理想是美好的,但現實是骨感的。上一篇只能說是”基本到不行的資料庫設計”,聊天軟體的Fan-out是很可怕的,考驗工程師的能力。
(如果你寫的東西,用戶多,就是標準的高病發高流量~)
對於聊天軟體而言,聊天室活躍的用戶數、每秒傳給伺服器的請求、資料庫讀寫的比率等,都會影響系統的負載,更會影響資料流處理的選擇。
假設訊息用WebSocket推送,那麼推送一筆訊息的流程,大致是:
1.新增訊息request
2.儲存訊息資料
3.找出發送對象的WebSocket
4.推送
以下是幾種儲存訊息資料的模式,先停下來想想自己會怎做吧!
1.每個使用者存一份需要推送的資料
2.每個離線使用者存一份需要的資料
3.存一份完整推送資料,用戶則有待推送的 Id 清單
4.存一份完整推送資料,用戶則有最後一筆推送的 Id
5.其他你的想法
架構有時沒有好壞。Refine, refine, and then Refined.
(1)每個使用者存一份需要推送的資料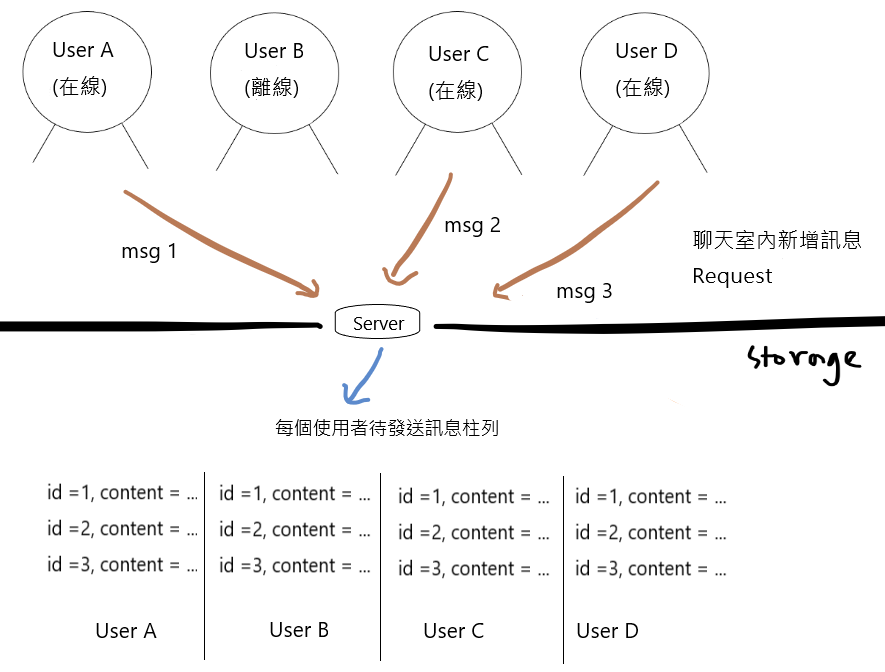
Websocket在推送時,只需要讀取發送對象的待發送 Queue。
這方法最無腦,但做對了一件事,為了預防推送失敗,每個人都有一份備份,不擔心訊息石沉大海。不過,寫入重複、肥大的資料,佔用了儲存空間。讀取時需要耗費的資料傳輸成本也很驚人。
