有趣的文章可以看一下MySQL和MariaDB的愛恨糾葛(?)
簡單梳理操作方式
成功存入MariaDB/MySQL
用SQL語法篩選不重複資料/降冪排序/Order by...(把前幾天問題用SQL語法試著解解看)
DAY10時間跑出的結果(if any)
今天使用的是免費的開源軟體HeidiSQL,它可以支援連線、存取MariaDB, MySQL, Microsoft SQL, PostgreSQL 和 SQLite。如果有想要下載者可以點這邊。
由於HeidiSQL是我初學程式的時候一步一步跟著台上課程助教操作的,有點想不起來需要先設定哪些項目,這次也就先不逐一討論或分開解釋(有查些資料,名詞有點超出我目前的理解範圍哈哈)。
但大概閱讀過官方文件後,看起來需要先設定好連線條件(包含用戶、通訊埠(Port)號碼、密碼等,剛下載以上資料庫是沒有密碼的故要先自訂),在Port的部分,官方文件中有說明預設是3306。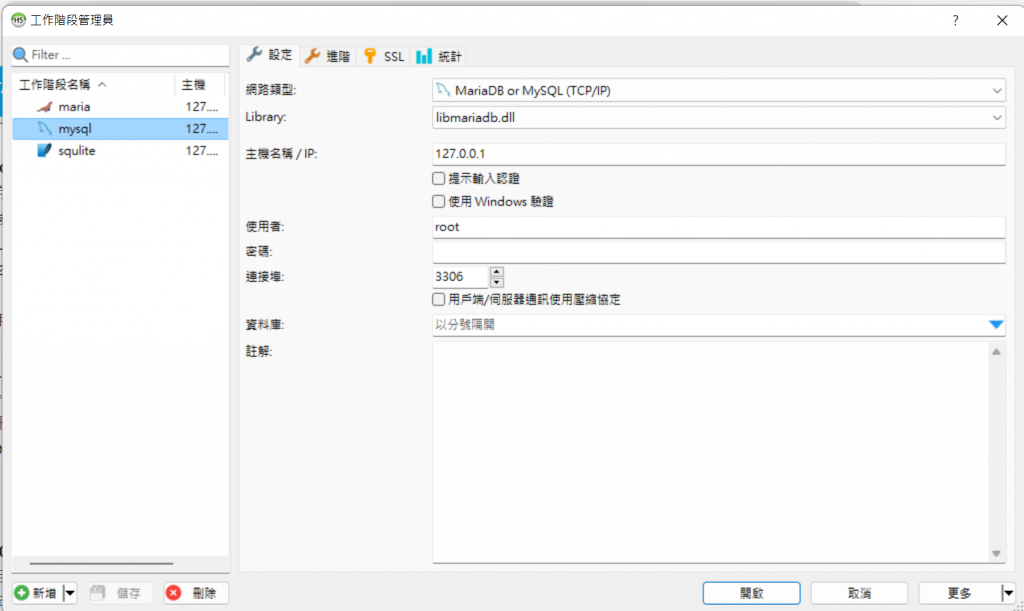
介面大概長這樣,工作階段管理員(Session Manager)可以看到你目前設定的連線。
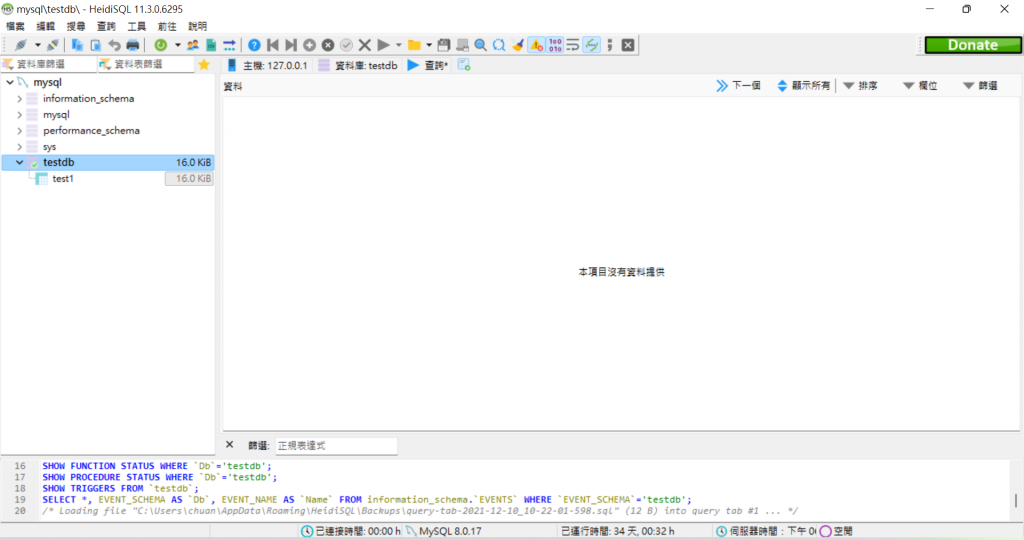
輸入密碼後點就去會長這樣,還看到之前設定的資料庫(在左邊的那個testdb),如果要新增資料庫的話可以直接在MYSQL標題那邊按右鍵,就可以了!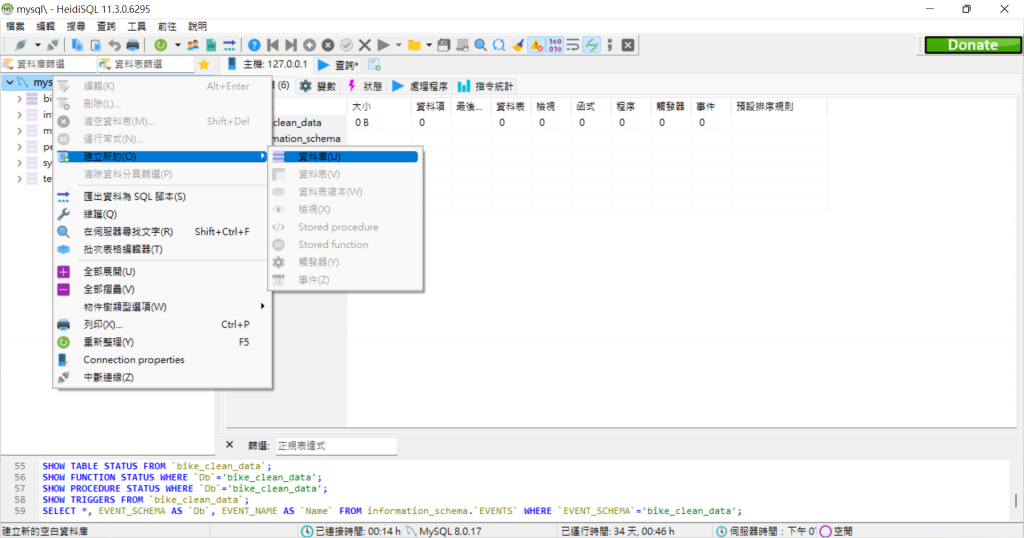
類似像這樣,我新創建了一個名稱是【bike_clean_data】的資料庫
現在回到Python來把資料存進去!一樣是存取去除含有'###..'列的資料。
先進行事前測試,看是否順利將範例順利連線。匯入pymysql套件後,進行連線、建立cursor物件、執行。
(note: A cursor is an object which helps to execute the query and fetch the records from the database. --Linux Hint)
import pymysql
# 連線資料庫
db1 = pymysql.connect(host = "127.0.0.1",
user = "root",
passwd = "12345678",
database = "testdb",
port = 3306)
