This is the handout directory for the CS:APP Cache Lab.
csim.c Your cache simulatortrans.c Your transpose function
Makefile Builds the simulator and toolsREADME.md This filedriver.py* The driver program, runs test-csim and test-transcachelab.c Required helper functionscachelab.h Required header filecsim-ref* The executable reference cache simulatortest-csim* Tests your cache simulatortest-trans.c Tests your transpose functiontracegen.c Helper program used by test-transtraces/ Trace files used by test-csim.c
我們需要讀取trace文件中的命令來評估緩存的性能,而這些trace文件是由Valgrind這告軟體生成的,因此建議先進行安裝
輸入
sudo apt install valgrind
完成安裝後可以透過指令valgrind --log-fd=1 --tool=lackey -v --trace-mem=yes ls -l,追蹤目錄下所有可執行文件的緩存使用狀況
輸入完指令後可以在終端中看到以下圖的格式輸出,它代表程式執行過程中緩存的運作紀錄
格式: [操作指令], [64 bits地址], [數據大小]

該實驗值主要編寫一個LRU策略的虛擬緩存,透過讀取trace文件指令模擬緩存的操作,並對hits, miss, eviction數量進行分析
csim.c中實現虛擬緩存sets, line, block緩存使用的記憶體空間要使用malloc動態分配.trace文件cachelab.c/.h中的helper function,例如printfSummary()
Lab文件說得很清楚:


測試自行編寫的緩存,執行結果必須要跟
csim-ref相同
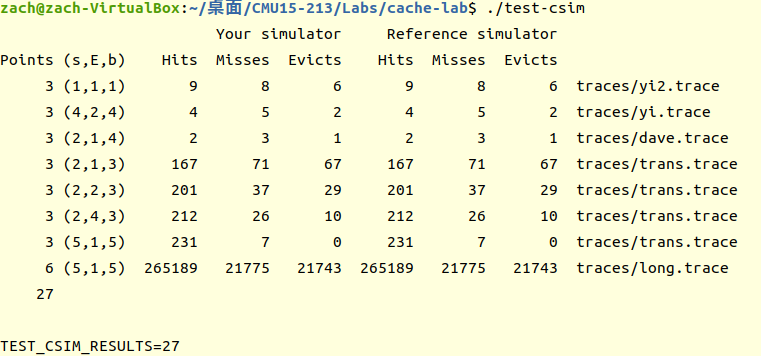
或是直接執行./test-csim查看輸出結果與reference simulator是否相同,若是輸出結果為27分那就代表通過測試用例
我們把整個程式粗略分成5個區塊:
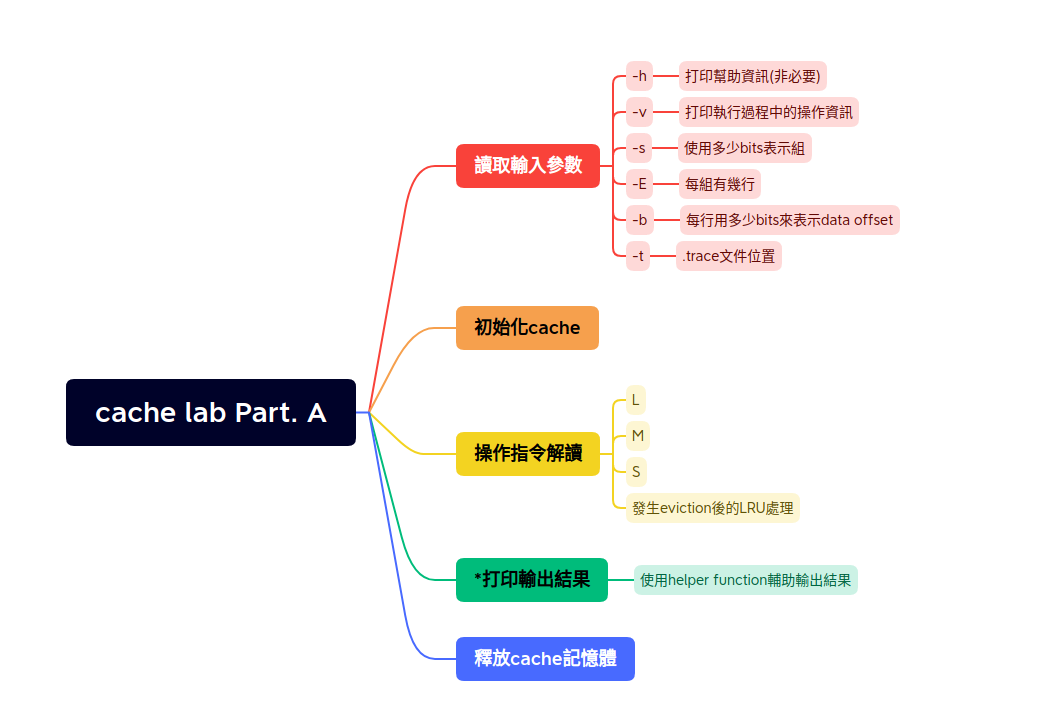
該模塊的目的是為了讀取可執行檔的後續參數,例如./csim -s 4 -E 1 -b 4 -t traces/yi.trace中的組數、行、偏移量、trace文件,先把這些數據暫存起來,待初始化緩存與讀取trace文件時使用,其程式碼區塊如下
/**
* func for getting operator
*/
static char get_operation(char* str){
if(strlen(str) <= 1){
return '\0';
}
return str[1];
}
int main(int argc, char* argv[]){
// ... 省略
for(int i=1; i<argc; i++){
char op = get_operation(argv[i]);
switch(op){
case 'h':
print_help_message();
break;
case 'v':
print_msg = true;
break;
case 's':
s = atoi(argv[++i]);
input_check++;
break;
case 'E':
E = atoi(argv[++i]);
input_check++;
break;
case 'b':
b = atoi(argv[++i]);
input_check++;
break;
case 't':
strcpy(filename, argv[++i]);
input_check++;
break;
default:
break;
}
}
// ... 省略
}
利用得到的參數,為cache分配動態記憶體,其function為cache_init(s, E),緩存中的行定義為結構體cacheLine
typedef struct{
uint32_t vaild;
uint32_t tag;
uint64_t timeStamp; // 供LRU使用的時間戳
}cacheLine;
/**
* func for initializing cache memory
