閒聊
昨天建構好了Selenium的環境跟了解一些基本操作後,今天要來繼續學習更多用法。
Xpath語法
在昨天有介紹過一部分可以搜尋HTML文件的方法,今天介紹另一種Xpath方法。
Xpath全名是XML Path,主要用來查詢HTML、XML文件的所有元素,整個文件是一個數狀結構,使用相對路徑方式搜尋網頁的節點。
find_element_by_xpath()
class = ''裡面包裹的就是屬性。n = driver.find_element_by_xpath("路徑[@calss = '屬性']")
<img>元素內的scr屬性設定,這時候還會需要用到get_attribute()方法。n1 = driver.find_element_by_xapth("路徑/img")
print(n1.get_attribute('scr'))
contains(text(), '字串')
處理網頁特殊按鍵
Python有提供多個模組,可以在需要捲動網頁或是一些特殊鍵時使用。
#用keys呼叫相關屬性
form selenium.webdriver.commom,keys import Keys
selenium.webdriver.commom.keys
#相當於鍵盤的按鍵
ENTER/ RETURN
PAGE_DOWN/ PAGE_UP/ HOME/ END
UP / DOWN/ LEFT/ RIGHT
自動化下載資料
今天以環保署空氣品質資料為例,首先進入到環保署空氣品質網站
在這裡按下檢查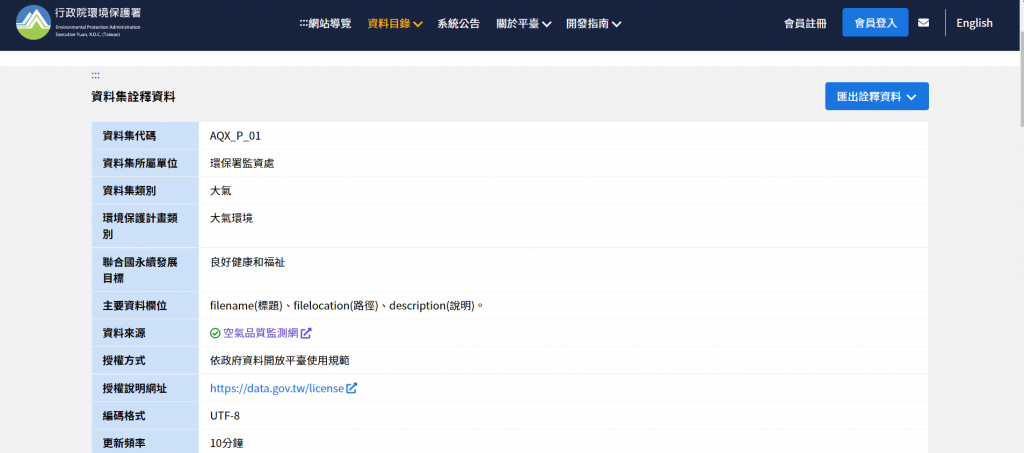
