前一日的文章,以硬體面討論了訓練的效率。但有了適當的硬體以後,要如何利用軟體去使用這些硬體呢?從今天開始的幾天內將介紹一些優化的方式。
先複習一下,上一篇文章內說的訓練流程:
今天將以橫向及縱向的兩種方向,來介紹增加Preprocess的方法,分別是:
正常情形的程式,其實都是使用單一個執行序(thread)在執行程式。但在某些情況下,有些任務是可以被平行處理(詳見平行計算)進而加快計算效率的。
例如,資料的預處理就是個很好的例子。以影像為例,每一張影像我們需要讀取、解碼、然後進行前處理,這是一個執行序能為我們做到的事情。那理論上而言,在同一時間單位下,有多少個的執行序,便能完成多少倍的資料預處理(但實際上會有個增幅極限,因為考慮到storage、cpu以及ram在單位時間內的存取極限),大致上概念上就會是下圖的模樣:
另一個可以考量的方式則是,GPU計算跟CPU前處理都需要時間對吧?那麼如果CPU前處理時,GPU閒置,GPU處理時,CPU閒置。這樣不是很浪費嗎?(慣老闆心態...)
Prefetch(或許可以譯作預取?),便是一個更加利用資源的方式。在GPU計算時,讓原本閒置的CPU先行進行下一個批次計算需要用到的預處理,透過同時壓榨CPU與GPU的計算能力來增加效能。概念大概就會長得像下面這張圖:
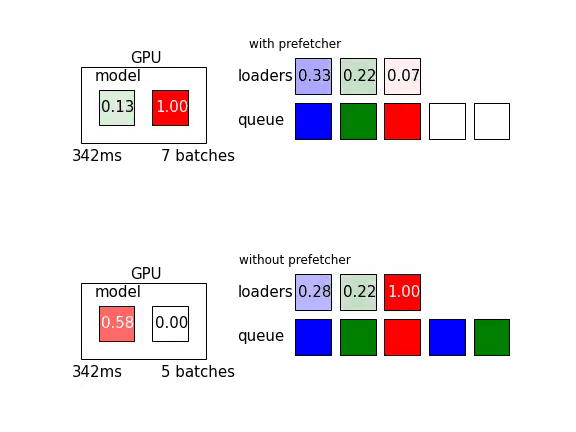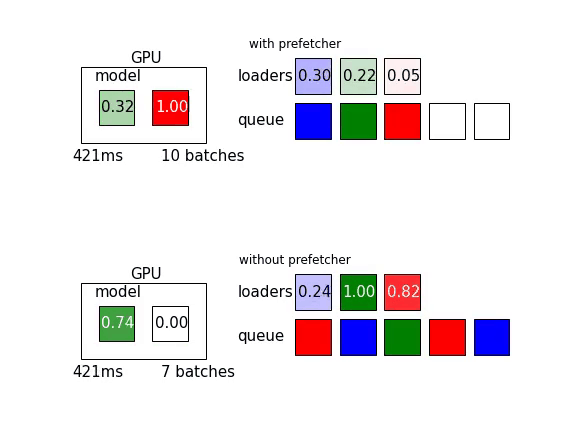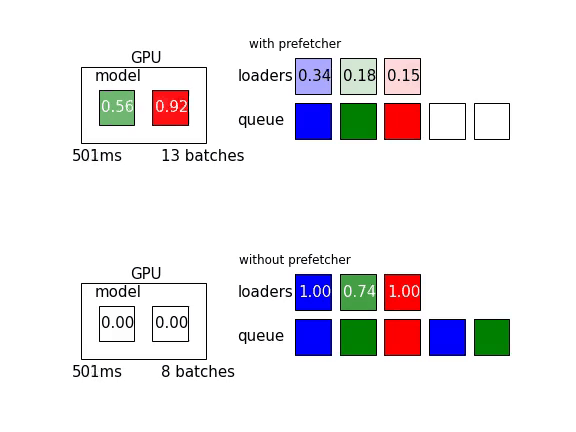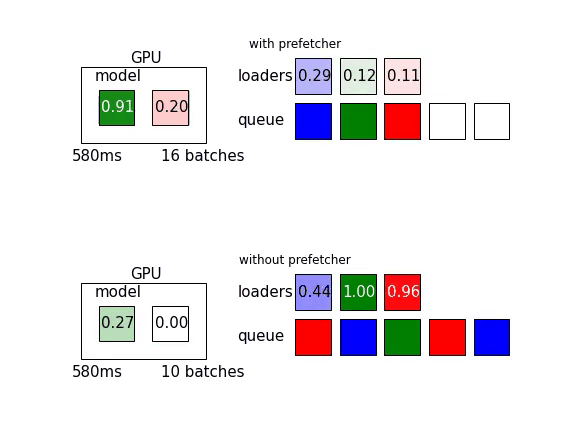
另外可以參考這篇文章,裡頭有以下這張動態圖,讓人更好理解Prefetch能增加多少效率:
說的嘴巴都泡,但具體怎麼做呢?所幸,歸功於強大的社群功能,Torch內的DataLoader已經同時實作了這兩樣東西。參考官方文件,可以透過其中下列的參數進行設置:
具體實例如下:
torch.utils.data.DataLoader(dataset,
num_workers = 8,
prefetch_factor = 4)
那麼實際差異到底有多少呢?讓我們實際各跑5個epoch比較看看。實驗結果如下表

進行了平行預處理以及prefetch的結果是原本的43%(245ms/579ms)唷!詳細設置可以參考無優化以及有優化的這兩個commit。