*/
static void cache_init(uint8_t s, uint8_t E){
uint32_t sets = 1 << s;
virtual_cache = (cacheLine**)malloc(sizeof(cacheLine*) * sets);
for(int i=0; i<sets; i++){
virtual_cache[i] = (cacheLine*)malloc(sizeof(cacheLine) * E);
}
}
該部份用來解讀trace文件中的操作指令、地址、大小信息
函式cmd_parsing(filename)會逐條取trace文件的行直到EOF
函式load_operation(line)會解析該條指令並操作緩存
/**
* func for loading data from cache
*/
static void load_operation(char* line){
uint64_t addr=0;
uint32_t dataBytes=0;
char op;
/* 取trace文件的一行命令 */
sscanf(line, " %c %lx,%u", &op, &addr, &dataBytes);
/* 操作指令只能有L, M, S */
if(op != 'L' && op != 'M' && op != 'S'){
return;
}
if(print_msg){
printf("%c %lx,%u ", op, addr, dataBytes);
}
/* 對地址進行解析 */
uint32_t set = (addr >> b) & (~(U64MAX << s));
uint32_t tag = addr >> (s+b);
bool find = false;
int empty_line = -1;
/* 遍歷cache查看是否存在該數據 */
for(int i=E-1; i>=0; i--){
/* 緩存命中,同時更新時間 */
if(virtual_cache[set][i].vaild && virtual_cache[set][i].tag == tag){
find = true;
virtual_cache[set][i].timeStamp = ticks;
break;
}else if(virtual_cache[set][i].vaild == 0){
/* 找到空的行 */
empty_line = i;
}
}
/* 若為修改指令,因為會寫回所以hit數一定要加一 */
hits = op == 'M' ? hits+1 : hits;
if(find){
hits++;
if(print_msg){
printf("hit ");
}
}else{
miss++;
if(print_msg){
printf("miss ");
}
/* 若不命中且沒有空行,就會發生eviction */
if(empty_line == -1){
evictions++;
/* 使用LRU找需要替換的行 */
empty_line = LRU(set);
if(print_msg){
printf("eviction ");
}
}
/* 不命中後重新加載,更新緩存 */
virtual_cache[set][empty_line].vaild = 1;
virtual_cache[set][empty_line].tag = tag;
virtual_cache[set][empty_line].timeStamp = ticks;
}
if(op == 'M' && print_msg){
printf("hit ");
}
if(print_msg){
printf("\n");
}
}
/**
* func for parsing commands from trace file
*/
static void cmd_parsing(char* filename){
char line[MAX_LEN];
FILE* fp = fopen(filename, "r");
while(!feof(fp) && !ferror(fp)){
strcpy(line, "\n");
fgets(line, MAX_LEN, fp);
load_operation(line);
ticks++;
}
fclose(fp);
}
使用cacheLine的變數timeStamp判斷哪個行距離現在使用最久遠,因為每次操作時都會更新時間週期ticks(+1),這代表timeStamp越小,距離現在越久
所以我們只需要掃描一遍某組中的所有行就可找出要替換的行
/**
* func for applying LRU algo.
