GPU卡原來是針對遊戲開發及顯示加速的設計的,後來才擴散至挖礦、深度學習...等其他領域,而遊戲內的物件移動、旋轉都是依靠矩陣運算達成的,因此,我們就來看看如何使用GPU進行矩陣運算。
之前 <<<...>>> 都是設定為整數,為方便3D動畫的處理,CUDA允許定義為3維的結構(x/y/z),區塊也是一樣,程式碼如下,x=5, y=4, z=1:
dim3 dimBlock(5, 4, 1);
gpu_inner_product <<<1, dimBlock >>> (d_a, d_b, d_result);
第一個參數也可以是3維的結構,稱為Grid。
z=1 亦即 2D 的概念。
矩陣相乘,通常稱為點積(Dot product)或內積(Inner product),算法如下圖: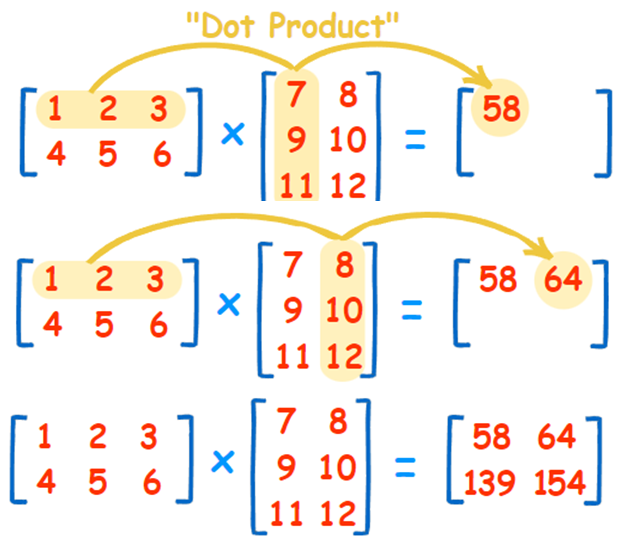
圖三. 矩陣點積(Dot product),圖片來源:『How to Multiply Matrices』
簡單的講,就是輸出所在的格子是第一個輸入矩陣的【列】與第二個輸入矩陣的【行】點積的結果,因此,程式撰寫如下:
#define A_ROW_SIZE 5
#define A_COLUMN_SIZE 4
#define B_ROW_SIZE 4
#define B_COLUMN_SIZE 3
// 輸出所在格子的座標
int row = threadIdx.x;
int col = threadIdx.y;
// 點積
for (int k = 0; k < A_COLUMN_SIZE; k++)
{
// 第一個輸入矩陣的【列】與第二個輸入矩陣的【行】相乘
d_c[row * B_COLUMN_SIZE + col] += d_a[row * A_COLUMN_SIZE + k] *
d_b[k * B_COLUMN_SIZE + col];
}
透過多維執行緒的設定,就可以免除2D/3D轉為1D的計算,只可惜一個區塊最大執行緒只有1024,碰到較大的矩陣還是會爆掉,不過,還是可以解決,只是比較麻煩一點,讀者可以想想看,筆者的想法放在文末。
完整程式放在『GitHub』的InnerProduct目錄。
神網路經的矩陣尺寸通常非常大,例如MNIST,60000筆資料,每筆28x28個像素,相乘起來一定超過1024的限制,因此,每個執行緒就必須負責一個區塊的計算,而不僅僅是單格而已,這時就可以使用區塊的多維設定,可以參閱『CUDA - Matrix Multiplication』說明。
 I code so I am
I code so I am
