
莫煩 Python 的原版程式碼: https://github.com/MorvanZhou/NLP-Tutorials
我修改過的版本: https://gitlab.com/graduate_lab415/nlp/-/blob/master/main.py
今天要來介紹繪製語料庫模型分布狀況的 Heatmap,成果圖大概會長這樣
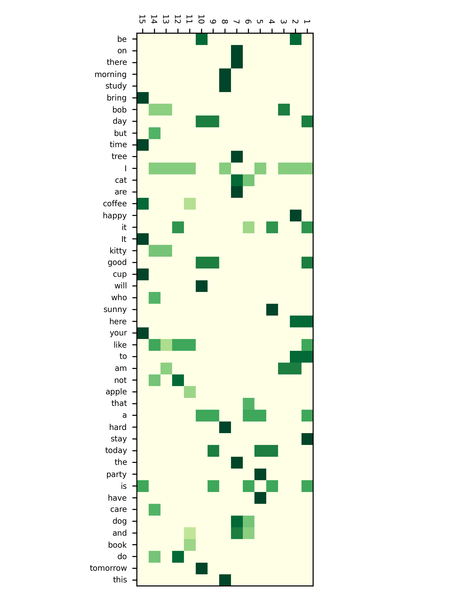

認真觀察圖片,以詞的部分來看,可以發現越常出現的詞,會呈現 淺色+多格;少出現的詞會呈現 深色+少格。
以一個句子來看,每個有出現在句中的詞,會呈現深淺不一的顏色,其中顏色越深的部分,代表這個句子中越重要的詞。
TF-IDF 假設出現越多次的詞越不重要
plt.rcParams['font.sans-serif'] = ['simhei']
plt.rcParams['font.family'] = 'sans-serif'
plt.rcParams['axes.unicode_minus'] = False
def show_tfidf(tfidf, vocb, filename):
# [n_vocab, n_doc]
plt.imshow(tfidf, cmap="YlGn", vmin=tfidf.min(), vmax=tfidf.max())
plt.xticks(np.arange(tfidf.shape[1]), vocb, fontsize=6, rotation=90)
plt.yticks(np.arange(tfidf.shape[0]), np.arange(1, tfidf.shape[1] + 1), fontsize=6)
plt.tight_layout()
plt.savefig("./visual/results/%s_%d.png" % (filename, calendar.timegm(time.gmtime())), format="png", dpi=500)
plt.rcParams['font.family'] = 'AR PL UKai CN'
plt.show()
在執行的過程中,其實遇到一些問題,所以這段程式碼是根據莫煩 Python 的範例修改的。
由於我的語料庫是中文為主,所以使用預設字體時遇到中文缺字很嚴重的狀況,幾乎全都變成方框。後來參考了這篇文章 centos下python使用matplotlib绘图出现中文乱码,修改了預設字體後,才能正常顯示。
BTW,我的環境是 Ubuntu 20.04
另外,還有另一個問題,一開始我用來畫 Heatmap 的資料是整個語料庫,就變成用 matplot 的小視窗可以看到完整版,但截圖下來所有的字就會全擠在一起,可讀性很差,所以後來才改成只用第三類的資料來畫。
最後,為了可以保存每次執行生成的圖片,不會被洗掉,我修改了檔名的格式,可以依當下的 timestamp 生成,就不會重複了。
畫圖的部分滿有趣的,平常只看數據,不一定看得出詞權重的關係,一旦畫成了 Heatmap,可以更視覺化的了解 TF-IDF 的意義。