*/
static uint8_t LRU(uint8_t set){
int repalce = 0;
for(int i=1; i<E; i++){
repalce = virtual_cache[set][i].timeStamp < virtual_cache[set][repalce].timeStamp ? i : repalce;
}
return repalce;
}
可以調用cachelab.c/.h提供的printSummary(hits, miss, evictions)函式,簡單打印緩存執行後的結果
所有trace文件的操作指令執行完後,釋放當初為緩存動態分配的記憶體
/**
* func for releasing cache memory
*/
static void free_cache(){
uint32_t sets = 1 << s;
for(int i=0; i<sets; i++){
free(virtual_cache[i]);
virtual_cache[i] = NULL;
}
free(virtual_cache);
virtual_cache = NULL;
}
實驗B要求實現一個矩陣的轉移函式,並盡可能的降低緩存不命中的次數
實驗總共要編寫三種不同大小的轉移函式
Lab文件有提到miss的範圍與得分佔比,例如64 * 64的矩陣測試結果miss要小於1300才能得到滿分

trans.c中編寫並測試轉移函式int類型的局部變數,若轉移函式中調用其他函式,也要將該函式中的局部變數考慮進去long類型局部變數transpose_submit(int M, int N, int A[N][M], int B[M][N])中陣列參數只允許修改Bmalloc
./test-trans -M 32 -N 32 for 32 * 32轉移矩陣./test-trans -M 64 -N 64 for 64 * 64轉移矩陣./test-trans -M 61 -N 67 for 61 * 67轉移矩陣註冊多個不同的函式,可以在進行驗證時同時執行,最多可以註冊100個不同的轉移函式
只需要在registerFunctions()中調用registerTransFunction()並填入該函式的註解字串以及函式名就可以了
註冊函式細節請見
cachelab.c/.h
/*
* trans - A simple baseline transpose function, not optimized for the cache.
*/
char trans_desc[] = "Simple row-wise scan transpose";
void trans(int M, int N, int A[N][M], int B[M][N]){
int i, j, tmp;
for (i = 0; i < N; i++) {
for (j = 0; j < M; j++) {
tmp = A[i][j];
B[j][i] = tmp;
}
}
}
void registerFunctions(){
registerTransFunction(transpose_submit, transpose_submit_desc);