JSON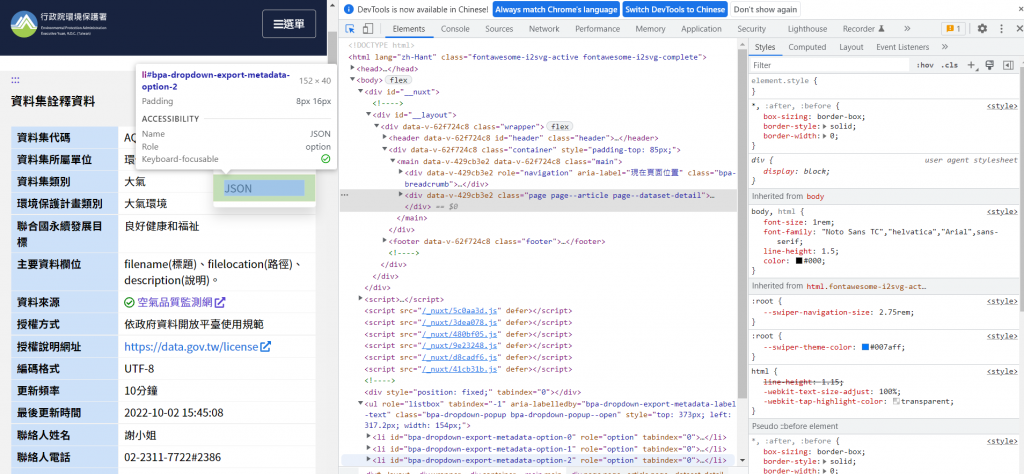
XML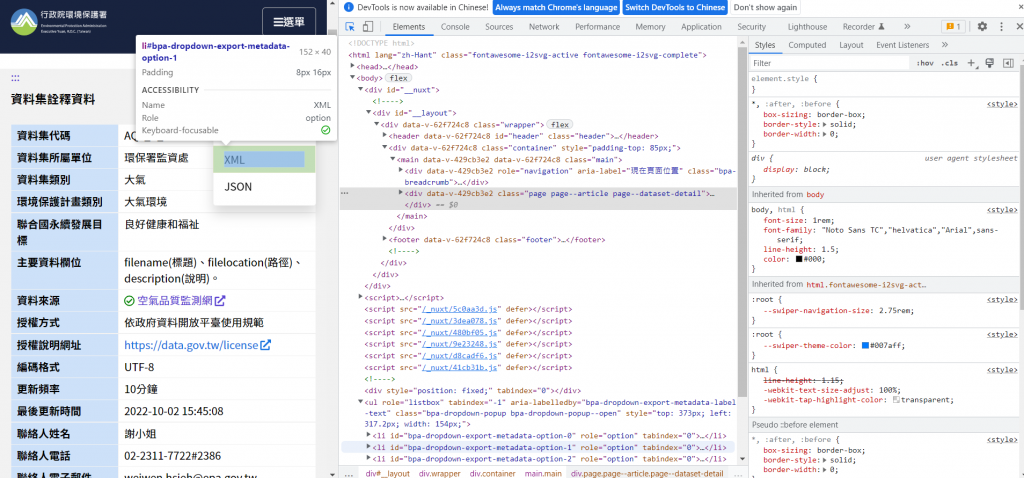
CSV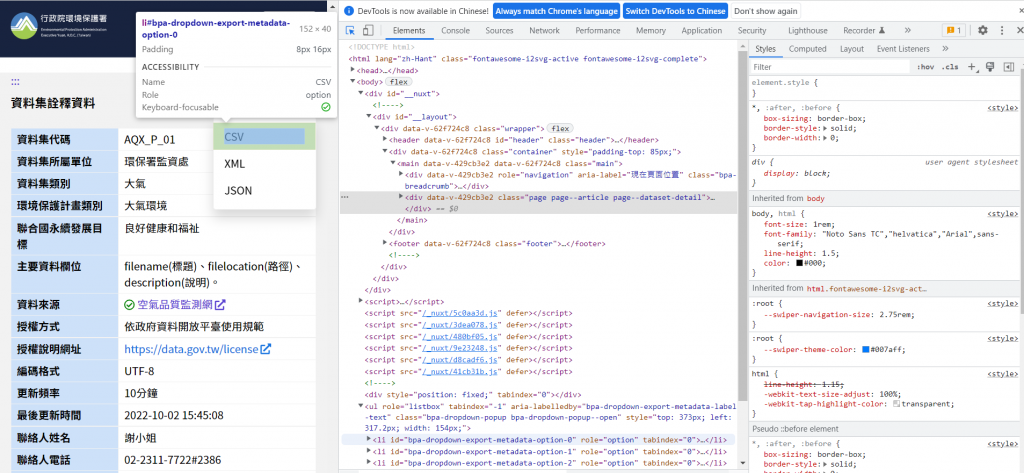
看到各自的路徑後,就可以來進行自動化下載資料的動作了。
from selenium import webdriver
url = 'https://data.epa.gov.tw/dataset/detail/AQX_P_01'
driverPath = 'D:\geckodriver\chromedriver.exe'
driver = webdriver.Chrome(executable_path = driverPath) #網頁下載至瀏覽器
driver.get(url) #發送請求
driver.find_element_by_link_text('JSON').click() #按JSON下載
driver.find_element_by_link_text('XML').click() #按XML下載
driver.find_element_by_link_text('CSV').click() #按CSV下載
結語
今天學習了更多Selenium相關的技術,明天就會帶上實作了!
明天!
【Day 20】帶上工具去Dcard去爬文(實戰Selenium 1/2)
參考資料
Teresa,能跟妳聯繫一下嘛?有些事情想請教。 https://wa.me/85251164453 謝謝!

