自 Self-Attention 被提出來後,基於它的變種就如雨後春筍般出現在各大 conference 上。因為在計算 attention matrix 時往往需要 O(N^2) 的複雜度,當 input 是長文本或是影像時,往往需要耗費大量的運算資源,所以短短幾年之間,就有各式各樣的文章在討論要如何改良 self-attention 的機制,讓它更有效率。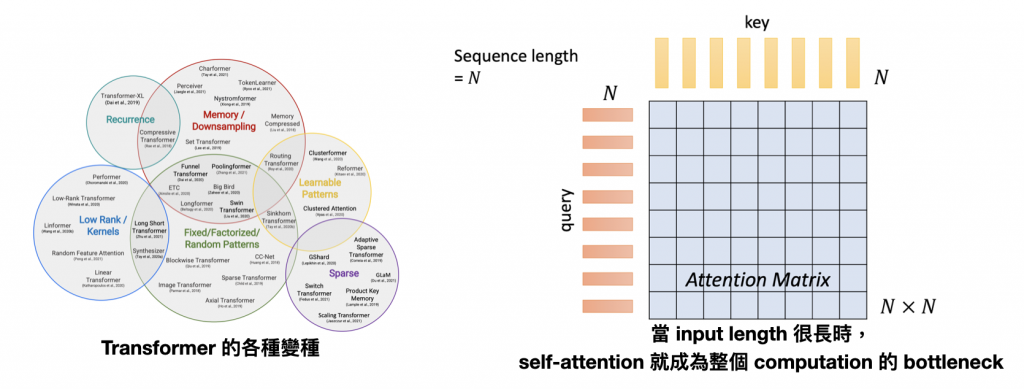
一個最直接的想法是,我們可不可以不要把這個 N*N 的矩陣裡面的所有數值都算完,就根據經驗挑一些比較重要的出來算就好了呢?
在某些問題,也許我們只需要像 CNN 一樣看左右鄰居的資訊就足夠了,其他距離自己太遠的東西我們就直接忽略不計就好了。所以這樣的 attention matrix 就會長得像下圖,每個 query 都只會跟左右相鄰的 key 計算 attention weight,也就是藍色的部分;其他則都設成 0,透過這種方式來加速運算。
如果希望更有彈性的規劃 attention matrix 中需要計算的東西,那可以採用 stride attention 的策略,就是自由指定到底要和自己間隔多遠的 key 計算 attention weight。
但是上述兩種做法都只能 attend 到局部的資訊,如果還是希望可以掌握全局資訊,又不想像最初 self-attention 的 KQV 耗費 O(N^2) 的複雜度的話,可以在 input sequence 中加入 special token,由它來代表整個 sequence 的資訊就好,由它去跟所有的 token 計算 attention weight,而其他所有的 token 也都會跟他計算到彼此的 attention weight。
