超晚才開局的我要開始寫文章啦,大家程式設計師節快樂,做了十幾年的交易,量化交易也做一段時間了,近期想說都沒有人寫量化交易在雲端服務系統上的應用,所以我就來補一下坑。本篇教學主要會著重在量化交易數據分析跟GCP兩大區塊。量化交易的領域中有很多數據分析上的盲點,需要考量很多假設才有辦法下手,總之我們先開始,後面大家再看我慢慢講來~
這篇文章是以我從交易者轉職為資料科學家的角度來規劃的教學,主要使用的語言是Python。文章開頭會假設讀者已經有能力建立一個小的、基本的應用程式,並且已經爬取了一部分的數據(關於爬蟲太多人寫了,我就不獻醜了)。
以下是本次內容的目錄,請大家笑納~
量化交易的目的是為了讓我們進行交易時,可以不用長期盯盤,減輕交易過程的負擔。同時量化交易也因為有進行過數據分析,因此對於自己交易的信心會更加強烈,有所依據。當初我開始進行量化交易就是為了要讓生活可以真的是在生活,而不是受迫於交易過程的壓力。
量化交易分成以下幾個步驟:
本篇是第一天的文章,我們先輕鬆一點從資料取得開始。
資料取得有很多方式,其中最簡單的方式就是直接到政府的資料開放平台下載,缺點是可能會因為你忘記下載而導致資料缺漏。更好的方式是藉由購買以及爬蟲。
首先我們先說說爬蟲怎麼做吧!
目標先定為爬取資料開放平台。
首先開啟瀏覽器,點選開發人員選項,
使用左上角的選取網頁中的元素即可檢查,
將滑鼠移動到下載按鈕,觀察下載按鈕的HTML構造
會發現該下載按鈕是藉由前端語言觸發並非URL,這時候懶惰的我就會立刻改採用動態爬蟲。
動態爬蟲會以瀏覽器的測試驅動器執行,他會模擬使用者操作瀏覽器的方式,進行點按等動作。請注意近期Chrome的驅動器有改版,因此網路上大多教學文會失效。
首先我們先處理環境:
這裡使用的是 Python 10 ,pip更新至2023年9月最新的版本
第一步,我們先安裝 python 套件 selenium
pip install selenium
接下來我們安裝驅動器,請到官方網站詳細閱讀一下(最近更新的時候沒看清楚就坑了一小時):
https://chromedriver.chromium.org/downloads
https://googlechromelabs.github.io/chrome-for-testing/
撰寫一下程式碼:
# 導入 selenium 套件
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
import time
# 定義目標 URL
URL = "https://data.gov.tw/dataset/11549"
# 設定瀏覽器選項
options = Options()
options.add_argument("--disable-notifications")
# 指定 Chrome 驅動程式的路徑
driverpath = r"chromedriver.exe"
service = Service(driverpath)
# 啟動瀏覽器驅動程式
driver = webdriver.Chrome(service=service, options=options)
driver.get(URL)
# 如果網頁有某些元素需要等待加載,可以使用 WebDriverWait 方法,
# 這個方法會等待元素出現才會與之互動以避免元素還沒出現就意圖互動帶來的錯誤
# 下方程式碼如果10秒都沒有出現會報錯
try:
# 使用適當的定位方法,例如 By.ID, By.CLASS_NAME 等
# 注意 class 名稱中的空格需轉換成 "."
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located(
(By.CLASS_NAME, "el-button.download-button.el-button--primary.el-button--mini.is-plain"))
)
element.click()
finally:
# 等待 10 秒讓他下載
time.sleep(10)
# 請記得關閉瀏覽器避免占用資源
driver.quit()
爬取到的資料就可以放入資料庫儲存,以等待我們後續的處理。
(結果我還是寫了爬蟲XD)
靜態爬蟲:
靜態爬蟲主要用於獲取靜態網頁的內容,這些網頁的內容在原始碼中是固定的,並不依賴於任何用戶交互或JavaScript腳本執行。
動態爬蟲:
動態爬蟲用於獲取動態網頁的內容,這些網頁的內容通常由JavaScript腳本在用戶的瀏覽器中執行後渲染出來。
| 類型 | 優點 | 缺點 |
|---|---|---|
| 靜態爬蟲 | 1. 簡單、快速。 2. 不需要執行JavaScript。 3. 使用的資源較少。 | 1. 無法獲取基於JavaScript渲染的內容。 2. 有時可能會遇到反爬策略。 |
| 動態爬蟲 | 1. 可以獲取JavaScript渲染的內容。 2. 更適合現代的Web應用。 | 1. 比靜態爬蟲更為複雜。 2. 需要的資源和時間較多。 3. 有時需要模擬用戶交互。 |
購買的方式相對就簡單很多,市面上有很多購買的途徑。
我推薦由CMoney的法人決策系統取得資料,資料面相相當全面,並且有很方便的導出方式(他們的客服無微不至~)。
取得資料後我們就需要將資料儲存起來,這裡提供兩種方式,分別是SQLite以及BigQuery,兩者差別如下:
我們的計畫是,利用Python把資料先輸入到SQLite作為資料表的中繼站,而後我們可以將資料輸入BigQuery。因為爬下來的資料可能很髒,所以可以藉由SQLite進行約束、資料整理,並且能批量上傳數據以減少上傳次數。
SQLite是遵守ACID的關聯式資料庫管理系統,它包含在一個相對小的C程式庫中。與許多其它資料庫管理系統不同,SQLite不是一個客戶端/伺服器結構的資料庫引擎,而是被整合在使用者程式中。
SQLite是什麼呢?想像一下你有一個玩具盒。這個玩具盒非常特別,因為不僅可以放玩具,還可以快速找到你想要的玩具,記錄玩具的名字,甚至可以記錄哪些玩具是一組的。這個玩具盒就像是SQLite。
那麼,SQLite的優勢是什麼呢?
輕巧簡單:SQLite就像那個小巧的玩具盒,不需要特別的架子或工具就可以使用。在電腦上,它不需要特別的安裝或設定,只需要一個小小的檔案就可以運作。
隨身攜帶:想像一下,如果你今天到朋友家玩,你可以把整個玩具盒帶去,而不只是帶一些玩具。SQLite的資料庫是一個單一的檔案,所以你可以很容易地把它帶到其他地方,或分享給朋友。
不需要特別的照顧:有些玩具盒可能需要特別的鎖或密碼才能打開。但是SQLite很簡單,不需要特別的管理或維護。
要安裝SQLite很簡單,先到這個網站下載程式安裝就可以在python中直接使用。
我們先來寫一下將資料寫入SQLite的程式碼~
# 匯入必要的函式庫
import pandas as pd
import sqlite3
def save_csv_to_sqlite(file_path, db_path):
"""
從CSV檔案中讀取資料並儲存到SQLite資料庫。
參數:
- file_path: CSV檔案的路徑。
- db_path: 要儲存SQLite資料庫的路徑。
"""
# 從CSV檔案中載入資料到pandas DataFrame
df = pd.read_csv(file_path, encoding='utf-8')
# 將原始的欄位名稱映射到其英文名稱
column_mapping = {
"證券代號": "stock_code",
"證券名稱": "stock_name",
"成交股數": "transaction_volume",
"成交金額": "transaction_amount",
"開盤價": "opening_price",
"最高價": "highest_price",
"最低價": "lowest_price",
"收盤價": "closing_price",
"漲跌價差": "price_difference",
"成交筆數": "transaction_count"
}
# 根據映射更改DataFrame的欄位名稱
df.rename(columns=column_mapping, inplace=True)
# 與SQLite資料庫建立連線
with sqlite3.connect(db_path) as conn:
