
Adam 作為我最常使用的 Optimizer,就算無腦直接用,參數也直接用 default setting 的,常常結果也還不錯。但後來發現在訓練 Transformer based 的 model 或是 BERT based 的 model 時,除了需要設定 optimizer 之外,也經常需要額外設定 learning rate scheduler 和 warm-up 的參數。這時心中不免疑惑:不是說 Adam 可以為每個參數自適應 learning rate 嗎?那為什麼我還需要加 scheduler 和 warm-up 這些花裡胡哨的東西呢?而且加了好像還真的效果不錯呢。
時間回推到上古時代,那時候不管 model 有多少參數,人們只會為這些參數設定一個共同的 learning rate,然後從頭用到尾。Train 到一個階段之後發現 training loss 已經收斂不再下降,以為 model 已經收斂到 critical points(local minimum 或是 saddle point),但是畫出訓練過程中的 gradient norm 卻發現 gradient 根本就還不是 0 啊,即便在後面 training loss 已經收斂的階段,gradient norm 仍然有不少波動。
那是什麼導致 model 止步於此了呢?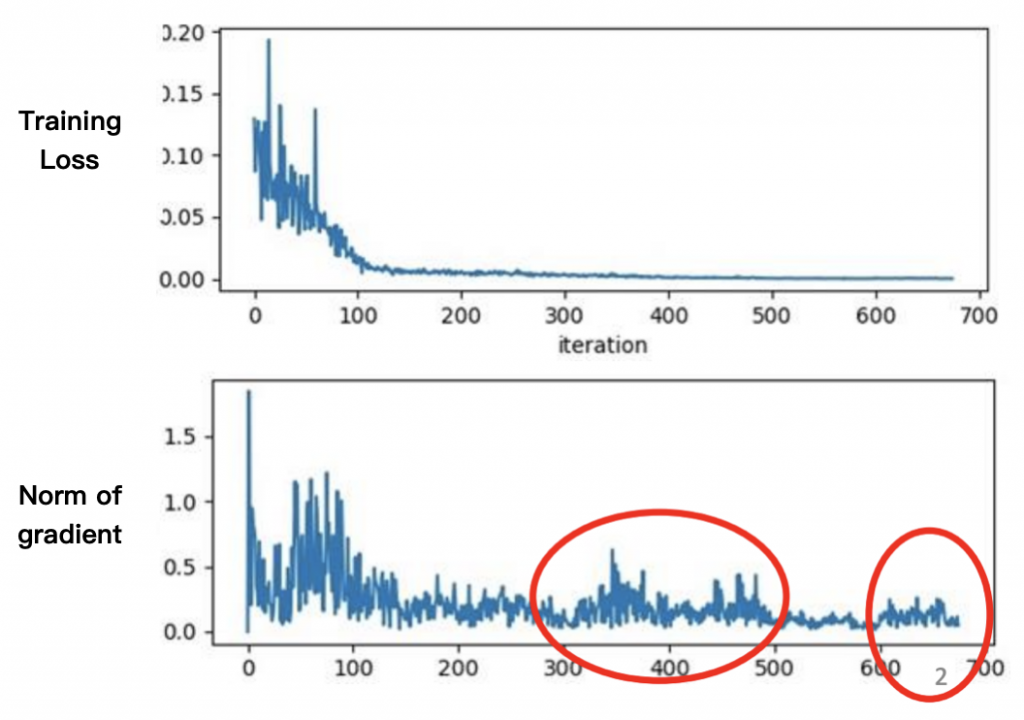
可能是 learning rate 太大了,導致 gradient 在進入 critical points 前,就卡在 error surface 的兩個山壁之間來回震盪......最終一樣會導致我們 train 不下去了。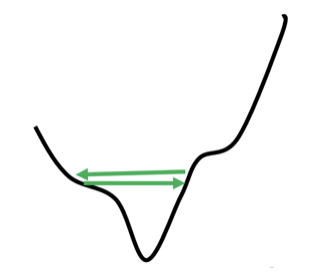
那如果我們就把 learning rate 調小一點,問題是不是就解決了呢?
