
今天來介紹Index與Document的基礎語法:
Elasticsearch的API被設計成RESTful風格的HTTP API,代表我們在使用API最開頭的單字就是GET、POST、PUT與DELETE。而內部一樣是接JSON格式的資訊
Index基本操作:
創建:
// PUT 然後接索引名稱 設置部分先只需設定primary與replica shard的數量
PUT /test1
{
"settings":{
"number_of_shards": 1,
"number_of_replicas": 1
}
}

此時我們可以回想起之前說的,replica shard跟primary shard無法在同一個node上,那我們這時候去看
GET /_cat/shards?h=index,shard,prirep,state,unassigned.reason

可以看到replica shard沒有被分配到node中,這樣會導致叢集健康是黃色的,因為沒有node可以分配,並且也失去頂替primary shard的功能,所以我們這邊可以直接刪除索引
刪除:
// DELETE 然後接索引名稱
DELETE /index_name
刪除好後,我們再重新創一個索引來方便我們操作接下來的文檔部分
PUT /product
{
"settings": {
"number_of_replicas": 0
}
}
Document基本操作:
新增:
// 第一種:POST /索引名稱/_doc 底下欄位就自訂,隨便都可以
POST /product/_doc
{
"name": "coffee",
"price": 100,
"stocks": 10
}
// 第二種:PUT /索引名稱/_doc/id名(可自己定)
PUT /product/_doc/2
{
"name": "tea",
"price": 80,
"stocks": 10
}

