在如今這個FaceID 人臉識別、車牌辨識、手寫數字識別無處不在的世界,大家似乎也早已習慣深度學習在影像識別的成功,在 2021 年 Google AI 釋出的影像識別模型,就已經在 ImageNet 資料集就達到 90.2% 的 Top1 和 98.8% 的 Top5 準確率[1]。
然而早在 2014 年,MIT 的研究學者就曾經用下面這隻,相信大家應該在很多介紹對抗攻擊(Adversarial Attack)的資料中都曾經看過的熊貓,指出這些神經網路也許不如我們想像中的可靠。
只要在輸入的圖像中加入微弱的、人類肉眼無法察覺的擾動,就能讓模型將「熊貓」認成毫不相似的「長臂猿」(Gibbon),而且 confidence 還高達 99.3% [2]。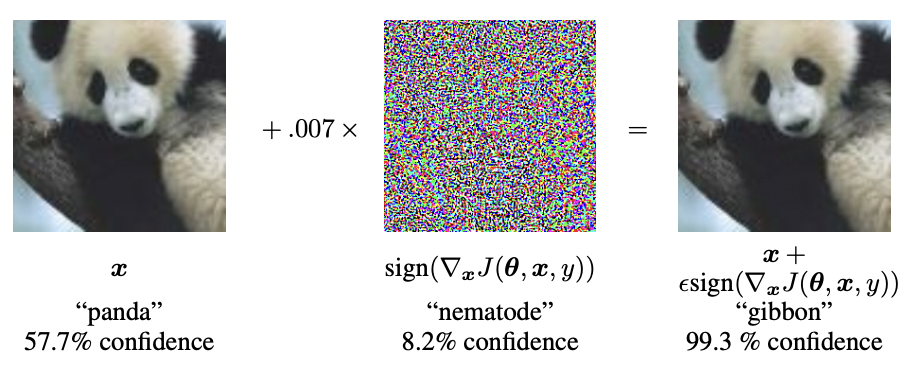
那麼問題來了,這些會誘導模型的噪聲,究竟是如何產生的呢?
這些擾動並不是隨機添加的,而是透過特定的算法計算生成。
在 Black Box Attack 中,大家常見的算法有 FGSM 及 I-FGSM, MI-FGSM, DIM-MIFGSM。
這四種算法之後也許我會再更新他們各自的介紹,尤其側重 DIM-MIFGSM,因為我是用它加上 ensemble attack 來打敗 Homework 10 的 Boss Baseline。不過今天想跟大家分享的反倒不是這些攻擊算法,而是在做 HW10 的 Black Box Attack 中,我是如何選擇 proxy models 的策略。
在 HW10 中,TA 有一個已經 train 好並加上基本防禦的圖像分類模型,但我們身為邪惡的攻擊者,其實掌握的資訊非常有限,我們不知道 TA model 的架構或參數,我們唯一知道的事情是,它是用 CIFAR 10 這個 dataset 訓練的。因此我們要做的事情,就是同樣用這些資料來訓練 proxy model(s) 以模擬 TA 的 model,然後將攻擊算法冷酷無情地使用在這些圖片上來產生噪點,使得這些被加工過的圖片不僅可以騙過我們的 proxy model(s),也能騙過 TA 的 target model。
由於我們並不知道 TA 的 target model 到底是什麼,為了避免我們為圖片生成的噪點把自己的 proxy model 攻擊得毫無招架之力,但是卻對 target model 效果平平,我們可以使用 ensemble attack 的技巧來增加 black box attack 的 transferability [3]。
一個快速又方便的做法就是在 Pytorchcv 所提供的一系列預訓練模型中,挑選合適的模型來組成我們的 proxy model list,之後再選擇一個攻擊算法(我這邊選擇的是 DIM-MIFGSM),最後再對 proxy model list 中的模型同時發起攻擊。
然而 Pytorchcv 提供了數以百計的 pre-trained model,難道我們要全部都用嗎?
其實如果時間夠多的話可以,就全部都選然後慢慢跑;但如果你跟我一樣老是拖到最後一天才開始趕作業的話,我建議你還是要想想看有什麼聰明的辦法。
最後拯救我的是這篇 2020 年發表在 arxiv 上的這篇 paper: Query-Free Adversarial Transfer via Undertrained Surrogates [4]。
他們在實驗中發現,透過 undertraining porxy model ,可以提升實際攻擊 target model 的成功率,而所謂的 undertrain,其實就是透過「訓練少一點的 epoch」就可以達成。因為降低 training epoch 的過程,其實就可以視作在降低 decision boundary 的複雜度,並減少 overfitting 的程度,進而提升 black box attack 的 transferability。
但是看到這邊,似乎對我們的 HW10 沒有什麼太大幫助。
因為 torchcv 上面提供的都是 pre-trained 好的模型啊啊啊啊!他們也沒有放在不同 epoch 數量訓練下的模型給我用呀!
那我們要怎麼利用這篇 paper 的 insights 來轉化到這次的作業中呢?
torchcv 上有許多不同架構的模型,其中不乏使用相同架構但是層數不同的 pre-trained model。既然目標是挑出 decision boundary complexity 較低的 model,那就找層數少的那些就可以了!
所以我最後就在同樣 pre-trained 在 CIFAR-10 這個 dataset 上的模型中,挑選不同系列他們各自層數最少的 model ,出來組成我的 proxy model list,最後輕鬆通過 boss baseline。
以下是我當初選擇的 models:
['nin_cifar10', 'resnet20_cifar10', 'preresnet20_cifar10', 'seresnet20_cifar10',
'sepreresnet20_cifar10', 'pyramidnet110_a48_cifar10', 'densenet40_k12_cifar10', 'xdensenet40_2_k24_bc_cifar10', 'wrn16_10_cifar10',
'wrn20_10_1bit_cifar10', 'ror3_56_cifar10', 'rir_cifar10', 'resnext29_16x64d_cifar10', 'diaresnet20_cifar10', 'diapreresnet20_cifar10']
後記:
個人覺得,在這次作業中最好玩的部分,是終於想通如何轉化 paper 的 insights 到自己當前問題的那個啊哈 moment。
參考資料:


 iThome鐵人賽
iThome鐵人賽