
昨天說到ES要怎麼判斷文檔要分配在哪個分片?
有可能會有人說,如果是搜尋的話就把所有請求丟到各個分片就好了吧~
甚至更甚者,可能會覺得在哪個分片有很重要嗎?
但是如果沒有背後算法來決定的話,不光是造成查找效率下降,甚至每個分片的資料量也會非常不平衡。
而決定文檔分配到哪個分片就是路由(routing),並且路由也是請求要傳送到哪些分片的機制
跟據官方文檔我們可以知道基本的公式為:
routing_factor = num_routing_shards / num_primary_shards
shard_num = (hash(_routing) % num_routing_shards) / routing_factor
num_primary_shards:
在創建索引時設定的number_of_shards,也是代表primary shard一開始設定好的數量。只能在索引創建時設定,不能關閉索引時也不能更改。
num_routing_shards:
假設num_primary_shards:5
假設num_routing_shards:30
30 / 5 = 6
6的因數有2, 3, 6
未來可以將 num_primary_shards切割成
- 5 * 2 = 10
- 5 * 3 = 15
- 5 * 6 = 30
_routing:
預設為_id,這也是為什麼前面說_id可以直接讓ES決定就好。或是你可以改由自己設定routing
PUT my-index-000001/_doc/1?routing=user1&refresh=true
{
"title": "This is a document"
}
GET my-index-000001/_doc/1?routing=user1
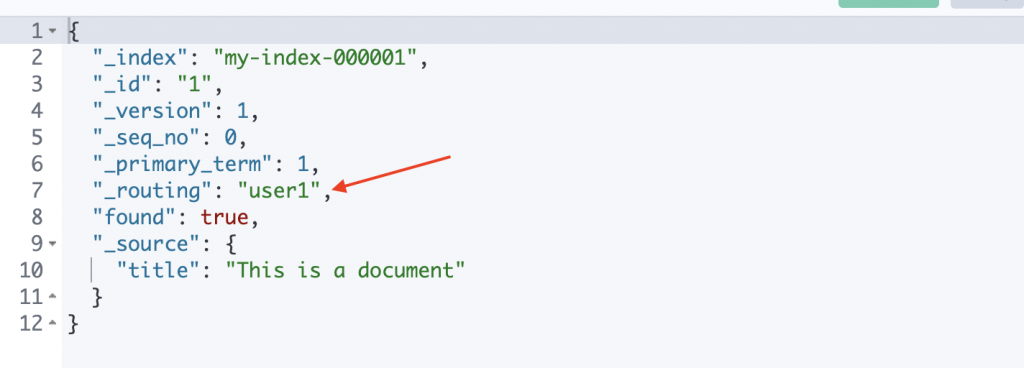
可以看到會多一個routing欄位
我們回到公式本身
首先計算出路由因子
接著我們要找出該文檔在哪個分片上
至於詳細文檔的讀寫原理,後面會有更詳細的篇幅介紹,這邊先丟個概念:
Search:
透過路由是找到primary shard或是replication group,接著ES會找出他覺得最好的replica shard,送出請求與獲得響應
Write:
跟讀不同的地方是,寫操作都是針對primary shard。當primary shard收到寫請求時,有效化請求,進行實施,同時並行對資料還沒同步的複製shard做一樣的操作
一般創建關係型資料表時,通常需要先定義好欄位的類型以及有哪些欄位
而我們前面在新增文檔時就是看我們心情,並且也可以隨時新增欄位也不用管類型
所以明天開始的幾天系列中,我們會開始介紹有關索引的Mapping設定,連帶引出分析器的觀念,並且介紹倒排索引這個相當重要的概念~

 iThome鐵人賽
iThome鐵人賽