前幾天我們聊的是 Develop,今天我們要暫時進入 Deploy 的部份。
在開始之前,務必把前幾天的異動提交並 merge to the main branch。
Deploy -> Environments
可以看到目前只有 Development Environment(開發環境),也就是我們在 DAY 02 所設定,從 DAY 04 到 DAY 06 使用的的 dataset: dbt_dev。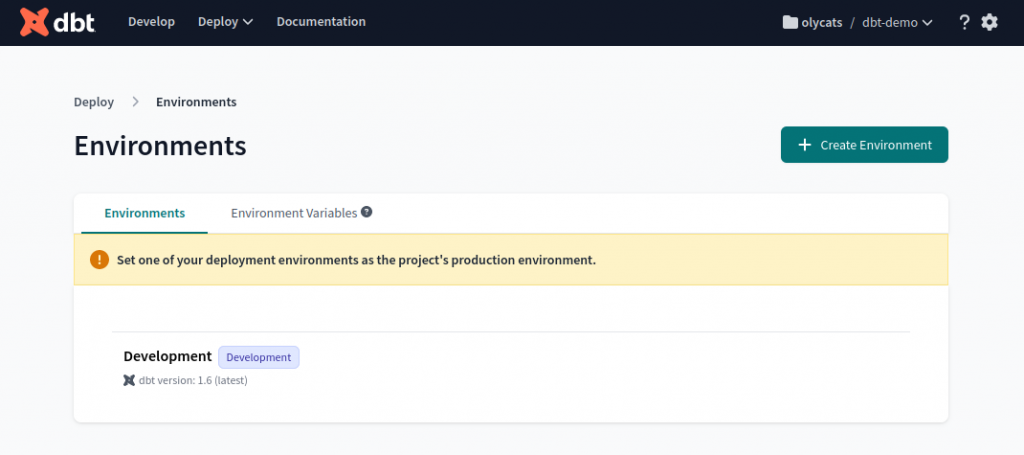
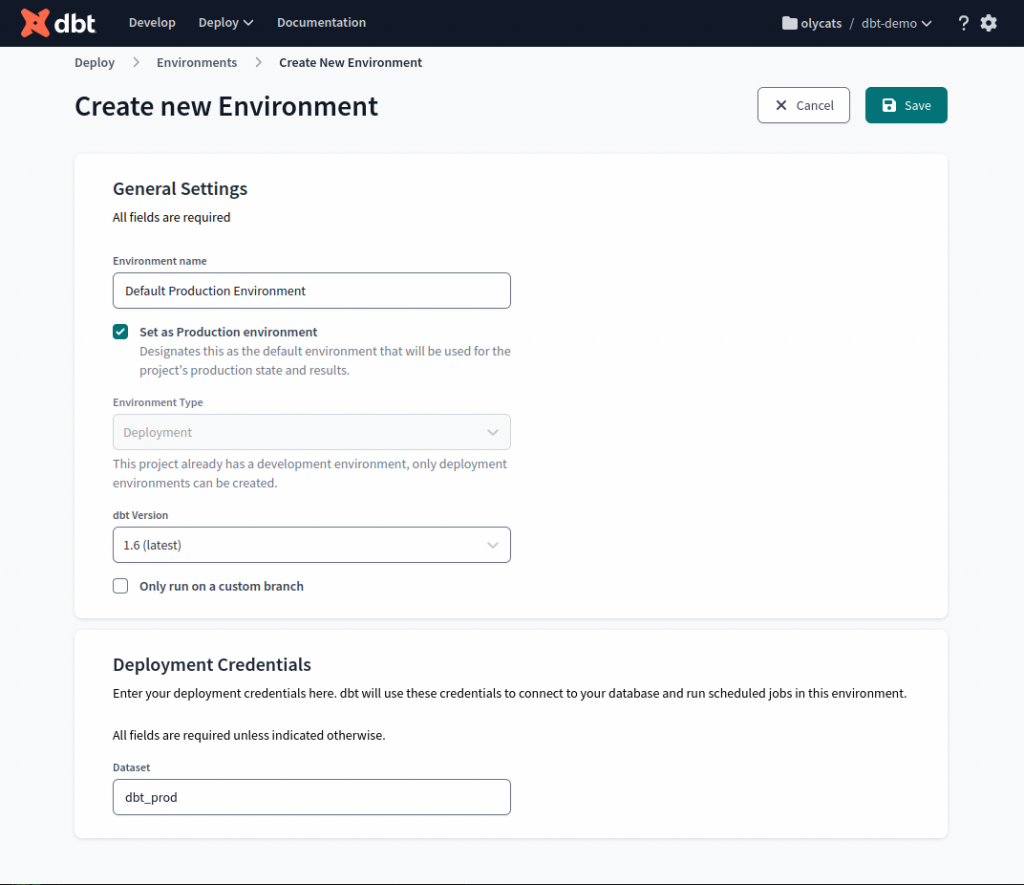