下圖是一個 convex 的 error surface,左邊我們先用 10^-2 當作 learning rate 的大小試試看,顯然太大了,出現震盪的狀況。那如果改成右邊 10^-7 這個小的數值呢?震盪的問題是解決了,但是好像永遠走不到終點,光是走到中間較為平滑的地方,就已經走了 100,000 的 steps了,走到目的地不知道是猴年馬月了......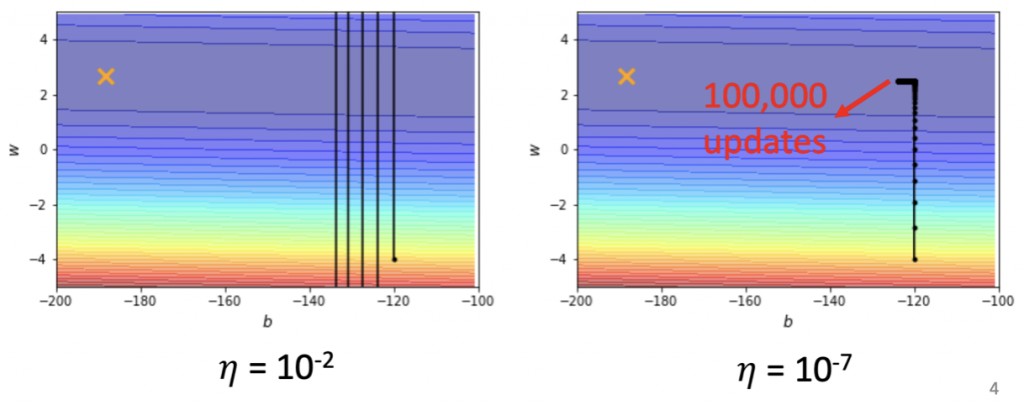
所以有人提出一個想法,也許每個 parameter 都應該要有自己的 learning rate。
舉例來說,假設我們考慮一個只有 w1, w2 兩個參數的模型,從下面的 error surface 可以看出 w2 要走的路是一個比較崎嶇的地形,應該採用較小的 learning rate 步步為營;而 w1 要走的則是一個較為平緩的地方,這時候可以用較大的 learning rate 來加速訓練。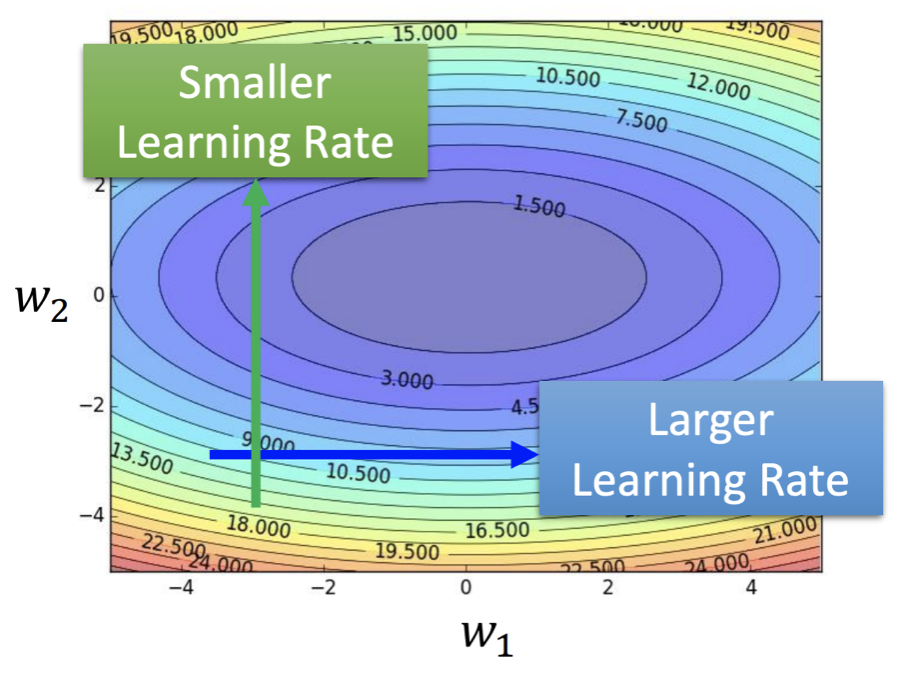
那麼我們要怎麼為每個 parameter 客製化他的 learning rate 呢?
