With data collection, ‘the sooner the better’ is always the best answer. – Marissa Mayer
就像大家耳熟能詳的 GIGO 所闡述的概念一樣,我們收集來的訓練資料以及標註它們的方式直接影響了 ML 系統的最終輸出,而這與使用者體驗息息相關。
為了避免糟糕的資料選擇導致後續模型開發等步驟出師不利,甚至最終使得產品失敗,我們必須從一開始就計畫好如何收集高品質的資料,因此今天會說明以下要點:
收集資料時最重要的就是了解使用者,把他們的需求轉譯成資料問題 (Data Problem),才不會浪費時間收集用不到的資料,以 跑步路線推薦 app 為例:
首先要釐清使用者是誰?其需求為何?以及 ML 系統的目標為何?
而為了要把使用者需求轉譯為資料需求,可依序釐清:
最終收集的資料結果可能如下: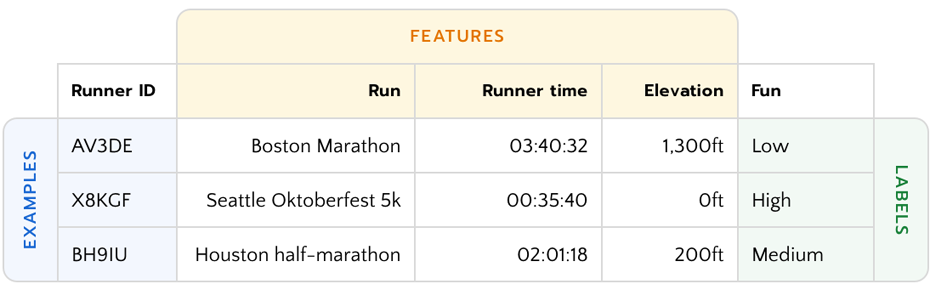
*圖片來源:People + AI Guidebook — Data Collection + Evaluation
另外對收集來的資料要負責任,這包含了紀錄來源、保障隱私以及避免歧視:
資料可能的來源有很多,要負責任地紀錄清楚:
資料收集與管理不只與模型有關,更重要的是安全與隱私,前者是指確保個人資料 (Personally Identifiable Information) 安全的政策或方法,後者則是正確的使用、收集、保留、刪除與儲存這類資料。
其中確保資料安全的方法有:
而透過以下方法則可以確保隱私:
必須在公平、可靠、透明、可解釋間取得平衡,否則 ML 系統可能會讓使用者失望,例如:
因此要時時注重公平性。
當 AI 團隊與其他領域專家合作時,最常被問到的問題就是,要提供多少資料才行?
這時候通常都是依照 feature 數量來大致推估所需的資料量,但在電子報 Data-Centric AI Development, Part 3: Limit Data Collection Time 提出了另外一種想法 — 把「要花多久才能收集 m 個樣本?」改為「在 d 天內可以收集多少資料?」,也就是改執行以下訓練迴圈:
這是因為首次訓練、錯誤分析的時間通常都不長,別因為收集資料延宕整體進度,盡快進入訓練模型的迴圈中才是王道,等資料真的不夠還有充足的時間再回頭收集就好。
如果已經有過去的經驗告訴我們需要多少資料就另當別論。
好啦,今天的內容就到這裡,明天就來繼續談談如何標註資料吧!


 iThome鐵人賽
iThome鐵人賽