所以 Global Attention 的 attention matrix 就會長得像是下面這張圖。前面兩個 row 代表 special token 會跟所有其他的 token 計算 attention weight,所以這兩個 row 都會有數值;而其他的 row 就是一般的 Input token,只會跟 special token 計算 attention weight 而已,一般 token 和其他一般 token 之間的分數會被直接設成 0 忽略不計。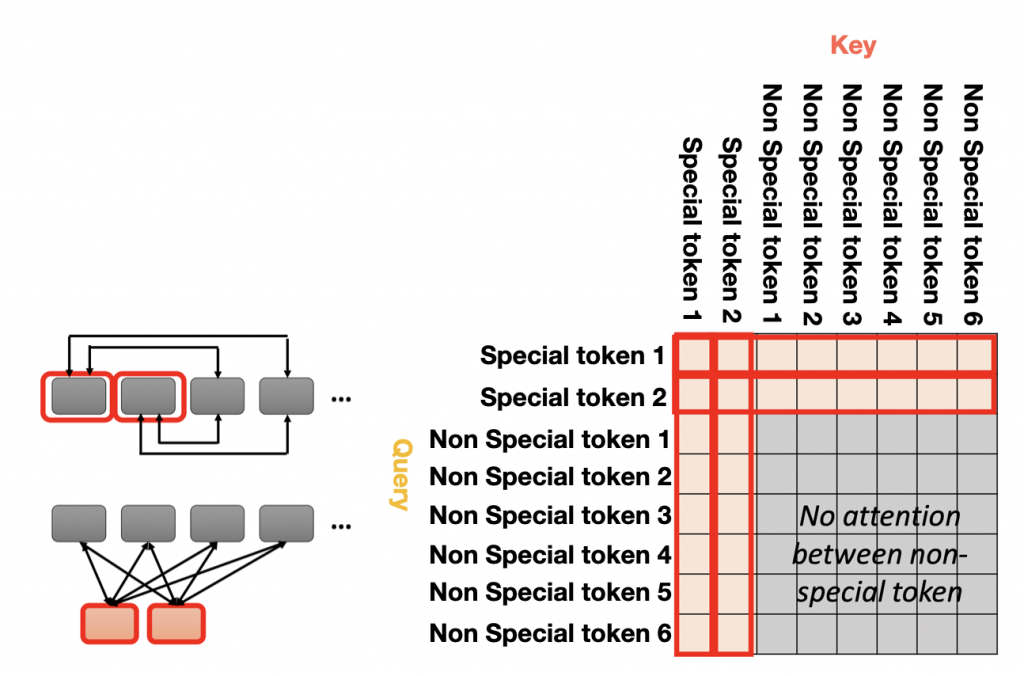
在 Longformer 和 Big Bird 這兩種架構中,就混用了上述的不同 attention 策略。其中 BigBird 還加入一個 random attention 的機制,其實就是 random 選擇需要計算的 query-key pair。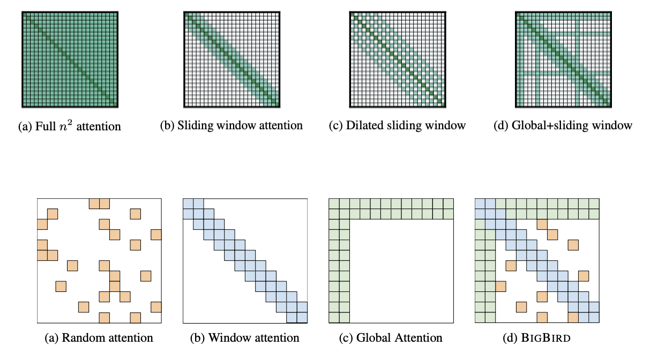
但是在上述這幾種方法,都還是要人為依據 domain knowledge 來選擇或組合某些特定的 rule,例如是要看左右鄰居、還是看間隔三格的鄰居,然後接下來的每一組 data 都用固定的方式來計算 attention matrix。能不能用一些統計的方式,根據每一組 data 的特性,先粗略地來估計有哪些 key 可能和當前的 query 比較不相關,之後算出來的 attention weight 有很大的可能會是一個超小的數值,那乾脆一開始就忽略掉它,直接算那些比較有潛力的 query-key pair 來加快計算。
