閒聊
在前面幾天學習後,今天要來試著爬取PTT的八卦版。
今天會用到的工具
預期目標
繞過確認已滿18歲
能夠爬取到當前網頁的文章
實作
import requests
from bs4 import BeautifulSoup
url = 'https://www.ptt.cc/bbs/Gossiping/index.html'
這時候依據剛剛發送請求的url,回應物件(text)。
可以看到,print出來的是「是否滿18歲」,而不是直接看到所有文章的葉面內容(HTML)。
r = requests.get(url)
print(r.text)
#output
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>批踢踢實業坊</title>
<link rel="stylesheet" type="text/css" href="//images.ptt.cc/bbs/v2.27/bbs-common.css">
<link rel="stylesheet" type="text/css" href="//images.ptt.cc/bbs/v2.27/bbs-base.css" media="screen">
<link rel="stylesheet" type="text/css" href="//images.ptt.cc/bbs/v2.27/bbs-custom.css">
<link rel="stylesheet" type="text/css" href="//images.ptt.cc/bbs/v2.27/pushstream.css" media="screen">
<link rel="stylesheet" type="text/css" href="//images.ptt.cc/bbs/v2.27/bbs-print.css" media="print">
</head>
<body>
<div class="bbs-screen bbs-content">
<div class="over18-notice">
<p>本網站已依網站內容分級規定處理</p>
<p>警告︰您即將進入之看板內容需滿十八歲方可瀏覽。</p>
<p>若您尚未年滿十八歲,請點選離開。若您已滿十八歲,亦不可將本區之內容派發、傳閱、出售、出租、交給或借予年齡未滿18歲的人士瀏覽,或將本網站內容向該人士出示、播
放或放映。</p>
</div>
</div>
<div class="bbs-screen bbs-content center clear">
<form action="/ask/over18" method="post">
<input type="hidden" name="from" value="/bbs/Gossiping/index.html">
<div class="over18-button-container">
<button class="btn-big" type="submit" name="yes" value="yes">我同意,我已年滿十八歲<br><small>進入</small></button>
</div>
<div class="over18-button-container">
<button class="btn-big" type="submit" name="no" value="no">未滿十八歲或不同意本條款<br><small>離開</small></button>
</div>
</form>
</div>
<script>
(function(i,s,o,g,r,a,m){i['GoogleAnalyticsObject']=r;i[r]=i[r]||function(){
(i[r].q=i[r].q||[]).push(arguments)},i[r].l=1*new Date();a=s.createElement(o),
m=s.getElementsByTagName(o)[0];a.async=1;a.src=g;m.parentNode.insertBefore(a,m)
})(window,document,'script','https://www.google-analytics.com/analytics.js','ga');
ga('create', 'UA-32365737-1', {
cookieDomain: 'ptt.cc',
legacyCookieDomain: 'ptt.cc'
});
ga('send', 'pageview');
</script>
<script src="//ajax.googleapis.com/ajax/libs/jquery/2.1.1/jquery.min.js"></script>
<script src="//images.ptt.cc/bbs/v2.27/bbs.js"></script>
