好的,前一篇講到了flow可以完全取代liveData,其實錯!!
直接從結論開始講,flow並不支援data binding,也有其限制,用stateflow才能完全取代liveData
flow適用於當數據的開始/停止需要和觀察者匹配
A cold flow backed by a channel or using operators with buffers such as buffer, conflate, flowOn, or shareIn is not safe to collect with some of the existing APIs such as CoroutineScope.launch, Flow< T>.launchIn, or LifecycleCoroutineScope.launchWhenX, unless you manually cancel the Job that started the coroutine when the activity goes to the background.
通過cahnnel產生的flow,或是使用buffer的flow,像是buffer()、conflate()、flowOn、shareIn(),在coroutine.launch、flow.launchIn、lifecycleCoroutineScope.launchwhen...並不能安全地蒐集,除非你在ui進入背景時手動取消job,因為上述的api會持續收集資料,即使ui已經進入背景
/**
* 錯誤示範
* */
// Collects from the flow when the View is at least STARTED and
// SUSPENDS the collection when the lifecycle is STOPPED.
// Collecting the flow cancels when the View is DESTROYED.
lifecycleScope.launchWhenStarted {
locationProvider.locationFlow().collect {
// New location! Update the map
}
}
這種寫法,當ui進入背景,新資料不會被處理,但是某些情況下producer還是會持續進行(blog的範例用channel 的offer),此外,lifecycleScope.launch和launchIn會更危險,即使ui進入背景,仍會不斷處理資料,最終可能導致應用崩潰
//正確寫法
var manuallyCanaelJob:Job?= null
...
manuallyCanaelJob = lifecycleScope.launch{
locationProvider.locationFlow().collect {
}
}
...
override fun onDestory(){
manuallyCanaelJob?.cancel()
}
儘管這種寫法正確,但比較麻煩,其實也就一個原因,flow不知道lifecycle
聰明的讀者們,應該從前一篇就有個疑問了吧?flow有collect了為甚麼還要asLiveData呢?是不是他不知道lifecycle呀
沒錯,他就是不知道lifecycle,大家回想一下,應該還記得當年學android為甚麼要用liveData吧,那flow不知道lifecycle不就要我們自己處理,好麻煩好麻煩,還是用asLiveData好了
且慢,其實~已經寫好囉
首先,確定gradle版本 androidx.lifecycle:lifecycle-*:2.4.0-alpha03
要在alpha01後的才有repeatOnLifecycle
implementation "androidx.lifecycle:lifecycle-viewmodel-ktx:2.4.0-beta01"
lifecycleScope.launch {
lifecycle.repeatOnLifecycle(Lifecycle.State.STARTED){
//只有在lifecycle到start及start之後
}
}
注意:
The minCompileSdk (31) specified in a
dependency's AAR metadata (META-INF/com/android/build/gradle/aar-metadata.properties)
is greater than this module's compileSdkVersion (android-30).
Dependency: androidx.lifecycle:lifecycle-viewmodel-ktx:2.4.0-beta01.
對android compile版本也有要求,最低31
gradle>android compileSdk 最低要31
他是一個suspend方法,會接受一個生命周期的狀態作為參數,當生命週期到該狀態時,會建立一個coroutine,並執行區塊中的代碼; 而當生命週期低於該狀態時,會自動取消coroutine
如此一來,repeatOnLifecycle就能為我們管理collect的取消,正如大多數函式,建議在activity的onCreat或fragment的onviewCreate中使用
Important: Fragments should always use the viewLifecycleOwner to trigger UI updates. However, that’s not the case for DialogFragments which might not have a View sometimes. For DialogFragments, you can use the lifecycleOwner.
