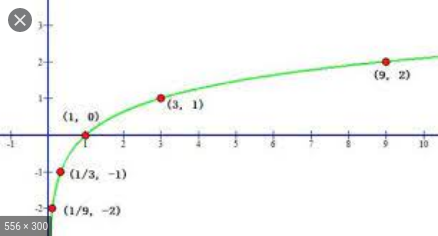
每個欄位都取自然對數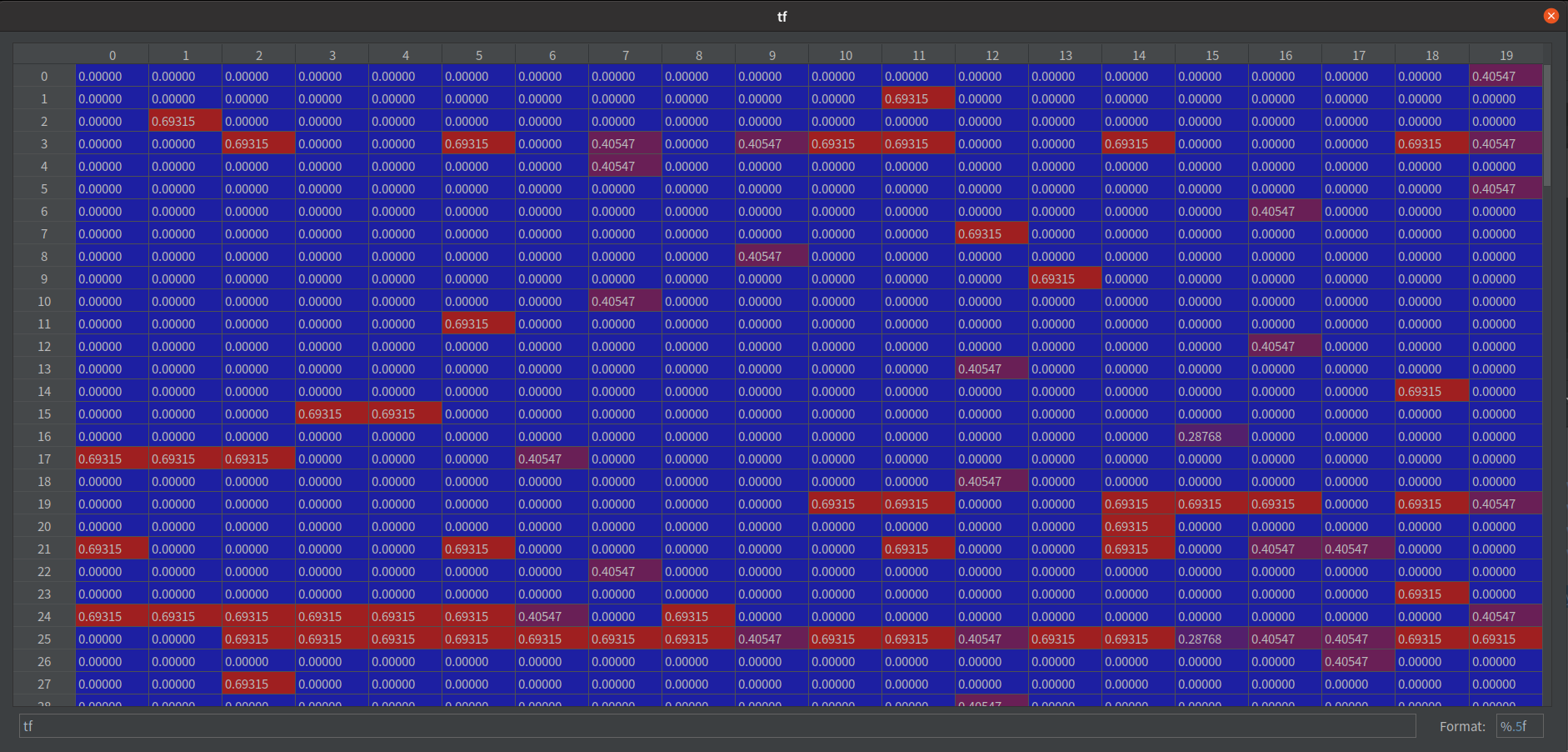
why 取對數?