(2)每個離線使用者存一份需要的資料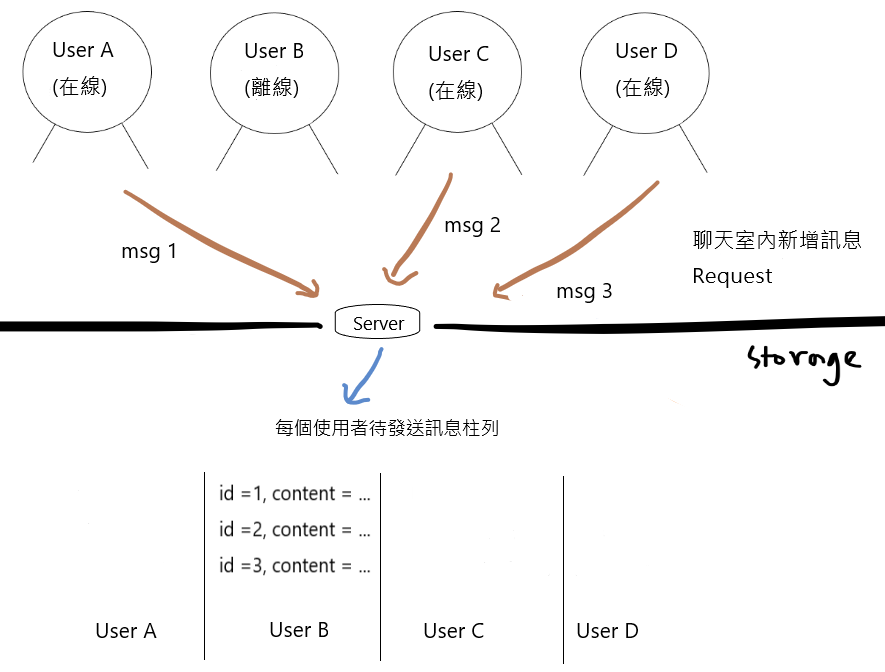
新增訊息 Request 成功送出後,合理的情況是:如果使用者在線上,那馬上就會被推送;而那些沒在線上的,就下次再說。
那麼,Server 只要負責判斷上線狀態,遇到沒有上線的使用者,再把這份消息存起來,省去一部分儲存空間,結束這回合。
缺點就是,那些推送過程消失的訊息,隨風去了。
(3)存一份完整推送資料,用戶則有待推送的 Id 清單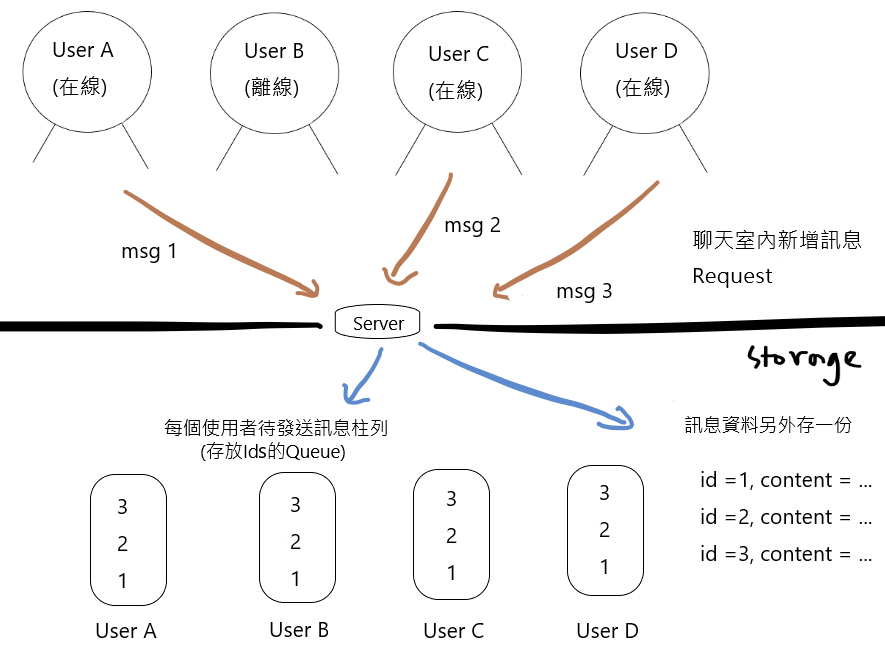
Websocket在推送時,同時需要讀取"訊息資料" 和 "發送對象的待發送 Queue"。
這個方法省去存很多冗餘的訊息資料,用戶的待推送 Id 清單可以搭配 Ack 機制,在使用者端(client) WebSocket 回復收到訊息後,即可移除 Id ,也就確保了訊息有送達。
(4)存一份完整推送資料,用戶則有最後一筆推送的 Id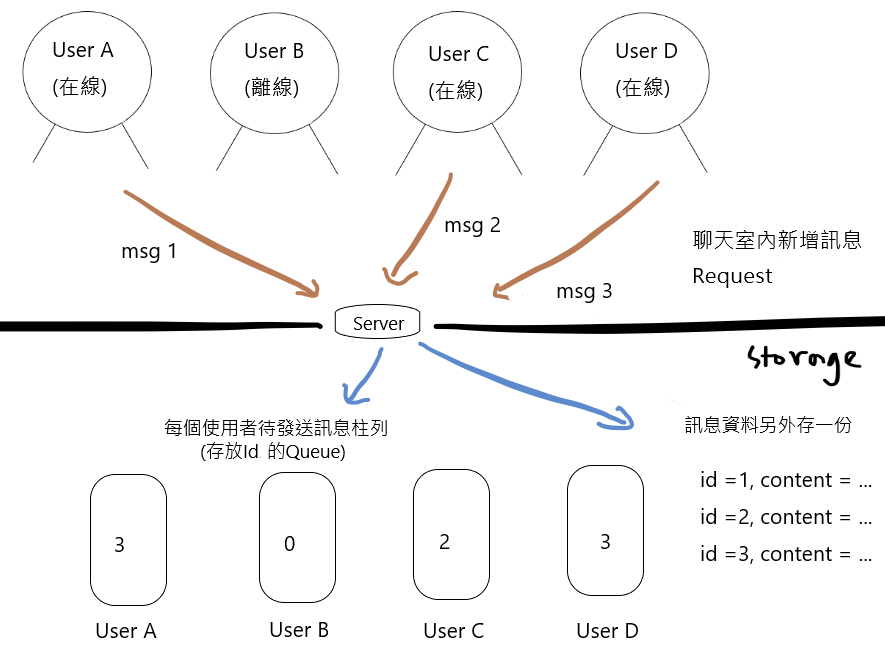
除了省去存重複資料,接受後也只需要更新一個值,之後只推送大於該值的訊息。聽起來是很理想,但也要看需要推送的 Id 是否連續等。需求決定一切。
(5)歡迎討論~
上一篇: 聊天軟體實作(1): 從資料儲存開始
 wowlol
wowlol

 iThome鐵人賽
iThome鐵人賽