cursor = db1.cursor()
cursor.execute("SELECT VERSION()")
data = cursor.fetchone()
print ("使用MySQLdb連線的資料庫版本為 : %s " % data)
#確認資料表是否存在
cursor.execute("DROP TABLE IF EXISTS EMPLOYEE_A")
#創建資料表
sql1 = """CREATE TABLE EMPLOYEE_A (
FIRST_NAME CHAR(20) NOT NULL,
LAST_NAME CHAR(20),
AGE INT,
SEX CHAR(1),
INCOME FLOAT )"""
cursor.execute(sql1)
db1.close()
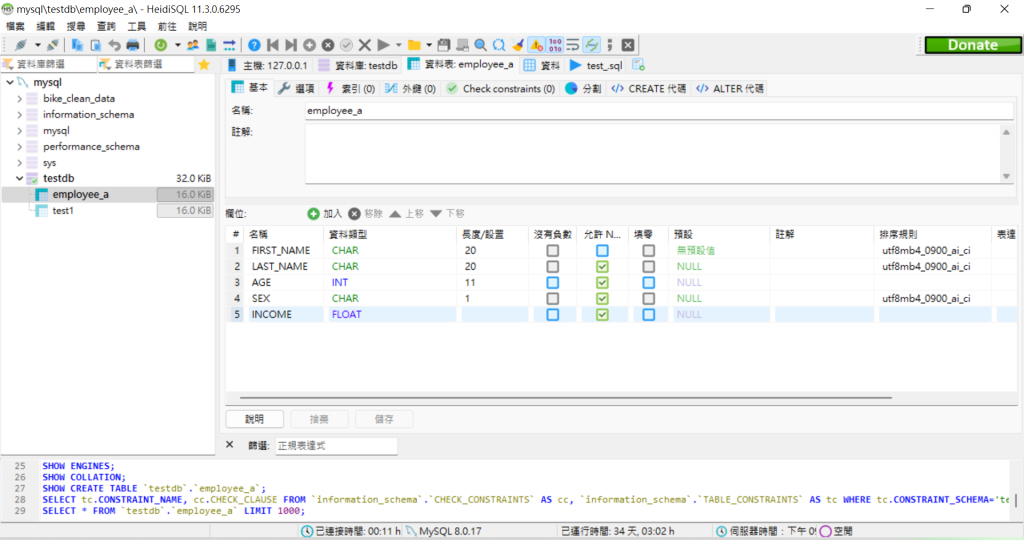
close()後重打開就看到被創建了
如法炮製修一下格式,把這次的資料存進去!結果出現錯誤訊息
df1.to_sql('bike_clean_data',db1,if_exists='replace',index=True)
db1.close()
##
DatabaseError: Execution failed on sql: SELECT name FROM sqlite_master WHERE type='table' AND name=?;
not all arguments converted during string formatting
unable to rollback
查了一些網路資源,發現需要搭配sqlalchemy引擎(用來初始化連線),就添加了一些程式進去,似乎原本下載的Anaconda中就有包含這個套件,可以執行pip list來檢查一下。添加幾行後就成功了:
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://root:12345678@localhost:3306/bike_clean_data')
df1.to_sql('clean_data',engine,if_exists='replace',index=True)
db1.close()
明天會用一些基本的SQL語法來練習一下前面在Python中分析過的內容
SQL語法練習
統整目前資訊
還有何未解或洞見?
決定好要用的視覺化圖表
明天見^^!