registerTransFunction(trans, trans_desc);
registerTransFunction(trans32, trans_desc32);
registerTransFunction(trans64, trans_desc64);
registerTransFunction(trans6167, trans_desc6167);
}
Blocking是一種記憶體區塊化處理的技術,透過提高循環內的局部性降低不命中率
為了演示Blocking為何有效,我們編寫一個簡單的小函式,計算矩陣A的每列與矩陣B的每行相乘的加總
int multi(int A[8][8], int B[8][8]){
int i, j, temp=0, sum=0;
for (i = 0; i < 8; i++) {
for (j = 0; j < 8; j++) {
temp = A[i][j] * B[j][i];
sum += temp;
}
}
return sum;
}
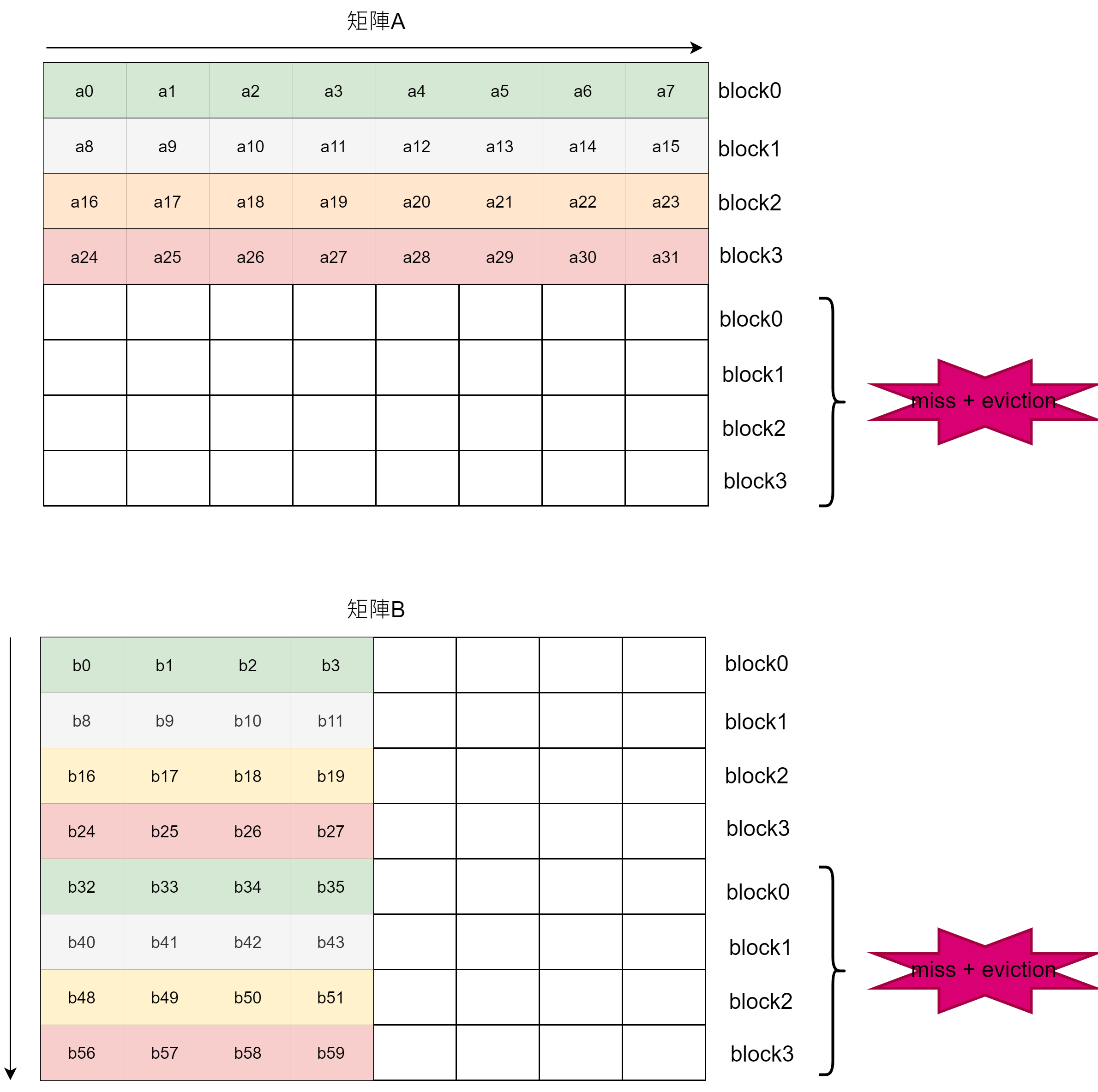
由於緩存的一行剛好可以容納矩陣A的一列,所以總共會發生8次miss,由於緩存只有4組,所以當遍歷到第4列時就會覆蓋掉第0列中緩存內容(發生eviction),但由於是逐列掃描,所以差別不大
B矩陣是逐行(column)讀取的,所以每次都會發生miss
總miss數為8 + 64 = 72次miss
int multi(int A[8][8], int B[8][8]){
int i, j, temp=0, sum=0;
/* 處理4個塊 */
for (i = 0; i < 8; i+=4) {
for (j = 0; j < 8; j+=4) {
/* 處理每一個小塊 */
for(int i1=i; i1<i+4; i1++){
for(int j1=j; j1<j+4; j1++){
temp = A[i1][j1] * B[j1][i1];
sum += temp;
}
}
}
}
return sum;
}
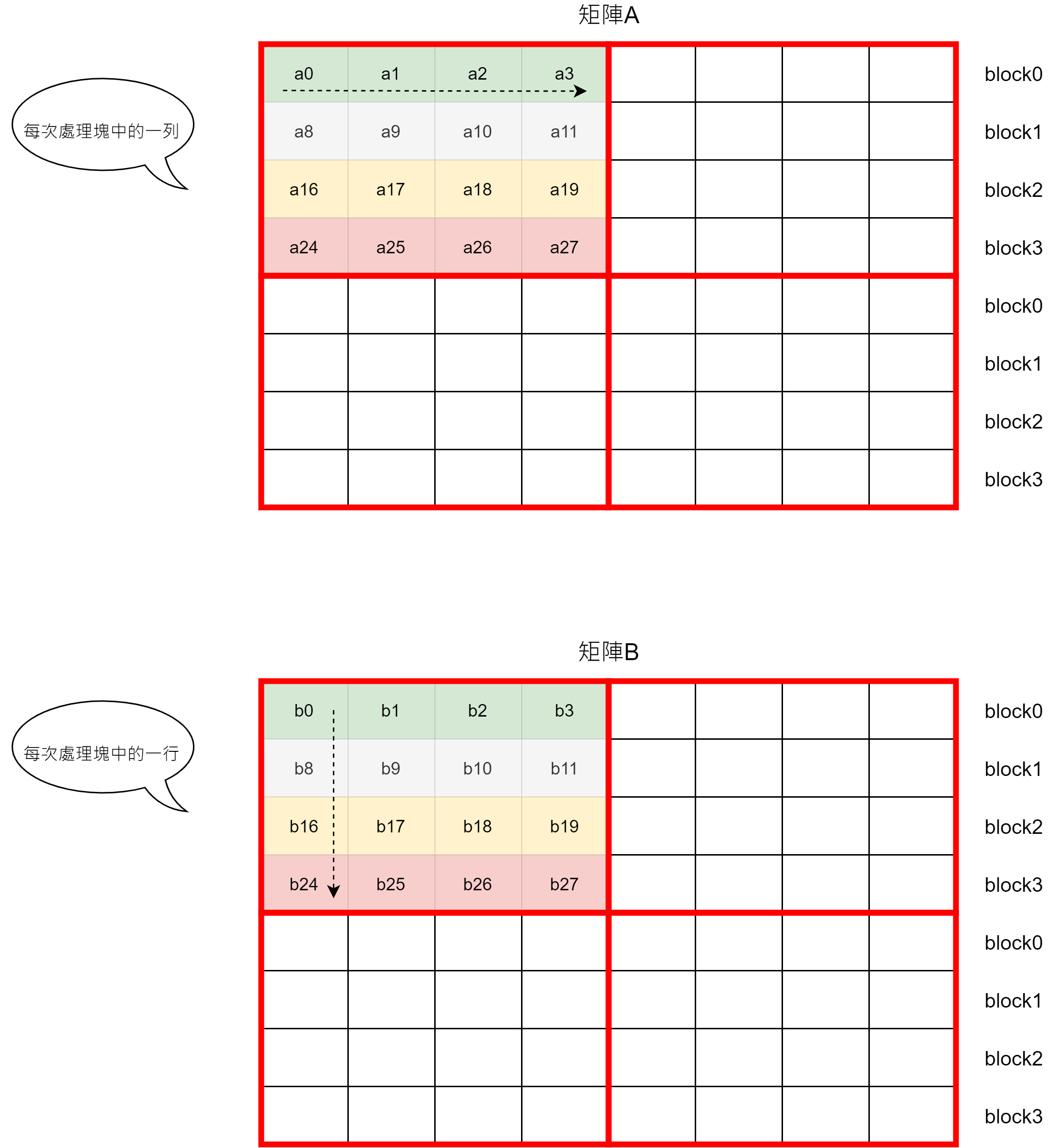
由於緩存的一行剛好可以容納矩陣A的一列,所以前4列的數據會全部加載進緩存中;同理左下的塊加載時,右下的塊需要的數據也已經在緩存中了。Blocking方法對矩陣A來說沒變,依然是8次miss
對於B矩陣來說,每個塊產生的miss:
總miss數為8 + 16 = 24次miss
從上述的小實驗中可以看出,Blocking方法盡量避免緩存沒有被充分利用(不管是緩存為空,或是加載後只讀取一點數據),讓數據的讀取有更好的空間局部性
使用Blocking方法需要特別注意緩存的大小以及讀取數據的規模,因為這會涉及到緩存如何看待數據的加載目標
開始前先看看實驗前提:
int類型整數由於一列有32個整數,所以8列可以剛好填滿緩存
使用大小為8 * 8的塊(8代表8個整數大小)
/*
* trans32*32
*/
char trans_desc32[] = "Simple transpose func32";
void trans32(int M, int N, int A[N][M], int B[M][N]){
