python的docx模組功能很強,但還是有部份功能力有未逮。
首先在純word檔下以docx模組讀取檔案後,
是無法分辨出頁面內容的Soft Break!!
Soft Break就是我們在打word文件時,超過一頁時,word會自動幫你把內容放到下一頁。
另外有些人會以一直換行來分頁,這個也是Soft Break,這種方式在程式中都無法分辨跳頁。
docx模組可以分辨的是Hard Break,也就是手動的「分頁符號」和「分節符號」。
如果你不是上面的需求,再繼續往下看。
假設有2個word文件,
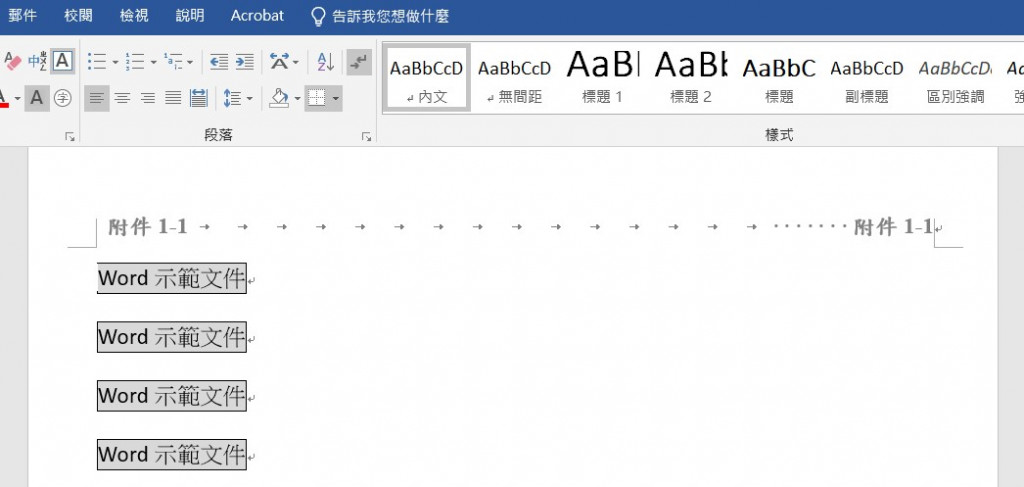
第1個文件要在所有頁面的頁首和頁尾加上檔名「附件1-1_XXXXXX.docx」的前幾個字「附件1-1」。
第2個文件要在所有頁面的頁首和頁尾加上檔名「附件2-1_XXXXXX.docx」的前幾個字「附件2-1」。
目標資料夾檔案如下: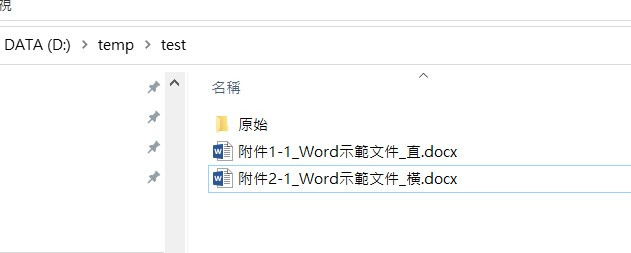
附件1-1_Word示範文件_直.docx的頁首: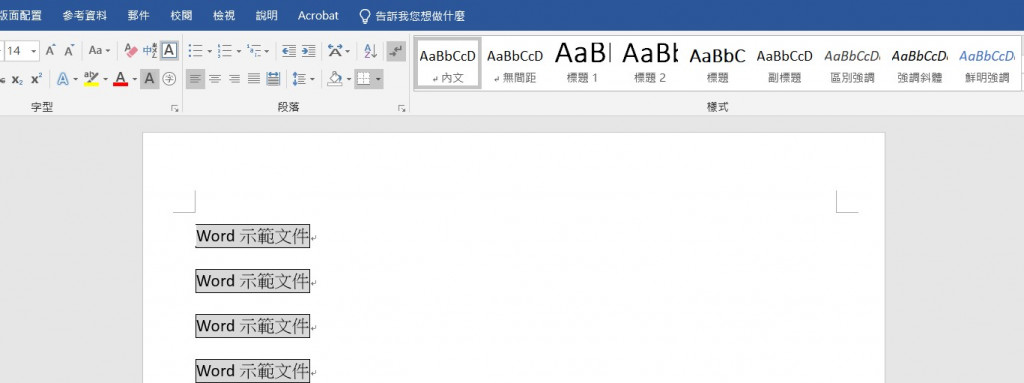
附件1-1_Word示範文件_直.docx的頁尾: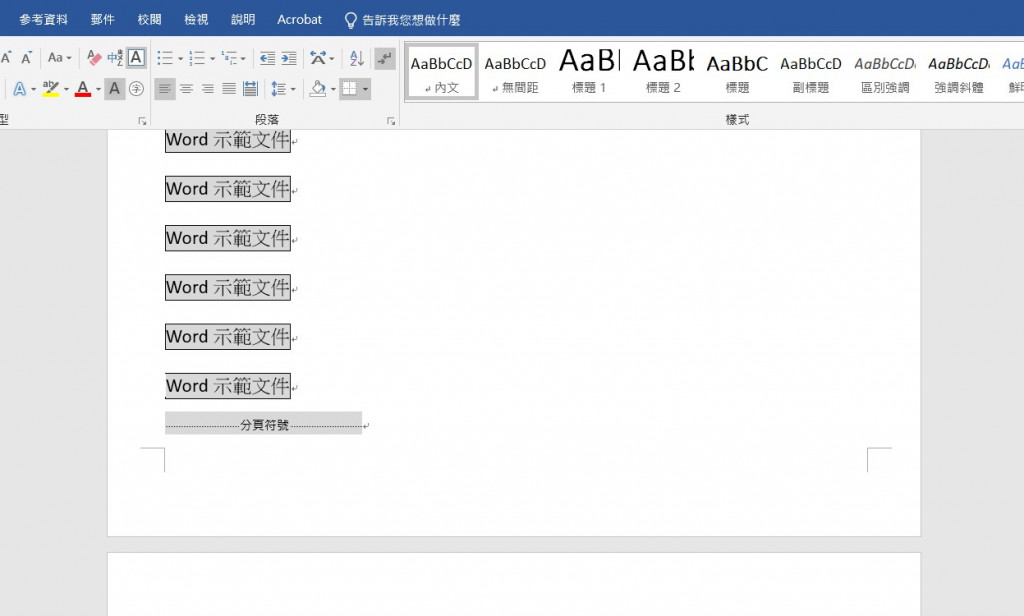
附件2-1_Word示範文件_橫.docx的頁首: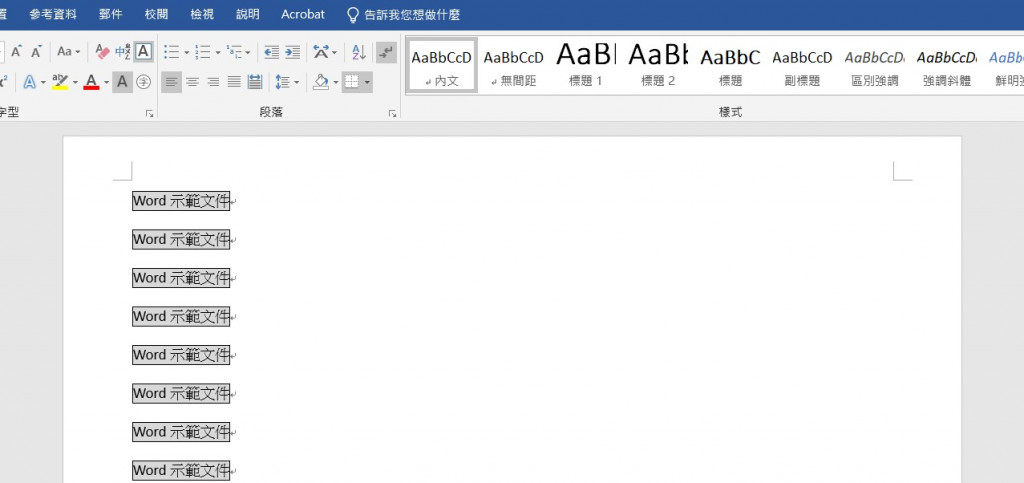
附件2-1_Word示範文件_橫.docx的頁尾: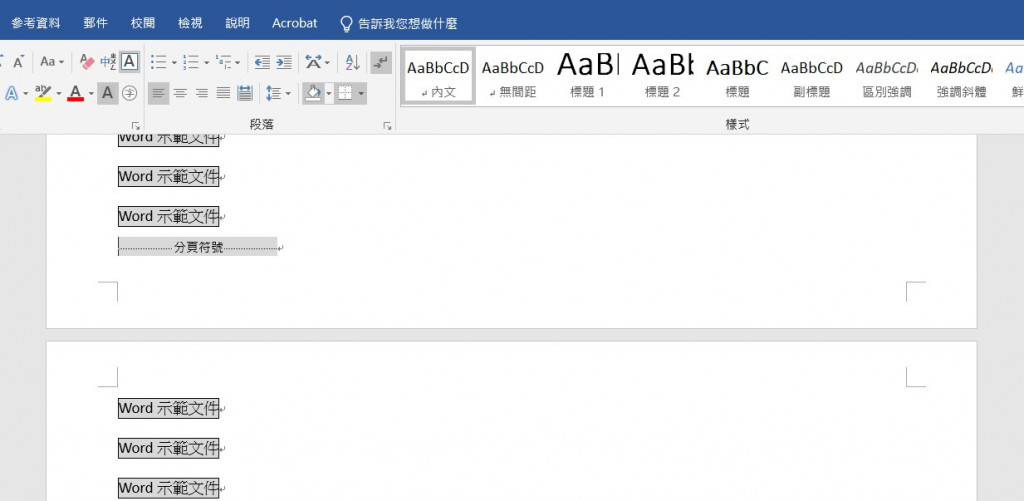
