今天主要介紹 NLP 任務中常用的統計方法。大家是否會覺得很神奇,明明主要是處理文字,為什麼在 NLP 中會用到統計方法呢?其實是因為 NLP 涵蓋的研究範圍很廣,包含信息檢索(information retrieval)和文本探勘(text mining)等。在處理這些語料和文本時,找出重要且關鍵的單詞或文句是不可或缺的項目。而為了確認文字的重要性,我們需要將文字進行量化,以利後續處理及篩選。當然,將文字量化的方式不少,其中 Bag of Word 以及 TF-IDF 是現今 NLP 任務中較為常用的方式,以下將逐一介紹。
詞袋的概念非常非常的簡單且直觀,想像現在你手邊有一篇文章,你將文章中所有出現的字詞整理好 (斷詞),丟進一個袋子中,不分字詞出現的先後順序。如此一來,就可以整理出一個表,表中包含文章中出現了哪些詞與這些字詞在文章中出現的次數。這就是詞袋最主要的概念,是不是很簡單呢?這邊簡單舉個例子:
"I went to Taipei yesterday and I will go to Taipei again next month." 這個句子被丟入詞袋中的字分別是 "I, went, to, Taipei, yesterday, and, will, go, again, next, month, ."
最後整理出來的表會是:
"I", 2
"went", 1
"to", 2
"Taipei", 2
"yesterday", 1
"and", 1
"will", 1
"go", 1
"again", 1
"next", 1
"month", 1
".",1
中文的 BoW 也是一樣的概念~
TF-IDF 全名為 Term Frequency-Inverse Document Frequency,是一種評估一個字詞對於一個語料庫(corpus)中或文件(document)的重要程度的方法。TF-IDF 由兩個部分組成:詞頻(Term Frequecny, TF)與逆向文件頻率(Inverse Document Frequency, IDF)。文件是由單詞構成,語料庫是多份文件的集合。
「詞頻」就是單詞出現在一份文件的頻率。若某一單詞在一份文件當中出現的次數越多,一般來說我們會認定它愈是重要。但是,次數並不是絕對,因為文件的篇幅也會影響到重要性。因此,在計算詞頻時,需要進行正規化(normalization)。也就是將「次數」除以文件長度,即「頻率」。下圖是詞頻計算方式的公式
t: 單詞
d: 文件
詞頻看似已經考慮到「篇幅」的問題並做出改正了,然而,有許多單詞的詞頻非常高,卻不具重要性,就是我們之前有提到過的 stop words。因此,僅僅使用詞頻仍不足以衡量字詞在文本中的重要程度,單詞對於語料庫的重要程度也需要列入考量。某一特定詞語的 idf,可以由總 corpus 數除以包含該詞語之檔案的數目,再將得到的商取以底數為 10 的 log 得到:其公式如下:
idf(t) = log(N/(df + 1))
t: 單詞
df: 文件
N: corpus 總數
有了 TF 和 IDF 之後,我們就能夠計算 TF-IDF 了!TF-IDF 的公式就是 TF * IDF
TF-IDF 多用於提取文本的特徵,即關鍵詞。字詞的隨著它在文件中出現的次數成正比增加,同時會隨著它在語庫中的頻率成反比下降。因此,某一特定文件內的高詞語頻率,以及該詞語在整個 corpus 中的低檔案頻率,可以產生出高權重的 TF-IDF。所以,TF-IDF 傾向於過濾掉常見的詞語,保留重要的詞語。
接下來,就R 來示範如何製作 TF-IDF 的表格吧!
library(ggplot2)
library(tm)
dataset_link <- "https://www.cs.cornell.edu/people/pabo/movie-review-data/review_polarity.tar.gz"
download.file(dataset_link, destfile = 'tmp.tar.gz') # 從 Kaggle 上下載檔案
untar('tmp.tar.gz') # 解壓縮
path = "./txt_sentoken/" # 引入解完壓縮的檔案
dir = DirSource(paste(path,"pos/",sep=""), encoding = "UTF-8")
corpus = Corpus(dir) # 製作成 corpus
dtm = DocumentTermMatrix(corpus,
control = list(weighting = weightTfIdf,
stopwords = stopwords(),
removePunctuation = T,
removeNumbers = T,
stemming = T)) # 製作成 dtm
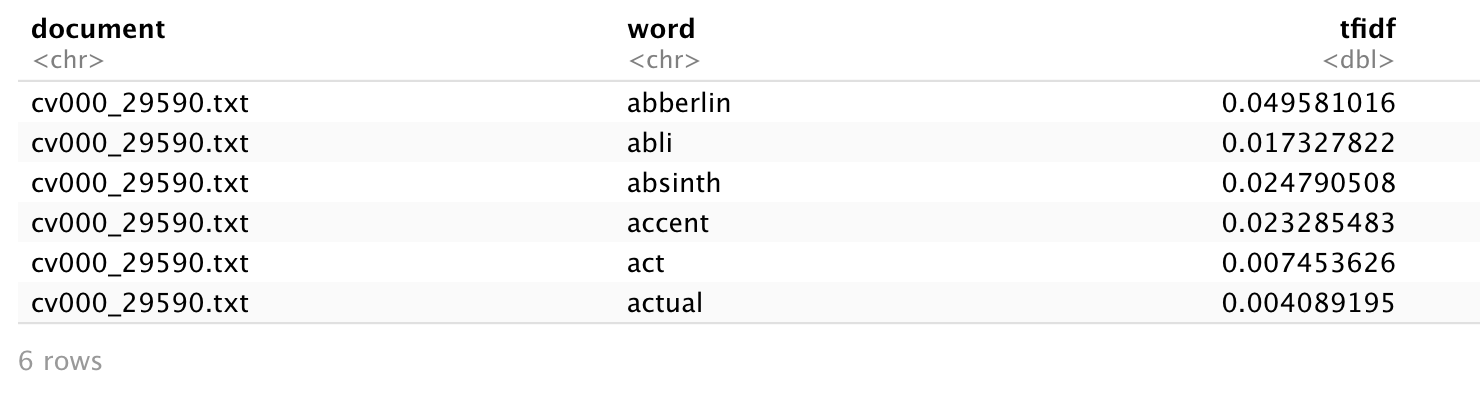
small_docs <- dtm[1:3,] 選擇前 3 份文件來寫成 TF-IDF table
three_docs <- tidy(small_docs)
names(three_docs) <- c('document', 'word', 'tfidf')
head(three_docs) # 看一下前 6 筆數據
執行結果為:
那麼,今天就先介紹到這邊,希望大家都能成功做出 TF-IDF 的表格喔!



 iThome鐵人賽
iThome鐵人賽