昨天的 HTML 分析出的 Tokenizer,可以改良 [Day14] 的 Parser 轉換成以下的 AST
改良方式 : token.type === 'tagStart' / 'tagSelfClose' ,建立 node 時多取得 token.attrStr 資訊即可
// 原先沒有 attrStr 的 node
const old_node = {type: token.name , children: []};
// 新的有 attrStr 的 node
const new_node = {type: token.name, attrStr: token.attrStr, children: []};
const ast = {
"type": "root",
"children": [
{
"type": "div",
"attrStr": "id=\"app\"",
"children": [
{
"type": "p",
"attrStr": "class=\"text-red\"",
"children": [
{
"type": "text"
}
]
},
{
"type": "input",
"attrStr": "type=\"text\" id=\"username\" placeholder=\"請輸入姓名\" disabled"
},
{
"type": "img",
"attrStr": "src=\"https://ithelp.ithome.com.tw/storage/image/fight.svg\"\r\n alt='\"圖片\"'"
},
{
"type": "p",
"attrStr": "style=\"margin-top: 3px\"",
"children": [
{
"type": "text"
}
]
}
]
}
]
}
attrStr 的區塊,看起來就像是沒分析完的樣子,我們下面來分析一下 attrStr 的內容,並轉換成我們想要的格式。
比如說 attrStr 的內容 = type="text" id="username" placeholder="請輸入姓名" disabled
我們期望轉換成 :
const attrs = [
{name: 'type', value: 'text'},
{name: 'id', value: 'username'},
{name: 'placeholder', value: '請輸入姓名'},
{name: 'disabled', value: true}
]
複習一下,Tokenizer 要如何分析 ?
下面我們就來重複上述的 6 個步驟,來分析 attrStr 的 tokenizer。
英文字母 ,切換狀態為 IN_ATTR_NAME= 會將 collected 變數中的內容當作 attrName,切換狀態成 IN_ATTR_VALUE or 最後一個字 會將 collected 變數中的內容當作 attrName,切換狀態成 INITIAL ( 例: disabled )' ,切換狀態為 IN_SINGLE_QUOTATION" ,切換狀態為 IN_DOUBLE_QUOTATION or 最後一個字 會將 collected 變數中的內容當作 attrValue,切換狀態成 INITIAL ( 例: type=text )' ,切換狀態為 INITIAL,並將 collected 變數中的內容當作 attrValue" ,切換狀態為 INITIAL,並將 collected 變數中的內容當作 attrValue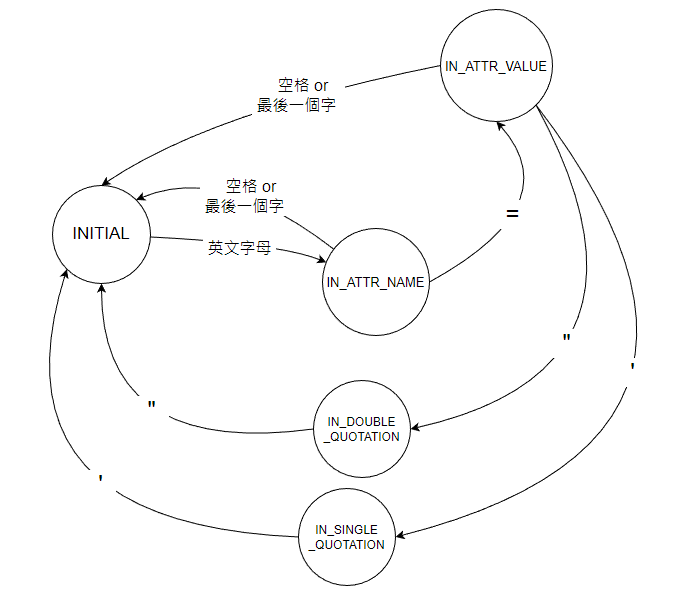
完整程式碼 attrStr-tokenizer.js 請到 github 上查看
我們有了 attrStr-tokenizer.js 之後,我們還需要走訪 ( traverse ) 每個 AST 的節點,並將每個節點的 attrStr 轉換成 attrs。
有個專業術語叫做 transform,那個意思就是當我們走訪 ( traverse ) 每個 AST 的節點,對每個節點做一些加工。
複習一下,我們分析的步驟
也就是下圖所示的那樣:

我們到目前為止,說明了 only TAG 的 HTML 字串要如何分析成 AST ,之後展現了追加 html attr 要如何在舊有的 tokenizer 跟 parser 做調整。
不過我們分析的案例都不是完整 HTML 的情況,因此如果要做成完整的 HTML Parser ,可以有兩個方向
明天我們來細部說明一下,HTML SPEC 網站 要如何觀看 & 實作上面規範的流程。

 iThome鐵人賽
iThome鐵人賽