這邊解釋一下結果中各項參數的意思
| 名稱 | 含義 |
|---|---|
| _index | 代表文檔存入的索引名稱 |
| _id | 每個文檔在索引中的唯一ID,可以用來檢索,更新或是刪除文檔。通常可以直接使用ES預設的id就好 |
| _version | 表示當前文檔的版本,被修改時會增加,可以用來避免資料衝突 |
| result | 可以分成created、updated 與deleted |
| _shards | 其中total是涉及到的總分片數,而剩下就是成功與失敗的個數。因為這邊只有primary shard所以是1 |
| _seq_no | 代表文檔的序列號碼,可以用於實現樂觀索 |
| _primary_term | 如果primary shard被更換時會發生改變 |
而獲取剛剛的文檔就可以使用GET
GET /product/_doc/2
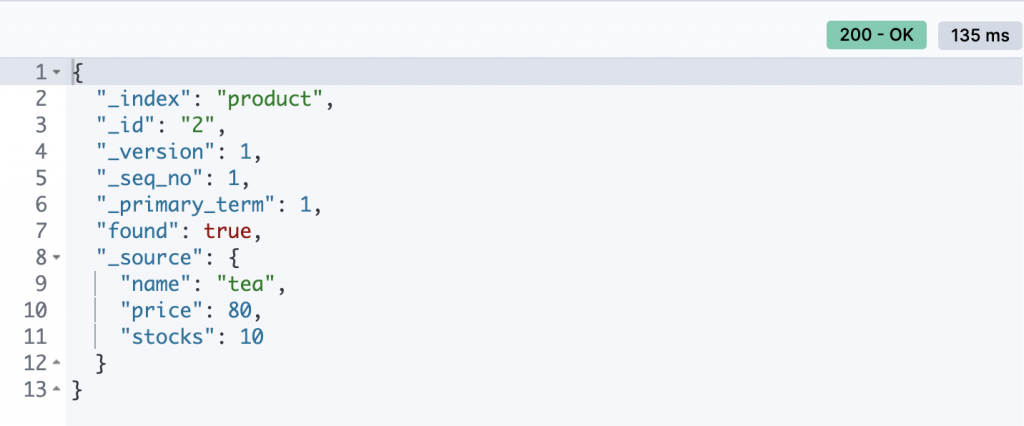
其中的_source代表原始的JSON數據,一般情況下是與實際數據沒有區別的
更新特定文檔
POST /product/_update/2
{
"doc": {
"stocks": 10
}
}
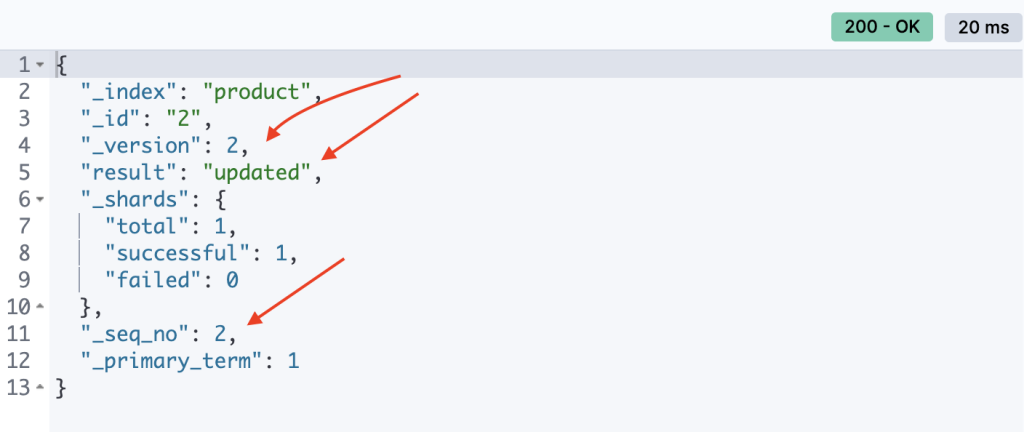
我們可以看到版本與seq_no都+1 並且result也是updated
甚至我們也可以直接新增同一個文檔其他的欄位
// POST /索引名稱/_update/id
POST /product/_update/2
{
"doc": {
"sell": 2
}
}
// 也能用PUT
PUT /product/_doc/2
{
"doc": {
"sell": 1
}
}
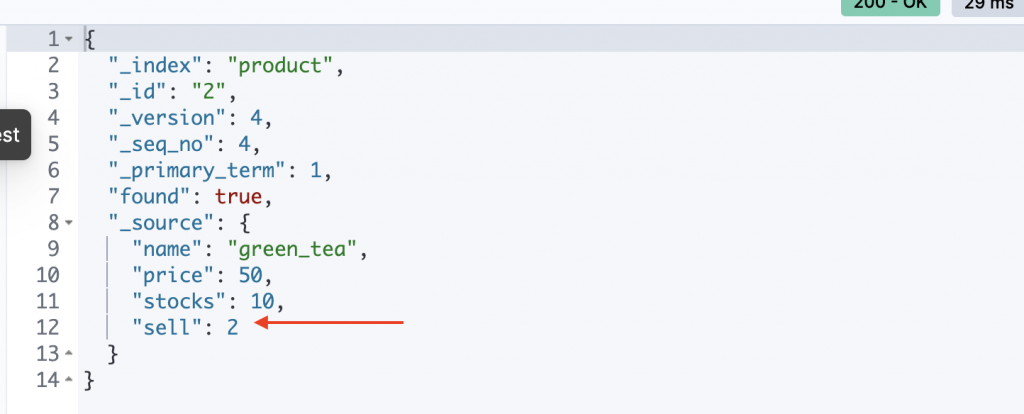
當然,前面有提到segment file是唯讀,因此這邊使用update API是先刪掉舊文檔,再創建新的
刪除特定文檔
DELETE /product/_doc/2
這邊對primary terms跟sequence numbers再延伸一下:
version補充:
version是幫助樂觀鎖的建立,例如說A跟B都獲得了產品的資料,但是如果A先修改產品資料但是此時B不知道,那這時B去修改可能就會造成錯誤,version就是要改善這個狀況
使用方式:
先獲取該文檔的primary term跟seq no,然後下post指令
POST /products/_update/100?if_primary_term=1&if_seq_no=11
所以如果是用舊的seq no就造成失敗,也能因此知道有人在過程中對文檔進行修改
最後可能會有人有疑問,前面提過每一個文檔是存在特定的primary shard,那ES要怎麼知道去要把文檔創建在哪個分片中,以及要刪除或是更新資料時又要去哪個shard中去找?這部分就會明天揭曉啦~

 iThome鐵人賽
iThome鐵人賽