本文有整理在部落格裡。
裡面還有其他奇怪的文章,有空可以來看看喔。
一般來說,之前介紹過的request就能應付大部分簡單的爬蟲,但是現在大部分的網頁都具備互動式設計等較為複雜的架構,通常為java渲染,而遇到這種情況,單單的request和beautifulsoup4(隔天會提到)是無法滿足我們爬蟲的需求的。因此,我們就需要借助selenium的力量。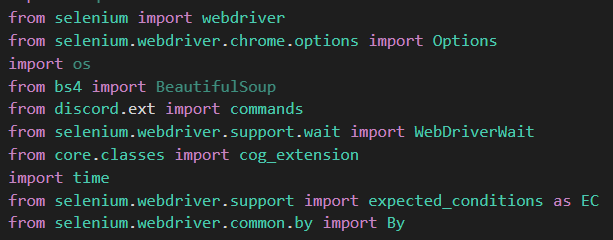
(selenium的import範例)
我們可以將selenium想成是一種自動網頁模擬器,一般而言,互動式網頁難以用一般爬蟲抓取資料的原因即是因為網頁並不是一次載入完成,網站內容也會隨著使用者的行為而改變,此時,selenium就能夠模擬一般使用者的操作,進行開啟網頁、點擊、滾動、打字等行為,以使網頁有相對應的回應,我們也才能夠爬到預期中的資料。
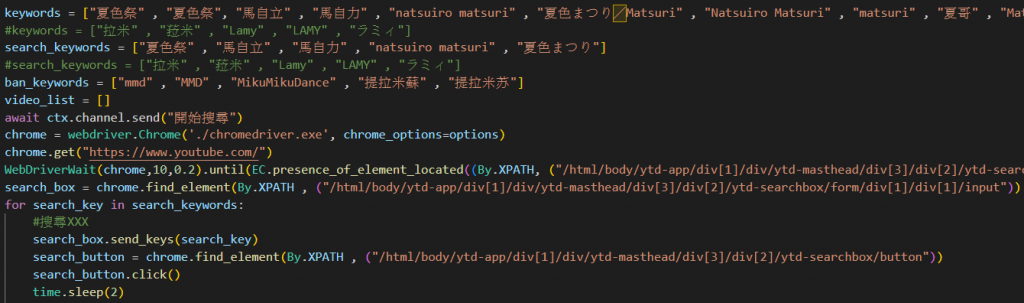
(selenium使用範例)
關於相關code與使用我們之後會再進行更深入的介紹。

 iThome鐵人賽
iThome鐵人賽