int i, j, i1;
/* 循環遍歷每個塊 */
for (i = 0; i < M; i += 8) {
for (j = 0; j < N; j += 8) {
/* 對每個小塊進行數據轉移處理 */
for(i1=i; i1<i+8; i1++) {
int temp_0 = A[i1][j];
int temp_1 = A[i1][j+1];
int temp_2 = A[i1][j+2];
int temp_3 = A[i1][j+3];
int temp_4 = A[i1][j+4];
int temp_5 = A[i1][j+5];
int temp_6 = A[i1][j+6];
int temp_7 = A[i1][j+7];
B[j][i1] = temp_0;
B[j+1][i1] = temp_1;
B[j+2][i1] = temp_2;
B[j+3][i1] = temp_3;
B[j+4][i1] = temp_4;
B[j+5][i1] = temp_5;
B[j+6][i1] = temp_6;
B[j+7][i1] = temp_7;
}
}
}
}
eviction,需要特殊處理例如下圖我們假設一個塊大小為8 * 8,每個塊可以細分成4個子塊,每個子塊大小為4 * 4
舉例來說,若我們同時處理A1以及A3,就會發生
eviction,因為每過4列就會重頭將緩存更新一遍,因此為了避免這種場景發生,我們都需要確保在緩存發生eviction替換前,被替換數據已盡量完成操作
塊內的操作可以分成以下步驟:
miss以及eviction來源
miss以及eviction(每列皆發生一次)miss以及eviction(因為緩存現在存放的數據變成B3, B4)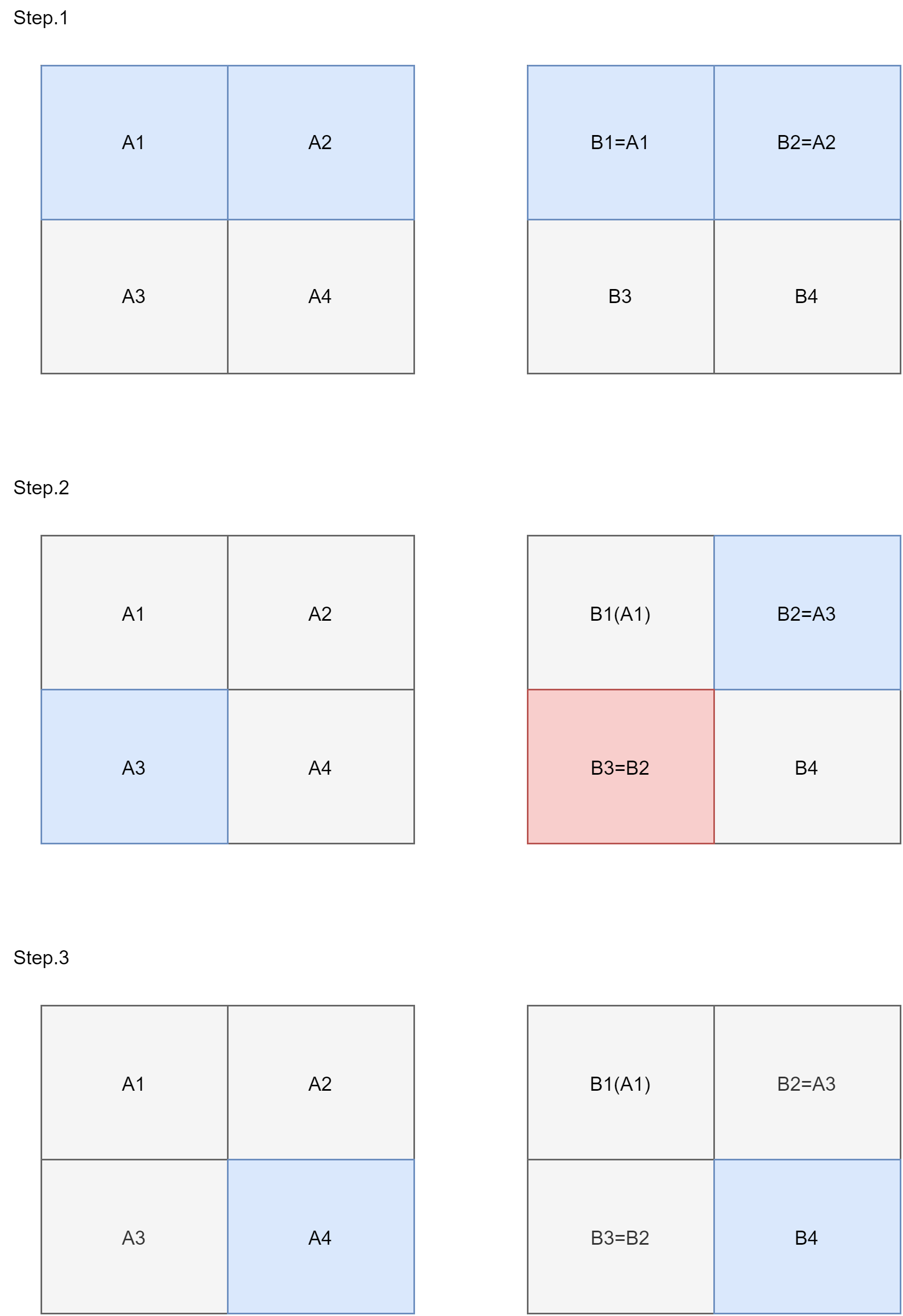
/*
* trans64*64
*/
char trans_desc64[] = "Simple transpose func64";
void trans64(int M, int N, int A[N][M], int B[M][N]){
int i, j, k;
int temp_0, temp_1, temp_2, temp_3, temp_4, temp_5, temp_6, temp_7;
/* 循環遍歷每個塊 */
for (i = 0; i < N; i += 8) {
for (j = 0; j < M; j += 8) {
/* A1, A2 --> B1, B2 */
for (k = 0; k < 4; k++) {
temp_0 = A[i + k][j];
temp_1 = A[i + k][j + 1];
temp_2 = A[i + k][j + 2];
temp_3 = A[i + k][j + 3];
temp_4 = A[i + k][j + 4];
temp_5 = A[i + k][j + 5];
temp_6 = A[i + k][j + 6];
temp_7 = A[i + k][j + 7];
B[j][i + k] = temp_0;
B[j + 1][i + k] = temp_1;