所以有人提出先幫 query 和 key 做 clustering 的想法。也就是先用某些方法計算出 query 和其他 key 的 similarity,相似度高的被分到一類,然後只在同個 cluster 之間做 attention weight 的計算,不是同個 cluster 的 attention weight 就直接設成 0,這樣也能達到減少運算量的效果。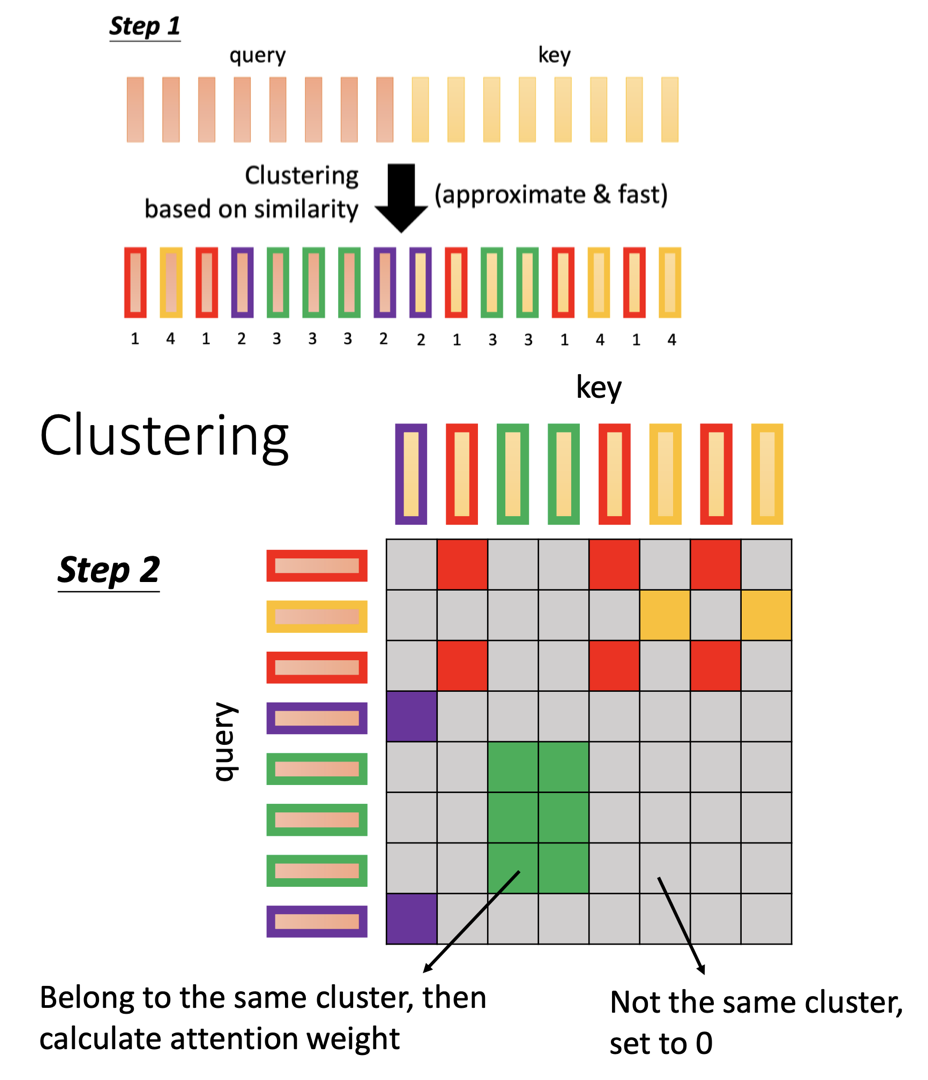
例如在 Reformer 中,他們使用 LOCALITY-SENSITIVE HASHING ATTENTION 的方法先把 query 和 key 聚類,之後再去計算 attention matrix。
接下來,人們開始想,連模型要如何設計他的架構都可以由另外一個模型學出來(NAS),那到底哪些 query-key 之間需要計算,難道不能也用另一個模型學出來嗎?
可以,Sinkhorn Sorting Network 就是基於這樣的構想設計的。
Sinkhorm Sorting Network 就是 jointly 訓練另外一個 NN,這個 NN 在吃進 input sequence 後,會 output 和 attention matrix 一樣大小的 matrix,然後透過某些機制,把其中 continuous 的 value 轉成 binary number,之後這張 binary matrix 就變成 query 和 key 的參照表,其中對應的數字是 1 的 pair 才需要彼此計算 attention weight。
不過,既然最後都還是會有那麼多 query-key pair 被捨棄,那我們為什麼還要維護一張 N*N 那麼大、那麼佔空間的表呢?我們可不可以一開始就把這張大表 prune 掉,然後計算縮小版本的內容就好了呢?