# 將DataFrame的資料儲存到SQLite資料庫中,命名為'stock_data'的表格
# 如果已存在同名的表格,則會被替換
df.to_sql("stock_data", conn, if_exists="replace", index=False)
# 使用指定的路徑呼叫函數
file_path = "/mnt/data/STOCK_DAY_ALL_20230912.csv"
database_path = "/mnt/data/stock_data.sqlite"
save_csv_to_sqlite(file_path, database_path)
讀取資料到SQLite的方法如下:
def read_from_sqlite(db_path, table_name):
"""
使用pandas從SQLite資料庫中讀取資料。
參數:
- db_path: SQLite資料庫的路徑。
- table_name: 要讀取的資料表名稱。
返回:
- DataFrame: 包含資料表內容的pandas DataFrame。
"""
# 與SQLite資料庫建立連線
with sqlite3.connect(db_path) as conn:
# 使用pandas從資料庫中讀取資料
df = pd.read_sql(f"SELECT * FROM {table_name}", conn)
return df
# 使用指定的路徑和表名呼叫函數
database_path = "/mnt/data/stock_data.sqlite"
table_name = "stock_data"
data = read_from_sqlite(database_path, table_name)
print(data.head())
首先python要安裝套件,就裝一下吧~
pip install --upgrade google-cloud-bigquery
BigQuery有很多連線方式(好像有四種),[官網推薦的是以下這種]:(https://cloud.google.com/bigquery/docs/reference/libraries?hl=zh-cn#client-libraries-install-python)
from google.cloud import bigquery
# 建構一個BigQuery客戶端物件。
client = bigquery.Client()
query = """SELECT *
FROM `trade-397602.stock_pool.stock_pool`
LIMIT 1000
"""
query_job = client.query(query) # 發起一個API請求。
print("查詢的資料:")
for row in query_job:
# 透過欄位名稱或索引來訪問行值。
print("pool_id={}, stock_id={}".format(row['pool_id'], row["stock_id"]))
目前我們先連上就好,之後會再詳細講解如何運用BigQuery進行分析。
寫到這裡也有點累了(竟然已經6600字!?)。先來簡單練練手,做為今天練習的結束吧~
我們會使用到TAlib這個套件,但是這個套件比較麻煩不能用pip處理
首先進入此網站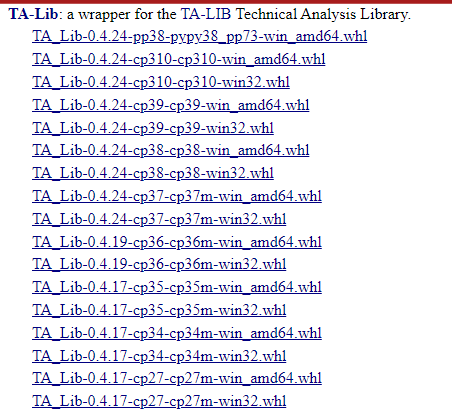
選擇自己電腦的環境:
cp310是 python 3.10 版,不要選錯歐~
進入命令提示字元cmd輸入以下指令:
cd 你下載檔案的路徑
pip install TA_Lib-0.4.24-cp310-cp310-win_amd64.whl
為了方便,接下來都以這份資料作分析。
我們讀取之後可以發現資料主要由以下欄位構成:
股票代號、股票名稱、日期、開盤價、收盤價、最高價、最低價、成交量
因為技術指標一次只需要計算一檔標的(股票),所以我們限制query在(台泥1101TT)上
import talib as ta
import pandas as pd
import numpy as np
df = pd.read_csv('transformed_data.csv')
print(df)
slowk, slowd = ta.STOCH(df.query('股票代號 == 1101')['最高價'], df.query('股票代號 == 1101')['最低價'], df.query('股票代號 == 1101')['收盤價'], fastk_period=5, slowk_period=3, slowk_matype=0, slowd_period=3, slowd_matype=0)
print(slowd)
今天先講到這裡~ 明天我們來談談機器學習的標註如何做在股票市場上。