B[j + 2][i + k] = temp_2;
B[j + 3][i + k] = temp_3;
B[j][i + k + 4] = temp_4;
B[j + 1][i + k + 4] = temp_5;
B[j + 2][i + k + 4] = temp_6;
B[j + 3][i + k + 4] = temp_7;
}
/* B2 --> B3, A3 --> B2 */
for (k = 0; k < 4; k++) {
temp_0 = A[i + 4][j + k];
temp_1 = A[i + 5][j + k];
temp_2 = A[i + 6][j + k];
temp_3 = A[i + 7][j + k];
temp_4 = B[j + k][i + 4];
temp_5 = B[j + k][i + 5];
temp_6 = B[j + k][i + 6];
temp_7 = B[j + k][i + 7];
B[j + k][i + 4] = temp_0;
B[j + k][i + 5] = temp_1;
B[j + k][i + 6] = temp_2;
B[j + k][i + 7] = temp_3;
B[j + k + 4][i] = temp_4;
B[j + k + 4][i + 1] = temp_5;
B[j + k + 4][i + 2] = temp_6;
B[j + k + 4][i + 3] = temp_7;
}
/* A4 --> B4 */
for (k = 4; k < 8; k++) {
temp_0 = A[i + k][j + 4];
temp_1 = A[i + k][j + 5];
temp_2 = A[i + k][j + 6];
temp_3 = A[i + k][j + 7];
B[j + 4][i + k] = temp_0;
B[j + 5][i + k] = temp_1;
B[j + 6][i + k] = temp_2;
B[j + 7][i + k] = temp_3;
}
}
}
}

/*
* trans61*67
*/
char trans_desc6167[] = "Simple transpose func6167";
void trans6167(int M, int N, int A[N][M], int B[M][N]){
int i, j;
int tmp1, tmp2, tmp3, tmp4, tmp5, tmp6, tmp7, tmp8;
/* 61 * 64 */
for (i = 0; i < (M/8)*8; i += 8) {
for (j = 0; j < N; i++) {
tmp1 = A[j][i];
tmp2 = A[j][i + 1];
tmp3 = A[j][i + 2];
tmp4 = A[j][i + 3];
tmp5 = A[j][i + 4];
tmp6 = A[j][i + 5];
tmp7 = A[j][i + 6];
tmp8 = A[j][i + 7];
B[i][j] = tmp1;
B[i + 1][j] = tmp2;
B[i + 2][j] = tmp3;