在 Linformer 這篇 paper 中,他們發現 attention matrix 其實是一個 low rank matrix,很多 column 其實可以透過其他 column 做 linear combination 得到。所以我們不如一開始就用某些方法,從這 N 個 key 中只挑選 K 個 key 出來當代表,然後 query 就只需要和這 K 個 key 做計算即可。
其中挑選 representative key 的方法有很多種,在 Compressed Attention 中,他們用 CNN 去掃過這 N個 key 最後壓縮成只有 K 個 key;或是將 d * N 的 query vector 乘上一個 N * K 的矩陣,最後就可以得到 d * K 大小的矩陣,其中每個 column 都是我們新得到的 key。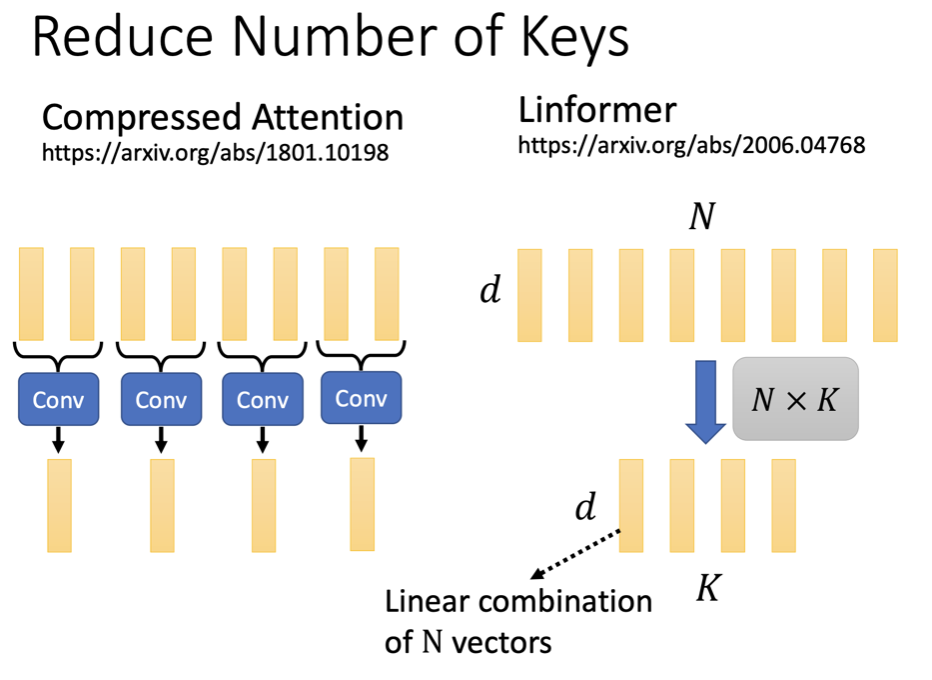
到這邊,既然都已經 key 的數量大幅刪減了,能不能乾脆一不做二不休,直接把 query 和 key 去掉,直接讓 model 自己去學 attention weight 呢?
Synthesize 的其中一個版本,就是把 attention matrix 當作 model parameter 的一部分,直接省去計算 attention weight 的步驟,因為 attention weight 早就已經存在於 model weight 中了。面對不同 input 這邊的 attention weight 都會是一樣的,因為 model weight 一旦 train 好就不會再改變,但有趣的是,這樣 performance 好像沒有比使用原版 self-attention 的 transformer 還要差很多。
也因此,後來也有人開始反思 self-attention 真的有這麼神嗎?它的價值到底是什麼。
於是在 2017 年席捲整個 AI 圈子的 Attention is all you need 之後,google 在 2021 年又發表了一篇 Attention is not all you need,重新檢視 self-attention 的價值。
(關於 Attention is not all you need 的理解之後會再更新)


 iThome鐵人賽
iThome鐵人賽