YOLO v7 才release沒多久(2022/7/12),沒想到 v8 又在2023/1/10 推出,事隔不到半年,令人應接不暇,v8 是由 v5 的原創公司 Ultralytics 改良的,顯然是與中研院團隊卯上了,v4、v7是中研院王建堯博士提出的,兩者良性競爭,大眾受惠。
依據YOLO v8 官網文件說明,主要改良特點如下:
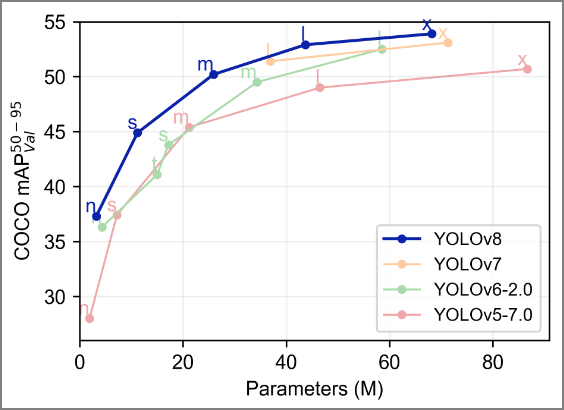
圖一. YOLO v8 vs. v7 參數量與 mAP 比較,圖片來源:YOLO v8 GitHub
安裝需求為 v3.10>=Python>=v3.7,PyTorch v1.7或以上版本,安裝指令如下:
pip install ultralytics
但是,在Windows作業系統下測試出現錯誤訊息如下:
'cv2' has no attribute 'gapi_wip_gst_GStreamerPipeline'
Google搜尋解法是要安裝舊版的OpenCV-python,指令如下:
pip install opencv-python-headless==4.5.5.64
打開終端機或cmd,輸入以下指令,進行物件偵測:
yolo predict model=yolov8n.pt source="https://ultralytics.com/images/bus.jpg"
偵測的照片 bus.jpg 如下:
執行結果:偵測到以下物件。
太強了,人只出現一隻手或腳都認得出來,交通號誌也只出現一半。
再拿 YOLO v4 的測試照片試一下:
偵測到以下物件:1 bicycle, 1 car, 1 truck, 1 dog,出現錯誤,一輛車子被辨識成car跟truck,重複了,另外,車子旁邊的垃圾桶沒有偵測到,v4、v7 都有偵測到,v5、v8都沒有偵測到,中研院團隊勝。再以較大的模型偵測,車子沒有重複偵測,但垃圾桶還是沒有偵測到。
v4 可參考『YOLO v4 建置心得 -- Windows 環境』、『YOLO v4 模型訓練實作』,v7 可參考『YOLO v7 實測』。
v8 支援手機,可安裝App,筆者初步測試,播放還算順暢,但物件偵測不是很快,可在Google Play搜尋 【Ultralytics】,即可找到該App,安裝需求不高,筆者使用免費手機也是OK的啦。
以上是直接使用指令,有時候會想要撰寫程式,顯示更多訊息,例如顯示照片中的物件位置,官網範例如下:
from ultralytics import YOLO
# Load a model
model = YOLO("./yolov8n.yaml") # build a new model from scratch
model = YOLO("./yolov8n.pt") # load a pretrained model (recommended for training)
# 預測
results = model("./bus.jpg")
# 顯示物件類別
print(results[0].boxes.cls)
print()
# 顯示物件座標
print(results[0].boxes.xyxy)
結果如下:
物件類別代碼:[ 5., 0., 0., 0., 11., 0.]