B[i + 3][j] = tmp4;
B[i + 4][j] = tmp5;
B[i + 5][j] = tmp6;
B[i + 6][j] = tmp7;
B[i + 7][j] = tmp8;
}
}
/* 轉移剩餘的區塊 */
for (i = 0; i < N; i++) {
for (j = (M/8)*8; j < M; j++) {
tmp1 = A[i][j];
B[j][i] = tmp1;
}
}
}
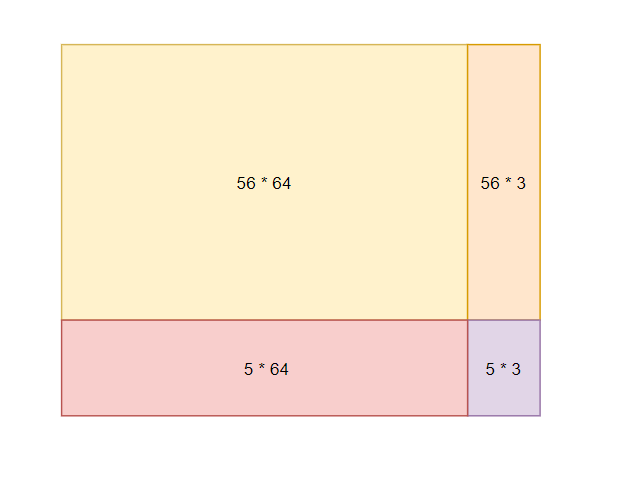
/*
* trans61*67
*/
char trans_desc6167[] = "Simple transpose func6167";
void trans6167(int M, int N, int A[N][M], int B[M][N]){
int i, j, k;
int temp_0, temp_1, temp_2, temp_3, temp_4, temp_5, temp_6, temp_7;
/* 64 * 56 */
for (i = 0; i < 64; i += 8) {
for (j = 0; j < 56; j += 8) {
/* A1, A2 --> B1, B2 */
for (k = 0; k < 4; k++) {
temp_0 = A[i + k][j];
temp_1 = A[i + k][j + 1];
temp_2 = A[i + k][j + 2];
temp_3 = A[i + k][j + 3];
temp_4 = A[i + k][j + 4];
temp_5 = A[i + k][j + 5];
temp_6 = A[i + k][j + 6];
temp_7 = A[i + k][j + 7];
B[j][i + k] = temp_0;
B[j + 1][i + k] = temp_1;
B[j + 2][i + k] = temp_2;
B[j + 3][i + k] = temp_3;
B[j][i + k + 4] = temp_4;
B[j + 1][i + k + 4] = temp_5;
B[j + 2][i + k + 4] = temp_6;
B[j + 3][i + k + 4] = temp_7;
}
/* B2 --> B3, A3 --> B2 */
for (k = 0; k < 4; k++) {
temp_0 = A[i + 4][j + k];
temp_1 = A[i + 5][j + k];
temp_2 = A[i + 6][j + k];
temp_3 = A[i + 7][j + k];
temp_4 = B[j + k][i + 4];
temp_5 = B[j + k][i + 5];
temp_6 = B[j + k][i + 6];
temp_7 = B[j + k][i + 7];
B[j + k][i + 4] = temp_0;
B[j + k][i + 5] = temp_1;
B[j + k][i + 6] = temp_2;
B[j + k][i + 7] = temp_3;