接下來我們要建立 Deployment Environment(佈署環境)。開發和佈署使用不同的 dataset,才不會讓開發的工作影響到正式的資料流程。不管在開發環境做了什麼事,都不應該破壞到正式的報表。
點選 Create Environment
Deploy -> Jobs
點選 Create Job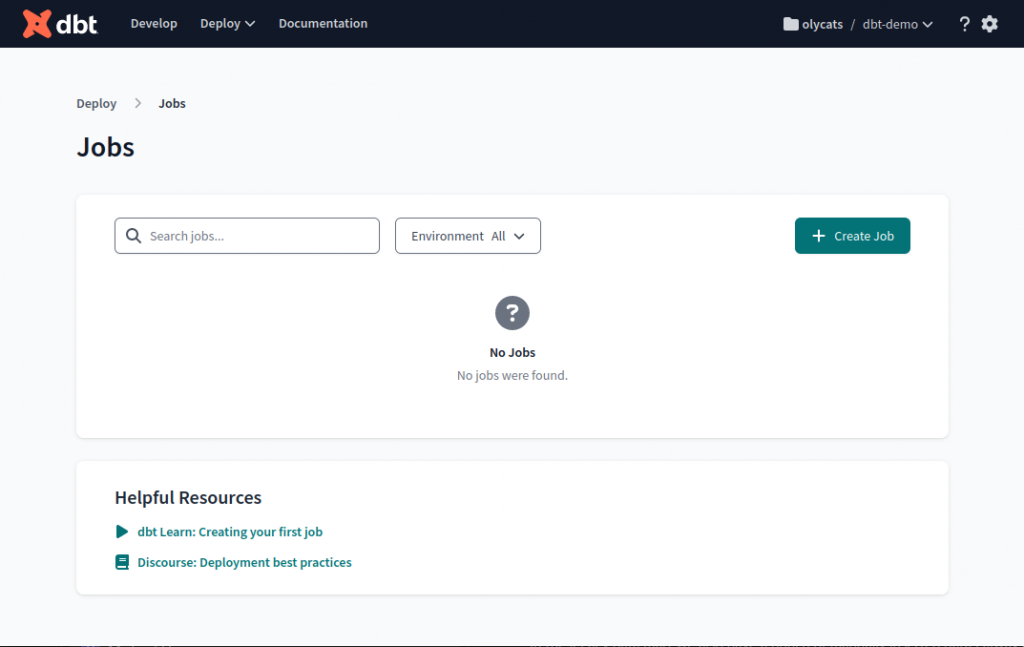
輸入 Job 名稱以及描述,例如 Default Build / Build all dbt models。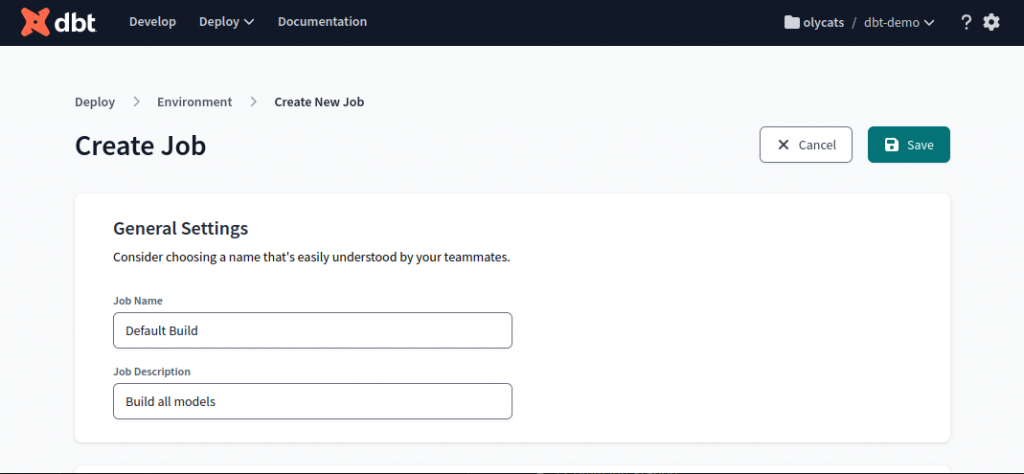
Environment 選剛剛新建的 Environment,其他都帶預設選項即可。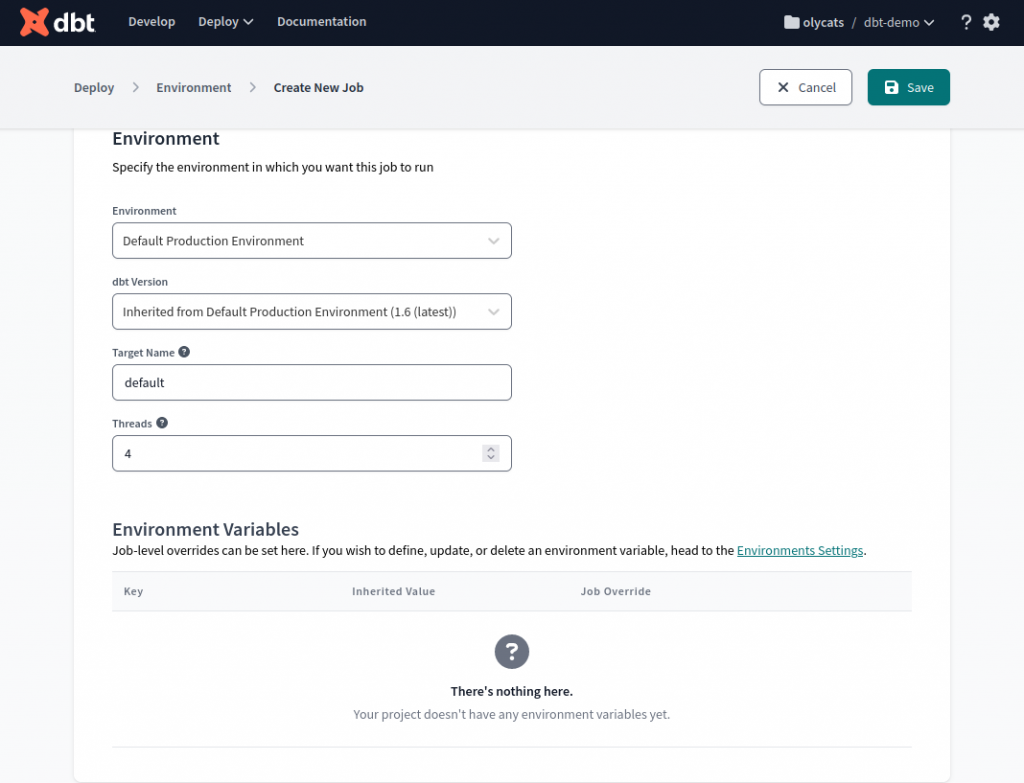