物件座標:
tensor([[ 17., 231., 802., 768.],
[ 49., 399., 245., 903.],
[670., 380., 810., 876.],
[221., 406., 345., 857.],
[ 0., 255., 32., 325.],
[ 0., 551., 67., 874.]], device='cuda:0')
要顯示照片中的物件位置,可以下列程式存檔。
from ultralytics import YOLO
from PIL import Image
import cv2
model = YOLO("./yolov8n.pt")
# webcam
# results = model.predict(source="0")
# 整個目錄
# results = model.predict(source="folder", show=True)
# from PIL
im1 = Image.open("bus.jpg")
# save=True:存檔
results = model.predict(source=im1, save=True)
存檔位置預設在 runs\detect\predict 資料夾下。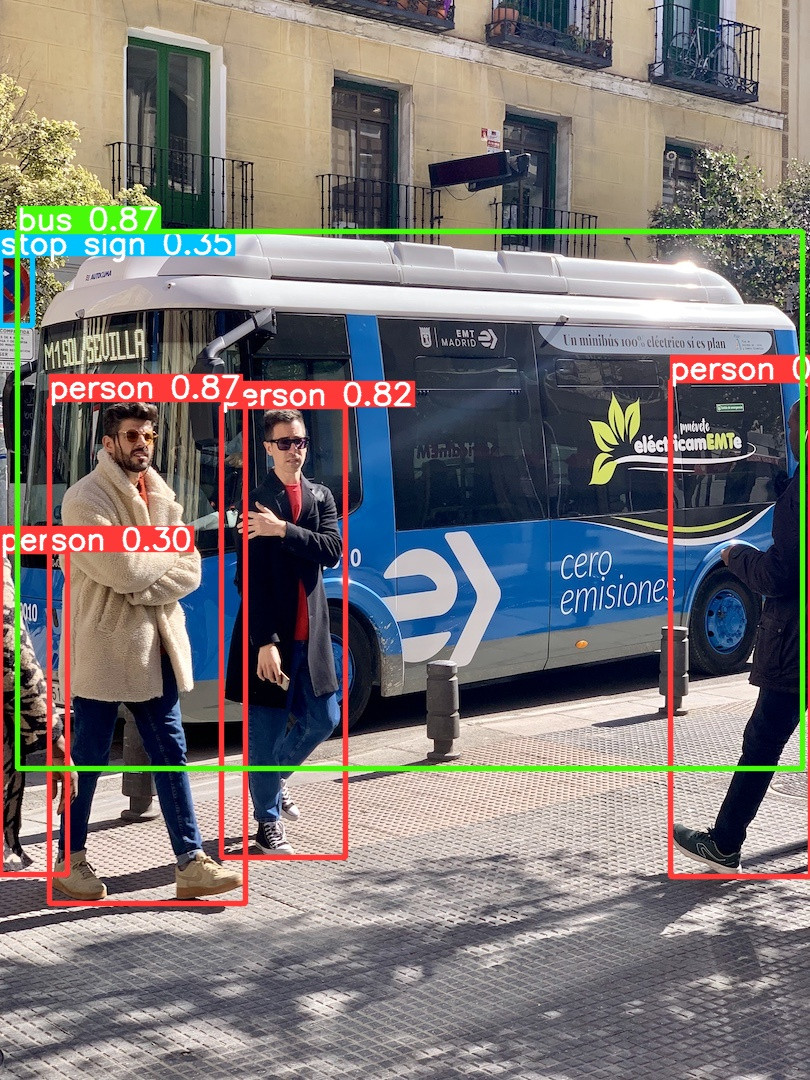
v8 除了物件偵測外,還可以進行影像分割(Image segmentation),筆者還沒研究,另外,預設模型是以COCO資料集作訓練,只能辨識80種物件,如何訓練自訂資料集,都是筆者之後會研究的課題。
v7 除了物件偵測、語義分割(mask)外,還可以進行姿態(Pose)偵測,筆者以影片測試,姿態偵測結果非常平順,初步感覺 v8 的優勢好像不太明顯。
夜深了,下次再分享嘍。
以下為工商廣告:)。
深度學習PyTorch入門到實戰應用影音課程:
PyTorch:
開發者傳授 PyTorch 秘笈
TensorFlow:
深度學習 -- 最佳入門邁向 AI 專題實戰。
 I code so I am
I code so I am