B[j + k + 4][i] = temp_4;
B[j + k + 4][i + 1] = temp_5;
B[j + k + 4][i + 2] = temp_6;
B[j + k + 4][i + 3] = temp_7;
}
/* A4 --> B4 */
for (k = 4; k < 8; k++) {
temp_0 = A[i + k][j + 4];
temp_1 = A[i + k][j + 5];
temp_2 = A[i + k][j + 6];
temp_3 = A[i + k][j + 7];
B[j + 4][i + k] = temp_0;
B[j + 5][i + k] = temp_1;
B[j + 6][i + k] = temp_2;
B[j + 7][i + k] = temp_3;
}
}
/* top right */
for(j = 56; j < M; j++){
temp_0 = A[i][j];
temp_1 = A[i+1][j];
temp_2 = A[i+2][j];
temp_3 = A[i+3][j];
temp_4 = A[i+4][j];
temp_5 = A[i+5][j];
temp_6 = A[i+6][j];
temp_7 = A[i+7][j];
B[j][i] = temp_0;
B[j][i+1] = temp_1;
B[j][i+2] = temp_2;
B[j][i+3] = temp_3;
B[j][i+4] = temp_4;
B[j][i+5] = temp_5;
B[j][i+6] = temp_6;
B[j][i+7] = temp_7;
}
}
/* buttom left */
for (i = 64; i < 67; i++) {
for (j = 0; j < 56; j += 8) {
temp_0 = A[i][j];
temp_1 = A[i][j + 1];
temp_2 = A[i][j + 2];
temp_3 = A[i][j + 3];
temp_4 = A[i][j + 4];
temp_5 = A[i][j + 5];
temp_6 = A[i][j + 6];
temp_7 = A[i][j + 7];
B[j][i] = temp_0;
B[j + 1][i] = temp_1;
B[j + 2][i] = temp_2;
B[j + 3][i] = temp_3;
B[j + 4][i] = temp_4;
B[j + 5][i] = temp_5;
B[j + 6][i] = temp_6;
B[j + 7][i] = temp_7;
}
}
/* buttom right */
for (i = 56; i < 61; i++) {
temp_0 = A[64][i];
temp_1 = A[65][i];
temp_2 = A[66][i];
B[i][64] = temp_0;
B[i][65] = temp_1;
B[i][66] = temp_2;
}
}
https://github.com/WeiLin66/CMU-15-213/tree/main/Labs/cache-lab
 Zacch
Zacch