<script defer src="https://static.cloudflareinsights.com/beacon.min.js/v652eace1692a40cfa3763df669d7439c1639079717194" integrity="sha512-Gi7xpJR8tSkrpF7aordPZQlW2DLtzUlZcumS8dMQjwDHEnw9I7ZLyiOj/6tZStRBGtGgN6ceN6cMH8z7etPGlw==" data-cf-beacon='{"rayId":"750a0d541db6e05a","version":"2022.8.1","r":1,"token":"515615eb5fab4c9b91a11e9bf529e6cf","si":100}' crossorigin="anonymous"></script>
</body>
</html>
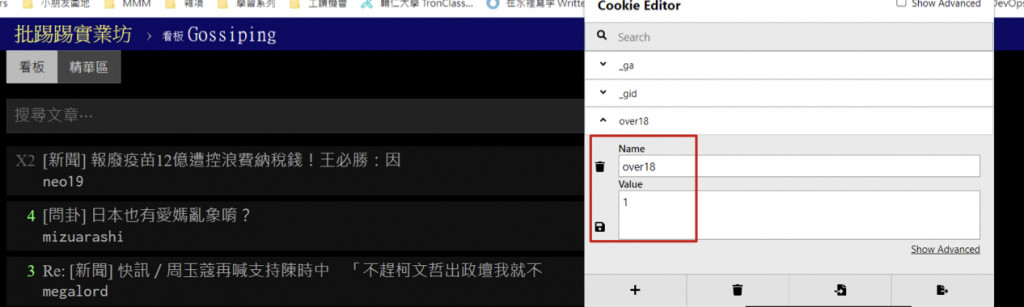
over 18是用來記錄是否點擊過已滿18歲,我們可以把這個cookies當作requests.get()的參數一同傳入。from http import cookies
import requests
url = 'https://www.ptt.cc/bbs/Gossiping/index.html'
cookies = {'over18':1}
r = requests.get(url, cookies= cookies)
print(r.text)
#output
<!DOCTYPE html>
<html>
<body>
<a href="/bbs/Gossiping/M.1632305989.A.5E0.html">[協尋] 橘貓咪嚕快點回家!(大安區)</a>
</div>
<div class="meta">
<div class="author">k020231310</div>
<div class="article-menu">
<div class="trigger">⋯</div>
<div class="dropdown">
<div class="item"><a href="/bbs/Gossiping/search?q=thread%3A%5B%E5%8D%94%E5%B0%8B%5D+%E6%A9%98%E8%B2%93%E5%92%AA%E5%9A%95%E5%BF%AB%E9%BB%9E%E5%9B%9E%E5%AE%B6%EF%BC%81%EF%BC%88%E5%A4%A7%E5%AE%89%E5%8D%80%EF%BC%89">搜尋同標題文章</a></div>
<div class="item"><a href="/bbs/Gossiping/search?q=author%3Ak020231310">搜尋看板內 k020231310 的文章
</a></div>
</div>
</div>
<div class="date"> 9/22</div>
<div class="mark"></div>
</body>
</html>
'''
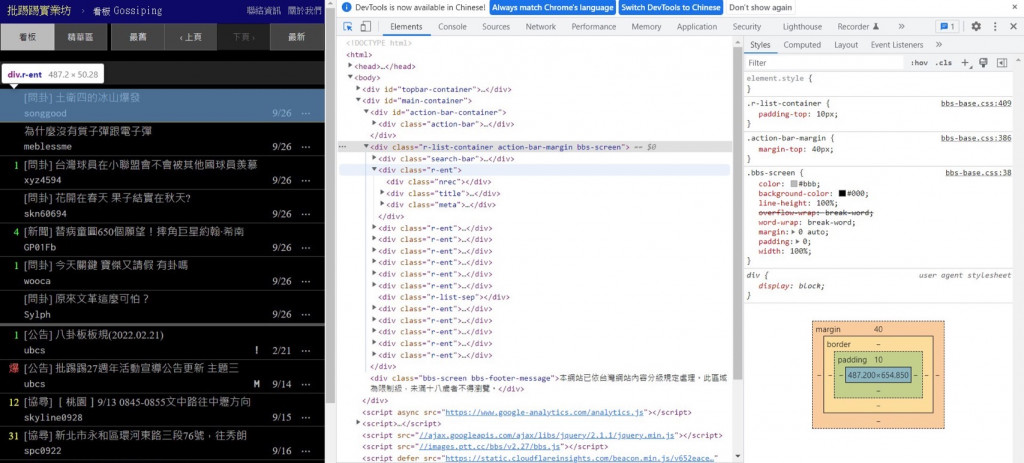
可以在這個div下看到包含該文章的資訊(紅框)。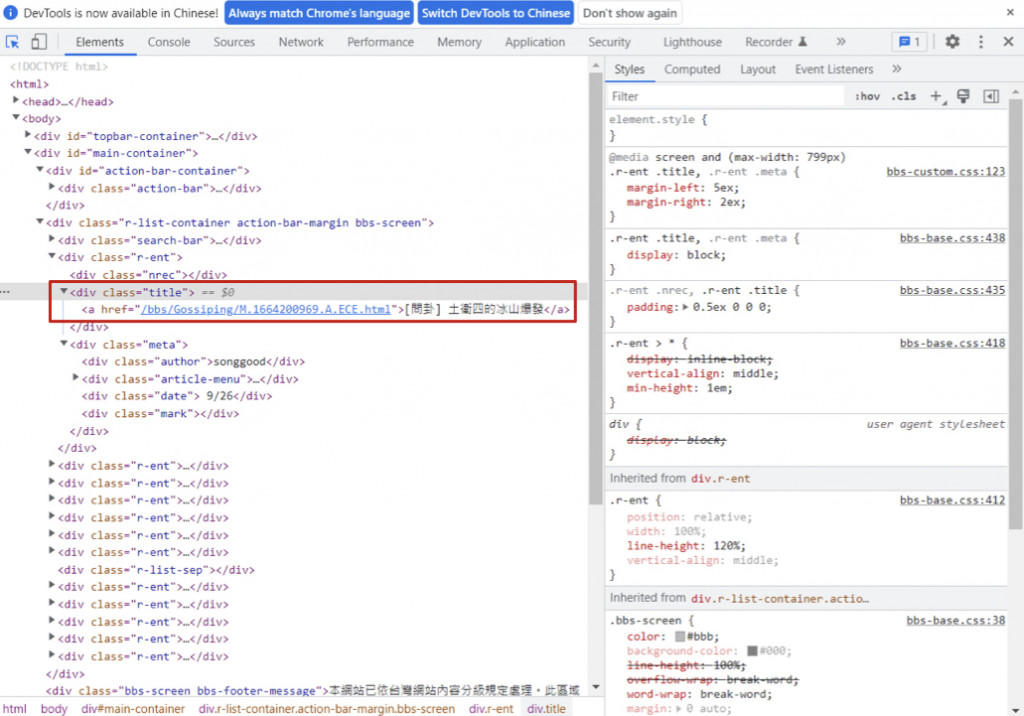
我們這邊可以先爬取:文章內容、文章連結和作者,這邊會用到第12天學習到的BeautifulSoup。
import requests
from bs4 import BeautifulSoup
url = 'https://www.ptt.cc/bbs/Gossiping/index.html'
cookies = {
'over18' : 1
}
r = requests.get(url, cookies = cookies)
soup = BeautifulSoup(resp.text, 'html5lib')
arts = soup.find_all('div', class_='r-ent')
for art in arts :
title = art.find('div', class_='title').getText().strip()
link = 'https://www.ptt.cc' + \
art.find('div', class_='title').a['href'].strip()
author = art.find('div', class_='author').getText().strip()
print(f'title: {title}\nlink: {link}\nauthor: {author}')
結語
今天正式的第一次使用Requests爬蟲,也使用了cookies的功能。
明天!
【Day 15】爬完這邊繼續!(實戰PTT 2/3)
參考資料
PTT八卦版https://www.ptt.cc/bbs/Gossiping/index.html