存檔完成後,按 Run Now。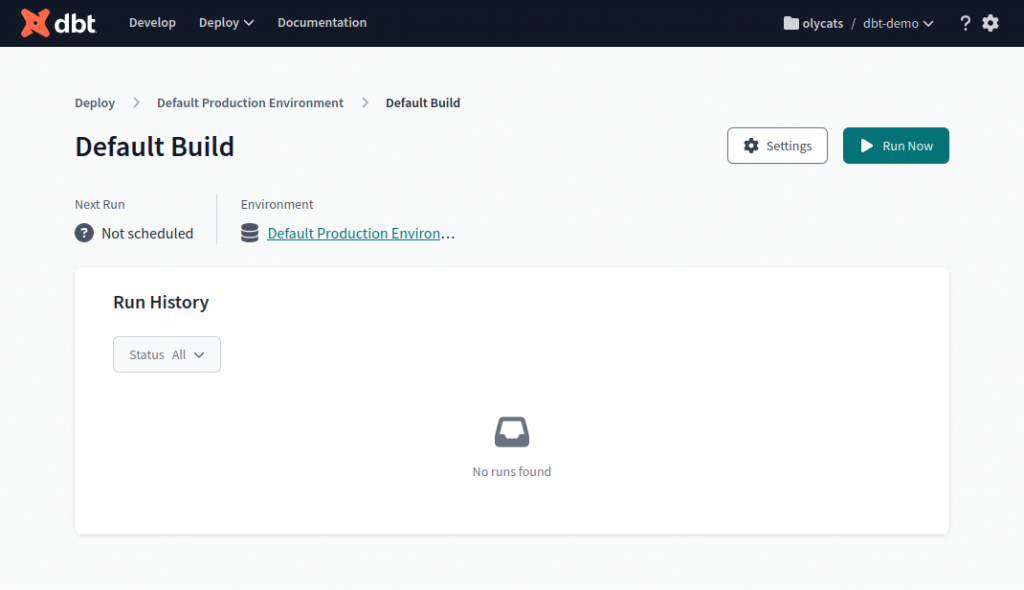
完成後顯示綠色勾勾表示成功。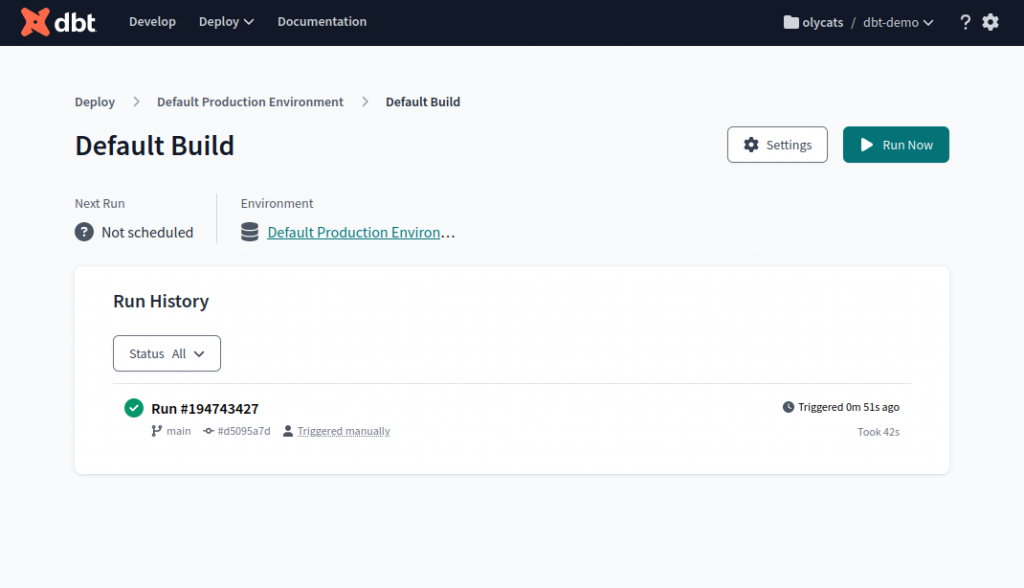
點進去可以看各個步驟的執行狀態。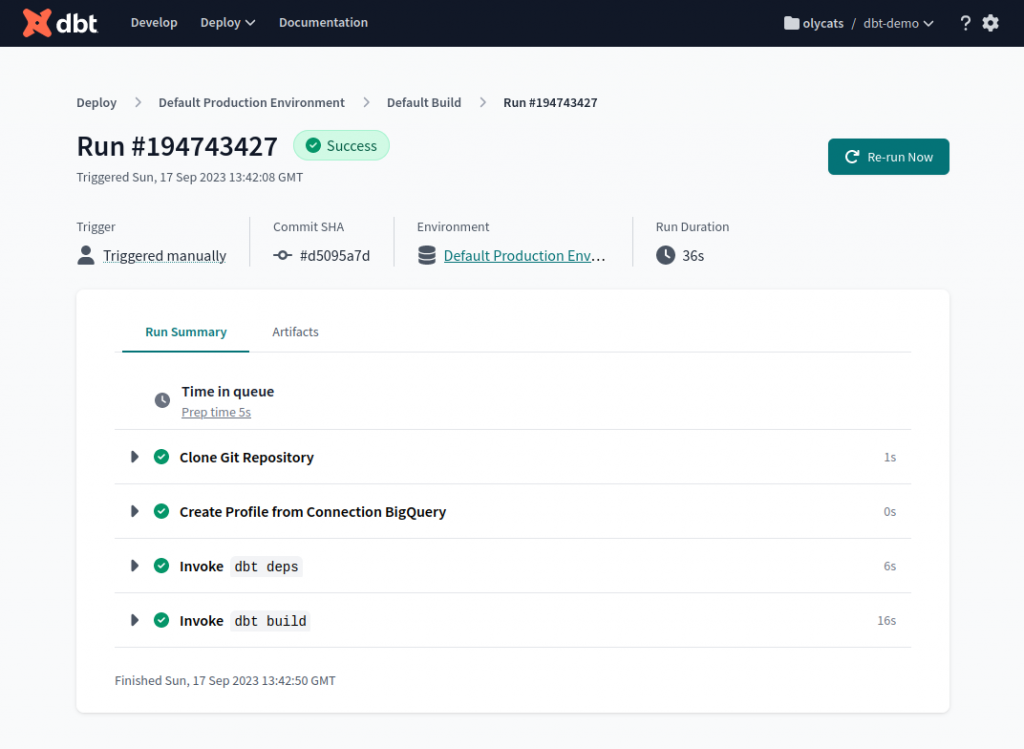
第一個步驟 Clone Git Repository,每次執行 job 時,都會抓最新的版本。
在 Job 列表可以清楚看到,每一次執行時,抓了哪一版 Commit #,或點進去 debug logs 也可以看到。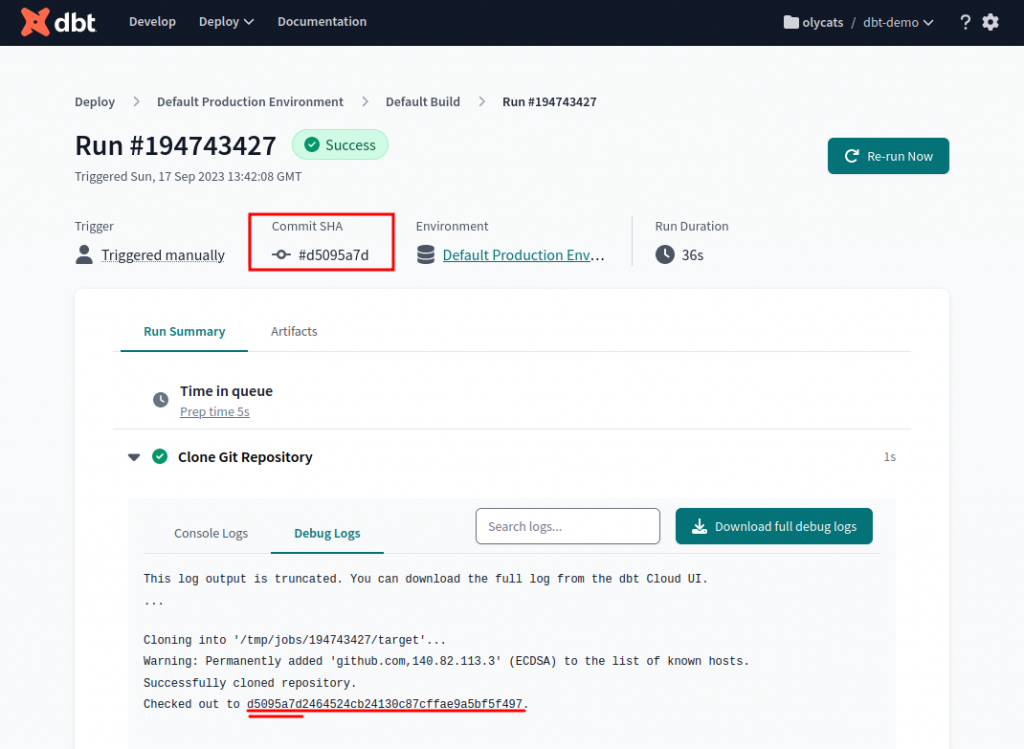