因為這個repeatOnLifecycle現在還蠻新的,這三種寫法都可以編譯過,目前是沒發現什麼差異,但有被講到,還是提一下
lifecycle.repeatOnLifecycle(Lifecycle.State.STARTED)
//or
repeatOnLifecycle(Lifecycle.State.STARTED)
//or
viewLifecycleOwner.repeatOnLifecycle(Lifecycle.State.STARTED)
解釋了差異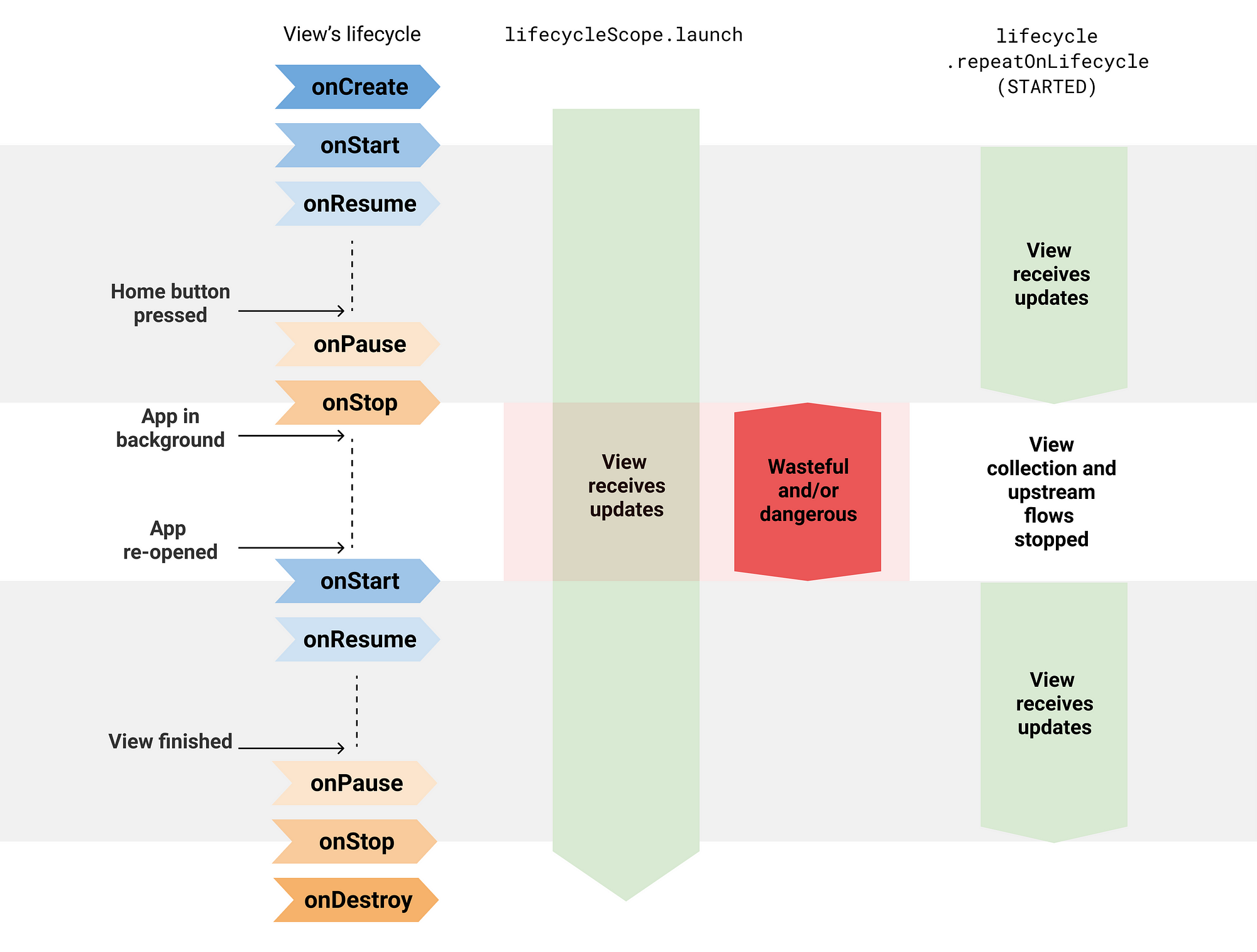

那寫一個小型範例
//retrofit
@GET("posts/{num}")
suspend fun getPostFlow(
@Path ("num") num: Int
): Post
// repo
val postFlow: Flow<Post> = flow {
var count = 1
while (true){
val result = service.getPostFlow(count)
emit(result)
count++
delay(2000L)
}
}
// viewModel
val changeId = repo.postFlow
//fragment
lifecycleScope.launch {
lifecycle.repeatOnLifecycle(Lifecycle.State.STARTED){
viewModel.changeId.collect{
binding.apiResultText.text = it.toString()
}
viewModel.otherFlow.collect{
//do something
}
}
}
應該和liveData的內容一樣很好理解,那repeatOnLifecycle其實就是告訴開發者,每次ui走到哪個生命週期後,這個block會被調用
於是...
lifecycleScope.launch {
viewModel.changeId
.flowWithLifecycle(lifecycle, Lifecycle.State.STARTED)
.collect{
}
}
對的,非常簡單,但google爸爸說,這個用法有兩點要注意
https://miro.medium.com/max/2000/1*fmQRBPMPpnO7NAO2bg0GKw.
記得我們之前講過channel吧,透過send()和receive()可以在不同corouitne之前傳遞值,而flow透過emit()和collect()發送流,兩個看起來~ 阿不就差不多
錯了錯了,從設計原因來看channel是為了同步設計的,而flow是為了數據流而設計的,也因為設計的實現不同,他們會有各自適合的工作,留個地方放之後寫比較的連結
而flow在設計上考量到許多數據流的痛點,也為此設計了很多操作符,更重要的是,flow是透過終端操作符來啟動數據留
flow分三個部分,producer、intermediary、consumer,consumer會啟動流,而當producer的代碼執行完畢、出現Exception、或是consumer停止,便會關閉數據流
因此flow比起channel更難在producer端出現異常(blog寫說不會或是非常難),而channel如果沒有正常關閉,會在prioducer端浪費資源
我們之前講過flow是一個冷數據流,他必須有人呼叫consumer的方法才會執行,而每次呼叫,都會創造出一個新的數據流
一個永遠不會被suspend的流,永遠不會被取消
何時用broadcastChannel當producer和consumer在不同lifecycle或是完全獨立存在時
broadcastChannel是基於Channel的實現,他能讓producer基於不同的lifecycle,並且廣播給任何監聽他的對象,而他的producer就不會每次都重新啟動
注意,如果用broadcastChannel.asFlow(),轉換為數據流,這時關閉flow並不會取消訂閱/觀察broadcastChannel,此時資源仍處在活耀狀態,直到vroadcastChannel取消或關閉。而關閉後只能在創造新的實例
更新,在shareFlow的文件哩,講明了會取代他,所以我就不講了
看到這裡應該會發現,已經沒有liveData了,沒錯,只要flow也能和lifecycle合作,就能夠一定程度上取代liveData,注意,只有一定程度
限制
這其實不是flow的缺點,而是特性,在某些狀態下他會非常實用
優點
那不用databinding的開發者,選哪個livedata還是flow呢?
看code reviewer有沒有要求,現在repeatOnLifecycle()還在alpha階段,之後可能還會有變動,但可以一邊用asLiveData,一邊了解新寫法
p.s.今天時間比較趕,應該有遺漏細節,之後會回來捕,或是你們直接留言告訴我哈哈哈
lessons-learnt-using-coroutines-flow
a-safer-way-to-collect-flows-from-android-uis
repeatonlifecycle-api-design-story
coroutines-best-practices
Substituting Android’s LiveData: StateFlow or SharedFlow?

