continue
昨天有寫到,觀察網站後可以發現所有的商品資訊都在個別的div.caption底下,所以我們可以用select把他們選出來後再一個一個處理。
首先試著把商品名給拉出來
觀察div.caption裡面後可以發現他在第一個a標籤裡面,不過往下看可以發現底下的加入追蹤也是a標籤。
所以我們只需要抓第一個a標籤的內容,因此用find。寫出來會像下面這樣:
soup = BeautifulSoup(html.text, 'html.parser')
for i in soup.select('div.caption'):
print(i.find('a').text))
就可以看到他順利的印出來了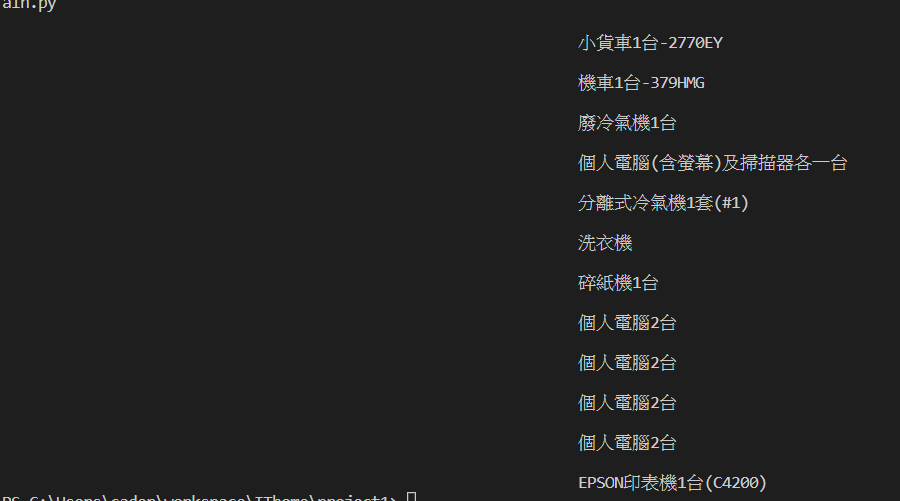
不過格式炸掉了,所以要把空格濾掉。
我的習慣是用正則表達法,也就是re把他濾掉。寫起來會長這樣。
print(re.sub(r"^\s+", "", i.find('a').text))
這樣輸出就會如下圖正常了。
不過正則表達法講起來會脫離主題太多所以就不講了,有興趣的可以自己查下。
接著來試著把地區抓出來
觀察後可以發現他的文字就在div.caption底下,但要是你拿i.text直接提取文字的話會發現他把子元素的元素也一併輸出了。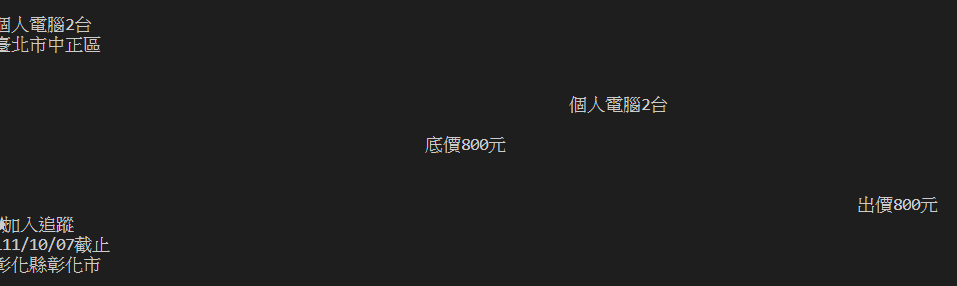
像這樣。
所以我們要讓他只搜尋自己的元素,我們可以這樣寫。
i.find(text = True)
其中text = True就是搜尋文字,這裡地區資訊是在最前面所以不用多寫其他條件讓他搜尋第一個就行了。
一樣把print(re.sub(r"^\s+", "", i.find(text = True)))加到for迴圈底下,可以看見他成功輸出了。

 iThome鐵人賽
iThome鐵人賽