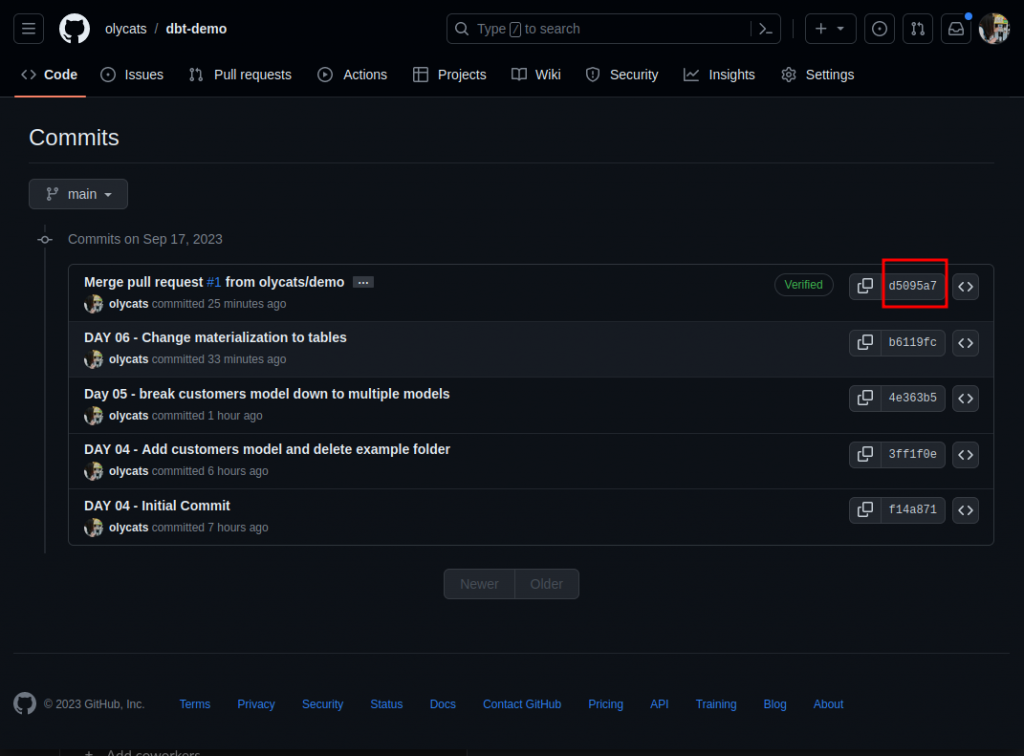
再來到 BigQuery 檢查結果。
可以看到執行完 job 後,自動生成了 dataset: dbt_prod
dbt models 也在這個 dataset 底下,產生了對應的 table 或 view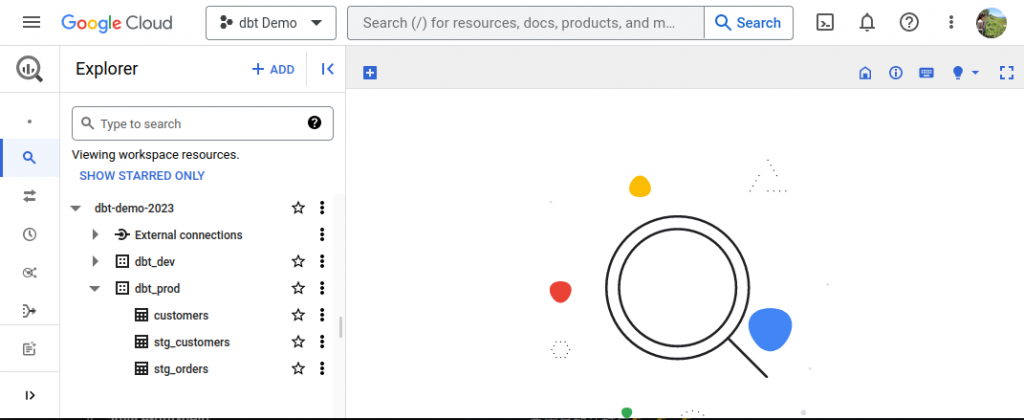
前幾天我們都是從 Development 開發環境執行指令。
今天我們在 Deployment 建立了正式環境,並執行了 Job。
可以在 BigQuery 看到,我們在 Development 和 Deployment 使用了不同的目標 dataset,也就是說開發環境和正式環境井水不犯河水,我們在開發時所作的任何異動,只會影響到 dataset: dbt_dev,而在正式環境跑的排程,用到的是 dataset: dbt_prod。
另外,每次正式環境執行的 job,都會到 GitHub 抓最新的 Commit #,強迫我們必須落實版控。
如果做任何異動,都必須 Commit 並 merge to main branch;任何我們 merge to main branch 的語法,每次執行 job 的時候也都會被抓進去。
過去我與 data team / data practitioners 共事的的經驗,很少有有正式環境、測試環境的區隔,也難完整落實版控,沒有上版的概念。
如果你是不懂 software development best practices 的 data practitioner,從今天開始,歡迎你正式加入 dbt 的世界,採用 dbt Cloud 這一套 deployment 流程,讓寫 SQL 也有點像個軟體工程師。
明天的主題:回到 development,為我們的 dbt 專案加入 tests,控管基本的資料品質。
歡迎加入 dbt community
對 dbt 或 data 有興趣 👋?歡迎加入 dbt community 到 #local-taipei 找我們,也有實體 Meetup 請到 dbt Taipei Meetup 報名參加