示範程式碼如下:
import os
import re
from docx import Document
from docx.shared import Pt, Cm
from docx.oxml.ns import qn
from docx.enum.text import WD_ALIGN_PARAGRAPH
# 設定目標資料夾
file_path = "d:\\temp\\test"
# 找出所有doc檔做成list
files = [x for x in os.listdir(file_path) if x.endswith(".docx")]
for file in files:
# Regex第一組括號是要找出附件○-○,做為頁首的文件
pattern = '(附件\d+-\d)_.+(.docx?$)'
target = re.findall(pattern, file)
# 找出符合Regex為pattern的檔案
if target:
print(file)
# header為頁首、頁尾的文字
header = target[0][0]
print(header)
# 目標docx檔案
docx_file = os.path.join(file_path, file)
# 加入頁首後之docx存檔命名
edited_docx_file = os.path.join(file_path, os.path.splitext(file)[0] + "_edited" + ".docx")
# 開啟目標docx檔案
document = Document(docx_file)
# 如果文件有分節,要遍歷所有的分節,如果文件沒有分節,那就可以直接用document.sections[0]來處理,不需要遍歷
for section in document.sections:
## 以下頁首的附件文件要在頁面左、右兩邊都加,所以要另外做判斷,讓文件的左右可以在正確的位置呈現附件的文字
## ---------------------------------------------------------------------------------
## 獲取頁面寬度
#page_width = section.page_width
## 獲取頁面高度
#page_height = section.page_height
## 假設文件都是A4直式或橫式,以下為判斷文件是直式或橫式
## 假如頁面高度大於頁面寬度,那就是A4直式
#if page_height > page_width:
# mytext = header + "\t"*15 + " " + header
#
## 假如頁面高度沒有大於頁面寬度,那就是A4橫式
#else:
# mytext = header + "\t"*23 + " " + header
## ---------------------------------------------------------------------------------
mytext = header
print(f'正在處理{docx_file}')
print('----------------------')
