閒聊
昨天我們爬了PTT八卦版的「是否已滿18歲」的部分,今天會繼續往下爬。
繼續爬的意思就是,照技術上來說,每爬取到一個網頁後就去爬取下一頁的網址(url)。爬取完文章後,再發一個Requests到下一個網址,重複此動作。
預期
當前頁面全部文章爬取並跳過18歲(Day14 已實作),爬取下一頁網址。
向下一頁發送請求,重複此循環。
實作
這時候我們可以先用開發工具找一下下一頁的內容在哪裡,可以找到在btn-group btn-group-paging 的 div 下的第二個子元素 a 的 href 屬性中。(紅色框)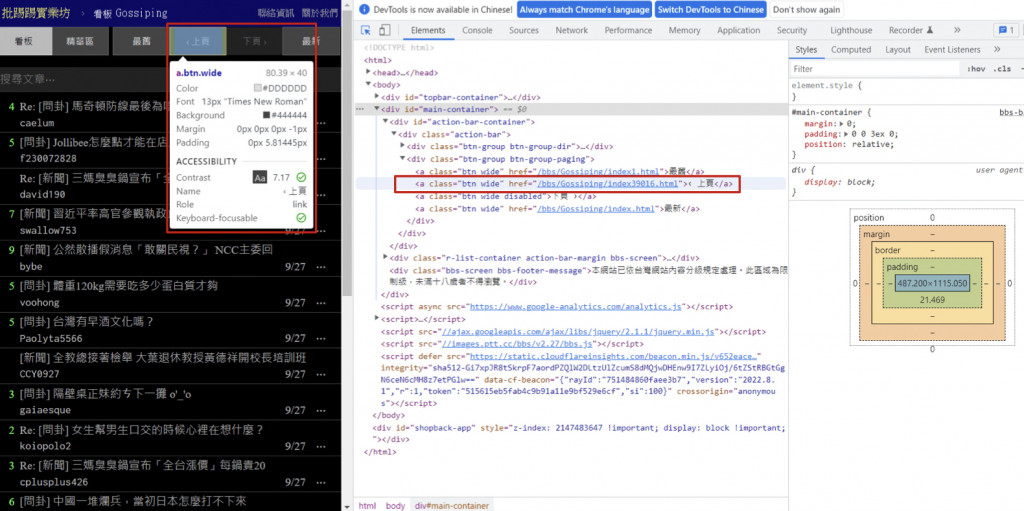
知道在哪裡之後,我們就可以用Day 10學過的Requests-HTML中的Css Selector直接選取到這個元素。
next_url = 'https://www.ptt.cc' + soup.select('#action-bar-container > div > div.btn-group.btn-group-paging > a:nth-child(2)')[0]['href'] #下一頁的網頁位置
接下來之後,我們就可以寫一個迴圈讓這個動作重複。
import requests
from bs4 import BeautifulSoup
url = 'https://www.ptt.cc/bbs/Gossiping/index.html'
def get_r(url):
cookies = {
'over18':1
}
r = requests.get(url, cookies=cookies)
if r.status_code != 200: #200網頁正常
return 'error'
else:
return r
def get_articles(r):
soup = BeautifulSoup(r.text, 'html5lib')
arts = soup.find_all('div', class_='r-ent')
for art in arts:
title = art.find('div', class_='title').getText().strip()
link = 'https://www.ptt.cc' + \
art.find('div', class_='title').a['href'].strip()
author = art.find('div', class_='author').getText().strip()
print(f'title: {title}\nlink: {link}\nauthor: {author}')
# 利用 Css Selector 定位下一頁網址
next_url = 'https://www.ptt.cc' + \
soup.select_one(
'#action-bar-container > div > div.btn-group.btn-group-paging > a:nth-child(2)')['href']
return next_url
# 當執行此程式時成立
if __name__ == '__main__':
# 第一個頁面網址
url = 'https://www.ptt.cc/bbs/Gossiping/index.html'
# 先讓爬蟲爬 10 頁
for now_page_number in range(10):
r = get_r(url)
if r != 'error':
url = get_articles(r)
print(f'======={now_page_number+1}/10=======')
此時如果發現沒有跑出文章連結,那可能是那篇文章可能被刪除了。
這時候可以加一個判斷式,讓程式繼續運行。
title = art.find('div', class = 'title').getText().strip()
if not title.startswith('本文已被刪除') :
link = 'https://www.ptt.cc' + \
art.find('div', class_='title').a['href'].strip()
完整流程
import requests
from bs4 import BeautifulSoup
url = 'https://www.ptt.cc/bbs/Gossiping/index.html'
def get_r(url):
cookies = {
'over18':1
}
r = requests.get(url, cookies=cookies)
if r.status_code != 200: #200網頁正常
return 'error'
else:
return r
def get_articles(r):
soup = BeautifulSoup(r.text, 'html5lib')
arts = soup.find_all('div', class_='r-ent')
for art in arts:
title = art.find('div', class_='title').getText().strip()
if not title.startswith('本文已被刪除') :
link = 'https://www.ptt.cc' + \
art.find('div', class_='title').a['href'].strip()
author = art.find('div', class_='author').getText().strip()
print(f'title: {title}\nlink: {link}\nauthor: {author}')
# 利用 Css Selector 定位下一頁網址
next_url = 'https://www.ptt.cc' + \
soup.select_one(
'#action-bar-container > div > div.btn-group.btn-group-paging > a:nth-child(2)')['href']
return next_url
# 當執行此程式時成立
if __name__ == '__main__':
# 第一個頁面網址
url = 'https://www.ptt.cc/bbs/Gossiping/index.html'
# 先讓爬蟲爬 10 頁
for now_page_number in range(10):
r = get_r(url)
if r != 'error':
url = get_articles(r)
print(f'======={now_page_number+1}/10=======')
結語
比起昨天,今天爬了更多的內容!
明天會繼續爬下去,並且把資料存起來。
明天!
【Day 16】把爬完的資料用JSON儲存吧!(實作PTT 3/3)
參考資料
PTT八卦版https://www.ptt.cc/bbs/Gossiping/index.html