處理資料時,對資料取對數的意義
log 以 e 為底的圖
取log優點
- 縮小資料的絕對數值,方便計算。
- 對數值小的部分差異的敏感程度比數值大的部分的差異敏感程度更高。
- 取對數之後不會改變資料的性質和相關關係,但壓縮了變數的尺度,資料更加平穩
def get_idf(method="log"):
"""df: document frequency"""
"""inverse document frequency: low idf for a word appears in more docs, mean less important"""
df = np.zeros((len(i2v), 1)) # [n_vocab, 1]
for i in range(len(i2v)):
d_count = 0
for d in docs_words:
d_count += 1 if i2v[i] in d else 0
df[i, 0] = d_count
if LOG:
print("\ndf samples:\n", df)
"""print df to a csv file"""
csv_writer = CsvWriter("df")
csv_writer.write_head(list(v2i))
csv_writer.write_row(df)
idf_fn = idf_methods.get(method, None)
if idf_fn is None:
raise ValueError
return idf_fn(df)
df = [n_vocab, 1]


如果詞語不在資料中,就導致分母為零,因此分母通常會加一
— from wiki https://zh.wikipedia.org/wiki/Tf-idf
注意觀察兩張圖,在 df 的數字越大,在 idf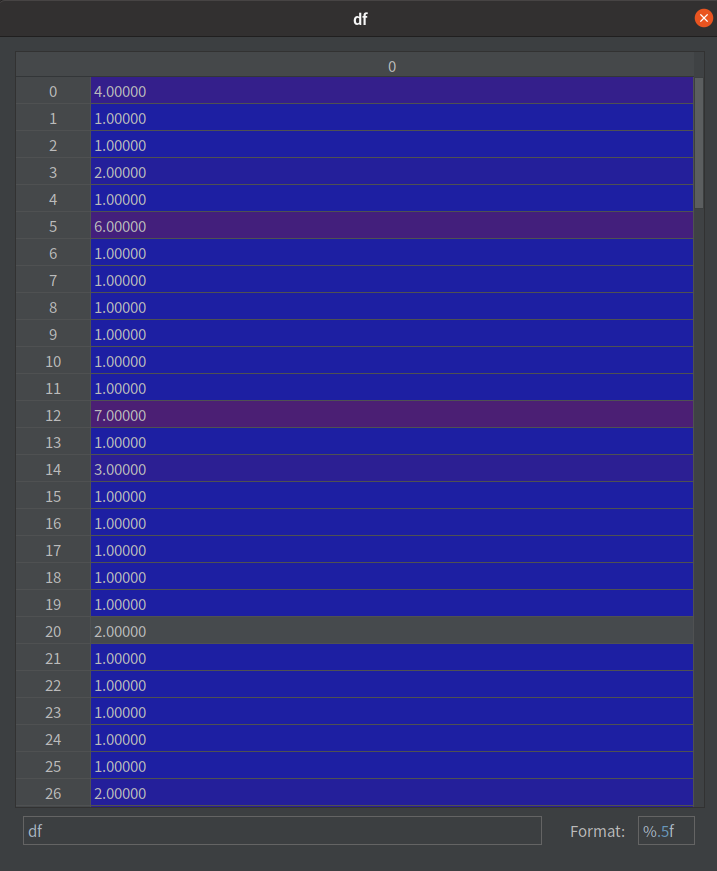
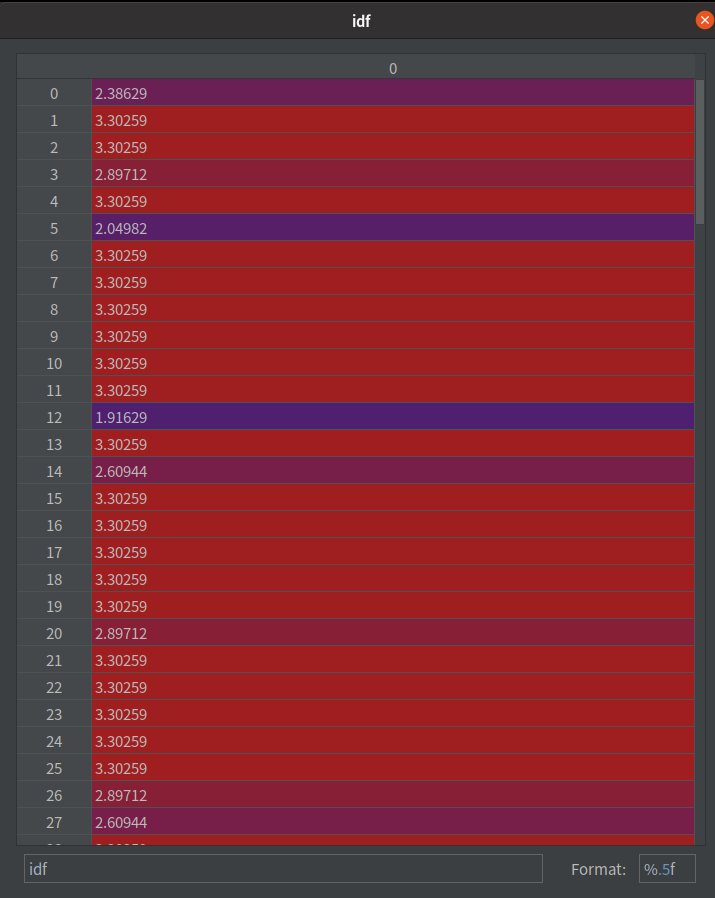
TF-IDF 其實就是將 TF 加權 IDF 後的結果。
公式: tf_idf = tf * idf
注意這邊是「乘」,不是矩陣乘法的那個 dot 哦。兩者在 Python 裡的寫法不一樣。
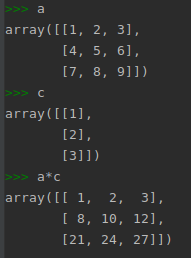
看個示意圖:
a 的第一列都乘以 c 的第一列
a 的第二列都乘以 c 的第二列
...
對應到程式碼裡的幾個陣列,他們的 size 分別是這樣的:
tf [n_vocab, n_doc]
df [n_vocab, 1]
tf-idf [n_vocab, n_doc]
將 tf * idf 就會等於 tf_idf 囉!
到這邊,語料庫模型(tf_idf)就建完了。明天會介紹,當我們接收到一個新句子,要如何比較它和其他句子的相似性。
好了,明天見!