# 開始處理頁首
# --------------------------------------------------
h_paragraph = section.header.paragraphs[0]
# 設定頁首格式
h_paragraph_format = h_paragraph.paragraph_format
# 設定頁首靠右對齊
h_paragraph_format.alignment = WD_ALIGN_PARAGRAPH.RIGHT
# 設定頁首置中對齊
#h_paragraph_format.alignment = WD_ALIGN_PARAGRAPH.CENTER
# 設定頁首靠左對齊(內定為靠左對齊,所以不寫是一樣的效悲)
#h_paragraph_format.alignment = WD_ALIGN_PARAGRAPH.LEFT
# 以下是將頁首資料套用到文件
h_run = h_paragraph.add_run(mytext)
# 這個是設定粗體
h_run.bold = True
# 這個是設定字體大小為14
h_run.font.size = Pt(14)
# 這個是設定英文數字為 Times New Roman字型
h_run.font.name = 'Times New Roman'
# 這個是設定中文為微軟正黑體
#h_run._element.rPr.rFonts.set(qn('w:eastAsia'), u'微軟正黑體')
# 這個是設定中文為標楷體字型
h_run._element.rPr.rFonts.set(qn('w:eastAsia'), u'標楷體')
# --------------------------------------------------
# 開始處理頁尾
# --------------------------------------------------
f_paragraph = section.footer.paragraphs[0]
# 設定頁尾格式
f_paragraph_format = f_paragraph.paragraph_format
# 設定頁尾靠右對齊
f_paragraph_format.alignment = WD_ALIGN_PARAGRAPH.RIGHT
# 設定頁尾置中對齊
#f_paragraph_format.alignment = WD_ALIGN_PARAGRAPH.CENTER
# 設定頁尾靠左對齊(內定為靠左對齊,所以不寫是一樣的效悲)
#f_paragraph_format.alignment = WD_ALIGN_PARAGRAPH.LEFT
# 以下是將頁尾資料套用到文件
f_run = f_paragraph.add_run(mytext)
# 這個是設定粗體
f_run.bold = True
# 這個是設定字體大小為14
f_run.font.size = Pt(14)
# 這個是設定英文數字為 Times New Roman字型
f_run.font.name = 'Times New Roman'
# 這個是設定中文為微軟正黑體
#f_run._element.rPr.rFonts.set(qn('w:eastAsia'), u'微軟正黑體')
