今天的文章主要要提到關於優化器實作的部分,昨天的文章中有提到了優化器的原理以及種類,但我並沒有提到該如何選擇一個合適的優化器這個很重要的問題.因此今天主要就是要來探討要如何去選擇一個合適的優化器,當然這個問題涉及到很大量的計算問題,因此我們必須借助電腦的力量來幫助我們,那麼接下來就開始我們今天的主題.
import torch
import torch.utils.data as Data
import torch.nn.functional as F
import matplotlib.pyplot as plt
torch.manual_seed(1)
LR = 0.01
BATCH_SIZE = 30
EPOCH = 15
x = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1)
y = x.pow(4) + 0.1*torch.normal(torch.zeros(*x.size()))
plt.scatter(x.numpy(), y.numpy())
plt.show()
torch_dataset = Data.TensorDataset(x, y)
loader = Data.DataLoader(dataset=torch_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=2)
建立一個具有100個點並以一元四次方程式為軌跡的偽數據.
2. 優化器各自負責各自的神經網路
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(1, 20)
self.predict = torch.nn.Linear(20, 1)
def forward(self, x):
x = F.relu(self.hidden(x))
x = self.predict(x)
return x
if __name__ == '__main__'
net_SGD = Net()
net_Momentum = Net()
net_RMSprop = Net()
net_Adam = Net()
nets = [net_SGD, net_Momentum, net_RMSprop, net_Adam]
opt_SGD = torch.optim.SGD(net_SGD.parameters(), lr=LR)
opt_Momentum = torch.optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.8)
opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(), lr=LR, alpha=0.9)
opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99))
optimizers = [opt_SGD, opt_Momentum, opt_RMSprop, opt_Adam]
loss_func = torch.nn.MSELoss()
losses_his = [[], [], [], []]
for epoch in range(EPOCH):
print('Epoch: ', epoch)
for step, (b_x, b_y) in enumerate(loader):
for net, opt, l_his in zip(nets, optimizers, losses_his):
output = net(b_x)
loss = loss_func(output, b_y)
opt.zero_grad()
loss.backward()
opt.step()
l_his.append(loss.data.numpy())
5. 以loss及steps進行畫圖
訓練的次數越多會導致steps的數字跟著變大.
在偽數據越多時,訓練次數並不用太多便可以從作圖中得知該選擇哪一種優化器來優化神經網路.但當偽數據不夠多時,我們就必須要透過增加訓練的次數來選擇合適的優化器.
上圖為100個數據時進行12次訓練後的作圖結果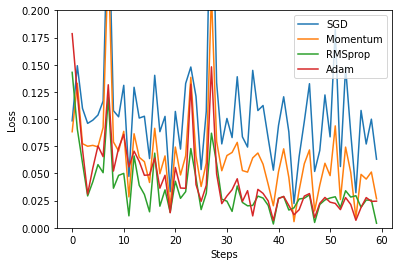
上圖為100個數據時進行15次訓練後的作圖結果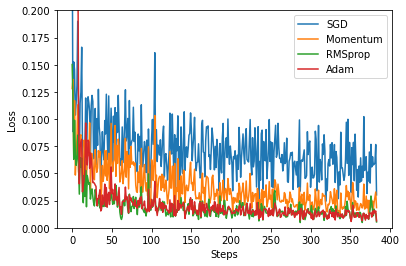
上圖為1000個數據時進行12次訓練後的作圖的結果


 iThome鐵人賽
iThome鐵人賽