可以透過調整 來得到。
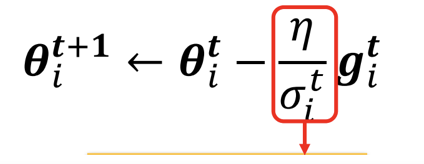
調整 的策略有許多種,以下介紹 Adagrad, RMSProp 和 Adam,這三種都是會 self-adjusted learning rate 的方法。
Adagrad 的做法就是在每個參數更新時,都會在下方除上該個參數過去所有 gradient 的 root mean square。

為什麼樣這樣設計呢?舉例來說, 的 error surface 其實是相較
平緩的,此時
的 gradient 也會比較小,放到分母反而會讓最後得到的 learning rate 比
的還要大,得到我們預期的效果:平緩的地方,gradient 較小, learning rate 反而要調大,加速前進不然會走到天荒地老;崎嶇的地方,gradient 較大,learning rate 反而要調小慢慢走。

然而這樣也許還不夠......。我們發現即使只看一個 parameter 的 error surface 也可能非常複雜,不同時間所需要使用的 learning 大小差異很大。比方說下方的 w1,在走到綠色箭頭那個地方時,剛好進入一個崎嶇的地表,需要使用較小的 learning rate,然而到橘色的平緩區域,卻又要改用較大的 learning rate。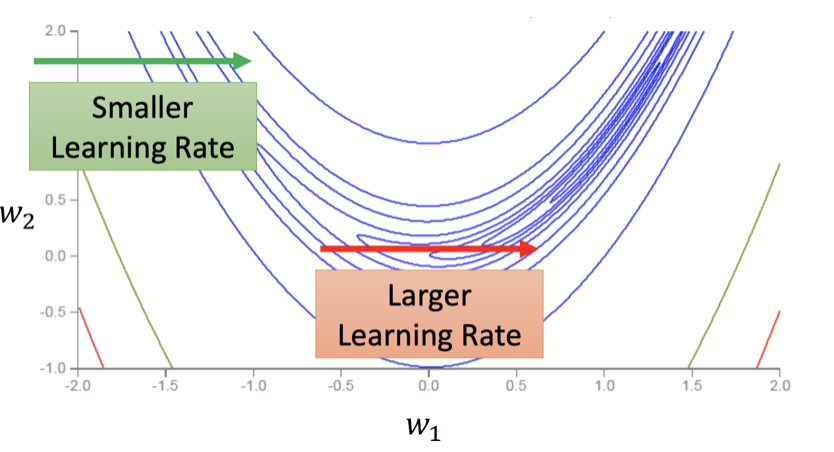
但因為 Adagrad 會將過去以及現在所有的 gradient 平方後一起平均,也就是說每個時間點的 gradient 對決定當前 learning rate 的大小是同樣重要的,面對上圖這種比較劇烈的變化,他有辦法即時反應並調整 learning rate 嗎?
RMSProp 就是基於 Adagrad 的算法,引入一個新的 hyperparameter ,介於 0~1 之間,來調整過去所有 gradient 和當前 gradient 的比重。
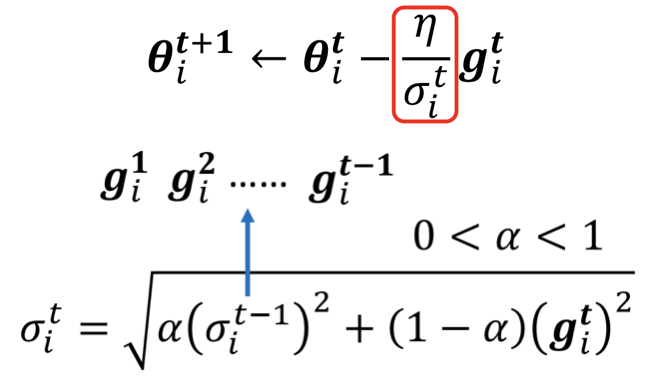
直覺上,當前的 gradient 應該要比過去更具有影響力。
所以面臨下面的狀況時,RMSProp 應該會比 Adagrad 更快做出反應,更即時地 increase/decrease learning rate 的大小。
Adam 其實就是 RMSProp 與 Momentum 結合之下的產物。
有 四個參數需要調整。

介紹完這些 adaptive learning rate 的策略後,看起來已經很棒都考慮很多層面的問題了,所以我們為什麼還需要 learning rate scheduler 呢?