# 這個是設定中文為標楷體字型
f_run._element.rPr.rFonts.set(qn('w:eastAsia'), u'標楷體')
# --------------------------------------------------
document.save(edited_docx_file)
print('所有word檔加入附件之頁首頁尾:已完成')
程式執行結果:
程式處理完的資料夾:
程式處理完的檔案:
附件1-1_Word示範文件_直_edited.docx的頁首: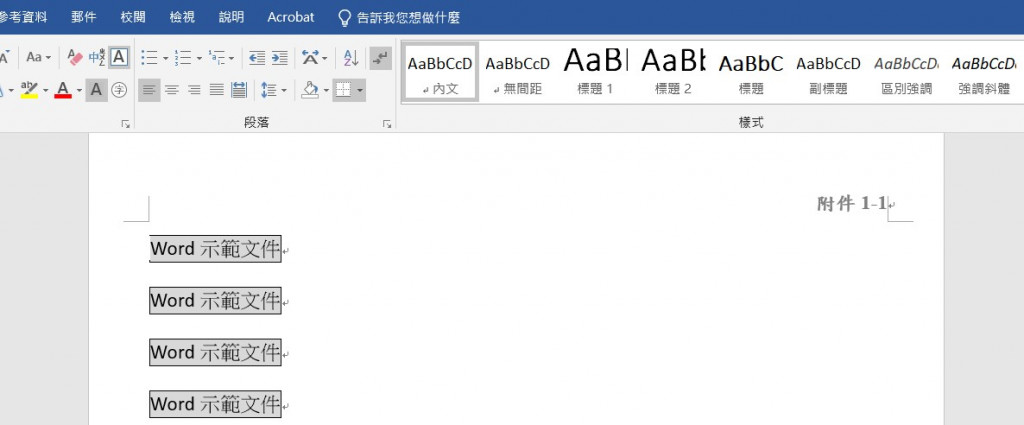
附件1-1_Word示範文件_直_edited.docx的頁尾: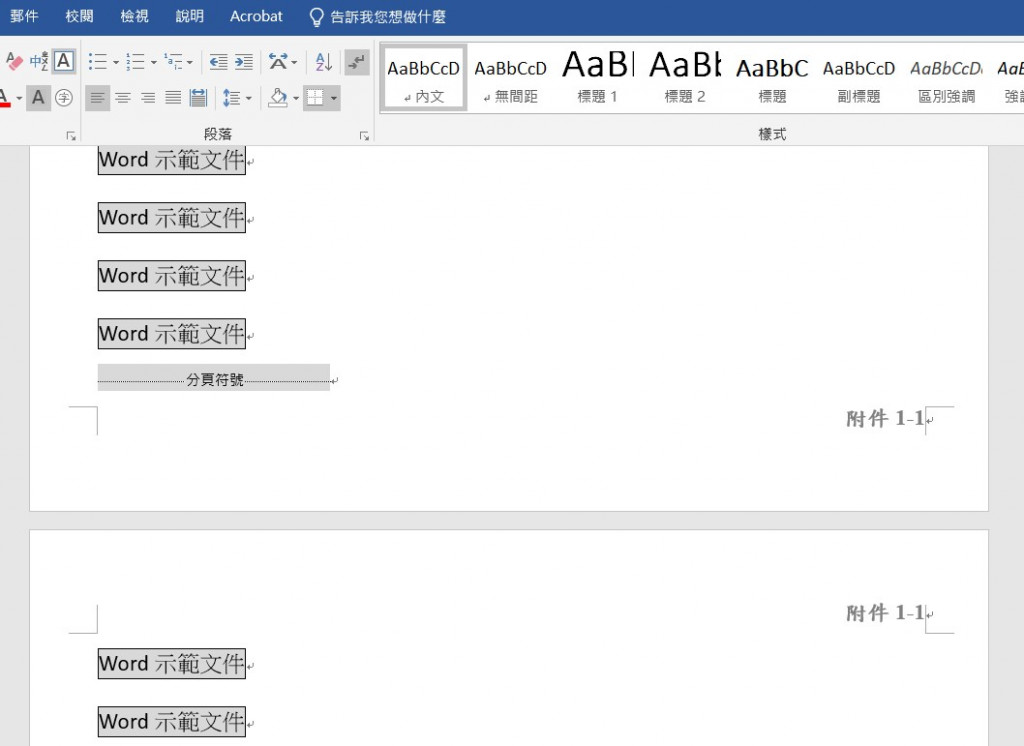
附件2-1_Word示範文件_橫_edited.docx的頁首: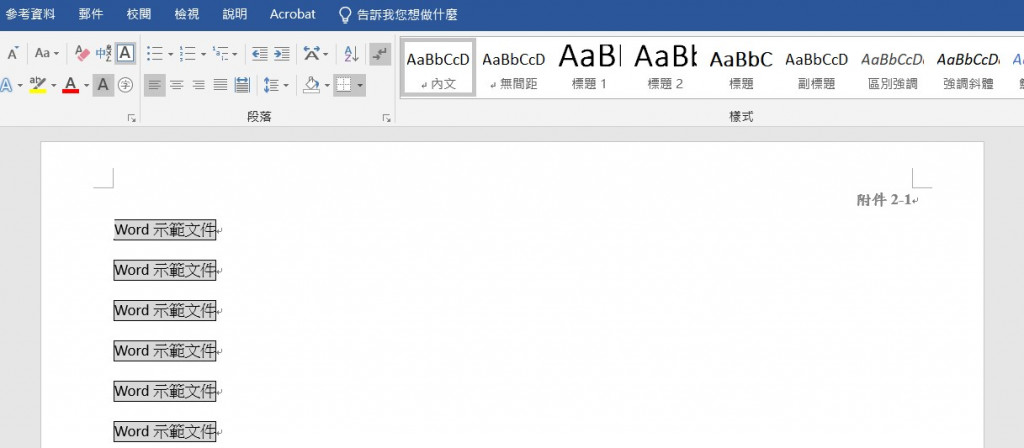
附件2-1_Word示範文件_橫_edited.docx的頁尾: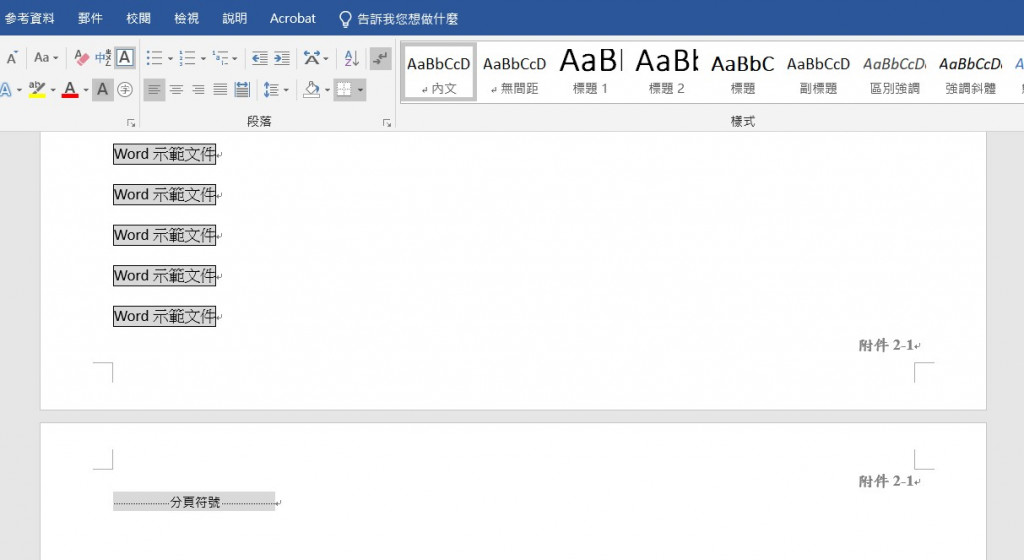
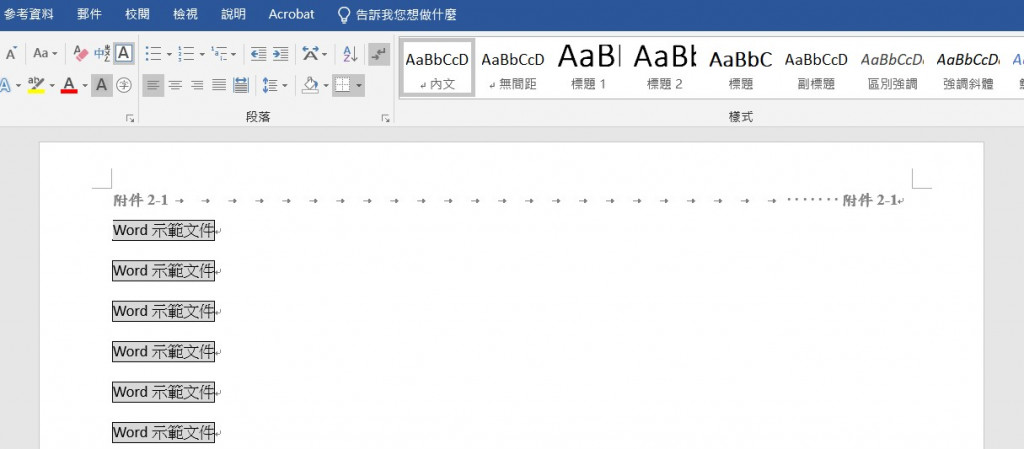
中間有一段mark掉的程式碼是先判斷文件是A4直式還是A4橫式,
再將頁首的附件1-1放在左邊,也放在右邊,處理的結果會是如此:
如果要使用,先將mytext = header給mark掉。
這一段h_paragraph_format.alignment = WD_ALIGN_PARAGRAPH.RIGHT也要mark掉
以上就是這次的分享!!
 mackuo
mackuo