以剛剛同樣的 convex error surface 來看使用 Adagrad 會有什麼樣的結果。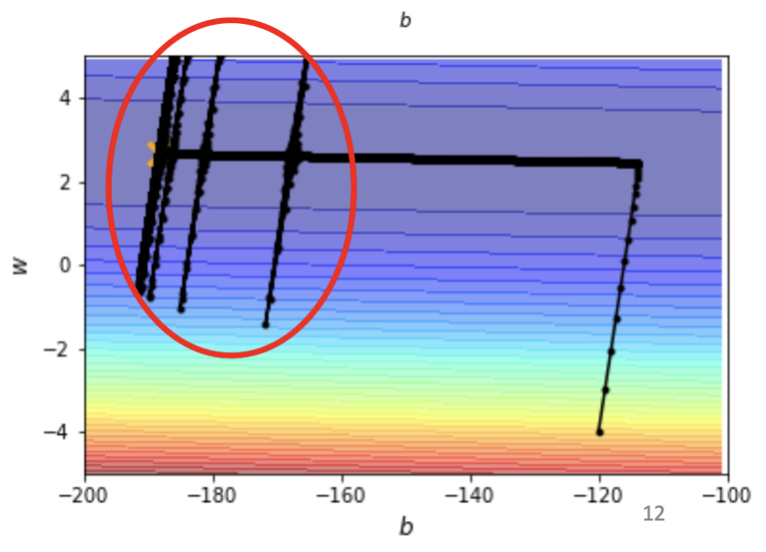
這次看起來終於是順利走到終點了,但是後面紅色圈圈大暴走是怎麼回事?
因為 Adagrad 在中間平坦的地方走了一段時間後,積累了一陣子,learning rate 逐漸變大,之後在紅色圈圈那邊就噴走了,又開始進入震盪模式......
於是人們又開始思考要如何解決這個問題。
直覺上,到訓練後期,model 應該已經要很接近 local minimum 了,這時候應該要逐步減小 learning rate ,緩步前進,以避免前面提到在 error surface 的山壁之間震盪的問題。
所以有人提出 learning rate decay 的想法。
也就是在更新 parameter 的 formular 中,隨著時間逐步縮小 的值,以達到慢慢減小 learning rate 避免發生上圖 Adagrad 到後期突然又大爆走的狀況。
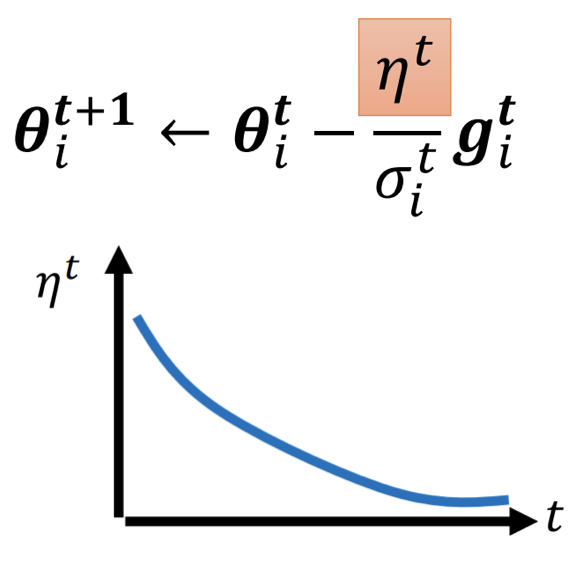
那麼,有了會 self-adjusted 的 optimizer(如:Adagrad, Adam),我還需要 learning rate scheduler 嗎?
我們以 Adam 為例。
在 ADAM: A METHOD FOR STOCHASTIC OPTIMIZATION 這篇 paper 的 section 2.1 中,提到其實我們使用 Adam 前設定的 ,在大多數情況下,就是每個 parameter 的 learning rate upper bound。也就是說不管 Adam 在過程中怎麼調整,learning rate 都不會超過
。
The effective magnitude of the steps taken in parameter space at each are approximately bounded by the stepsize setting α.
所以透過 scheduler 隨著時間不斷調整 的值,其實也就是同步在縮小每個 parameter 在當前的 learning rate 的 upper bound。
這一點在訓練後期往往會發生還不錯的作用,因為可以保證接下來的 step size 都會比較小,並且會越來越小,某種程度上可以避免發生暴走情形,以幫助 model 找到 minima。
參考資料:

 iThome鐵人賽
iThome鐵人賽