這幾天大概就是把常見的算法跟應用跑一遍 Demo
1.可以先參考這個:維基百科的介紹
2.感知器(Perceptron):裡面的一種常見算法(基本結構):感知器:維基百科的介紹
3.多層感知器(MLP):感知器延伸出出的一種常見算法(基本結構):多層感知器:維基百科的介紹
4.這邊是MLP在kaggle上的一個簡單應用:Simple deep MLP with Keras
5.這個是稍微進階一點的應用:Simple Pytorch Tensorflow MLP
(聲明:以下內容都是在網路上整理並修改的,真正我原創的內容並不多,我主要只是搬運工)
(聲明:以下內容都是在網路上整理並修改的,真正我原創的內容並不多,我主要只是搬運工)
下面程式碼是一個使用 Keras 和 Weights and Biases(wandb)庫來訓練一個基本的神經網絡模型來分辨數字的範例程式碼。
主要流程如下:
此程式碼使用 MSE 作為損失函數,並沒有在輸出層使用激活函數。
!pip install wandb
# 從wandb儲存庫中導入所需的模組和函數
from keras.datasets import mnist # 導入MNIST數據集
from keras.models import Sequential # 導入Keras的Sequential模型
from keras.layers import Dense, Flatten ## 導入Dense(全連接層)和Flatten(平坦層)
from keras.utils import to_categorical# 導入one-hot編碼工具
import wandb # 導入Weights and Biases庫
from wandb.keras import WandbCallback # 導入Wandb的Keras回調
# 初始化Wandb,用於記錄
run = wandb.init()
config = run.config # 創建配置對象,用於存儲訓練參數
# 加載MNIST數據集
(X_train, y_train), (X_test, y_test) = mnist.load_data()
img_width = X_train.shape[1] # 獲取圖像的寬度
img_height = X_train.shape[2] # 獲取圖像的高度
# # 對輸出標籤進行one-hot編碼
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
labels = range(10) # 創建一個包含0-9的列表,代表10個數字類別
num_classes = y_train.shape[1] # 獲取類別的數量(這裡是10)
# 創建Sequential模型
model = Sequential()
model.add(Flatten(input_shape=(img_width, img_height)))# 添加平坦層,將28x28的圖像轉換為784維的向量
model.add(Dense(num_classes))# 添加全連接層,有10個輸出單元(對應10個類別)
# 編譯模型
model.compile(loss='mse', optimizer='adam',
metrics=['accuracy'])# 使用均方誤差作為損失函數,adam優化器,並記錄準確性
# Fit the model 訓練模型
model.fit(X_train, y_train, epochs=10, validation_data=(X_test, y_test),
callbacks=[WandbCallback(data_type="image", labels=labels, save_model=False)])
# 保存模型
model.save('model.h5')# 將訓練好的模型保存為H5文件
下面程式碼是一個使用 Keras 和 Weights and Biases(wandb)庫來訓練一個基本的神經網絡模型來分辨數字的範例程式碼。
這個代碼主要做了以下幾件事:
此程式碼使用分類交叉熵作為損失函數,並在輸出層使用了 Softmax 激活函數。
# 導入所需的Keras模組
from keras.datasets import mnist # 導入MNIST數據集
from keras.models import Sequential # 導入Sequential模型
from keras.layers import Dense, Flatten # 導入Dense和Flatten層
# taken from lukas/ml-class
from keras.utils import to_categorical # 導入one-hot編碼工具
# 導入wandb庫和其Keras回調
import wandb
from wandb.keras import WandbCallback
# 初始化Wandb用於記錄模型訓練過程
run = wandb.init()
config = run.config # 配置訓練參數
# 加載MNIST數據集
(X_train, y_train), (X_test, y_test) = mnist.load_data()
img_width = X_train.shape[1] # 圖像寬度
img_height = X_train.shape[2] # 圖像高度
# 對目標變量進行one-hot編碼
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
labels = range(10)# 0到9的標籤列表
num_classes = y_train.shape[1]# 總類別數
# 創建Sequential模型
model = Sequential()
model.add(Flatten(input_shape=(img_width, img_height)))# 添加Flatten層以平坦化圖像
model.add(Dense(num_classes, activation='softmax'))# 使用交叉熵作為損失函數,adam作為優化器
# 編譯模型
model.compile(loss='categorical_crossentropy', optimizer='adam',
metrics=['accuracy'])# 使用交叉熵作為損失函數,adam作為優化器
model.summary()# 打印模型摘要信息
# 訓練模型
model.fit(X_train, y_train, epochs=10, validation_data=(X_test, y_test),
callbacks=[WandbCallback(data_type="image", labels=labels, save_model=False)])
下面的程式碼也是使用 Keras 來建立和訓練一個神經網絡模型,基於 MNIST 數據集。但這份程式碼跟上面有一些顯不同之處:
添加了一個隱藏層:
新程式碼中添加了一個具有 100 個神經元和 ReLU 激活函數的隱藏層。
model.add(Dense(config.hidden_nodes, activation='relu'))
這通常可以增加模型的複雜度和擬合能力。
Wandb 的配置:
新程式碼使用了 Weights and Biases(Wandb)來跟踪實驗,並允許您通過 config 對象來更容易地修改參數(例如優化器和隱藏層的節點數)。
使用了 Dropout 層的導入:
雖然這個層在程式碼中被導入了,但實際上並沒有被添加到模型中。
Dropout 是一種正則化技術,可以用於防止過擬合。
數據正規化
# 導入所需的函式庫和模組
import numpy as np
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Flatten, Dropout
# from keras.utils import np_utils
from tensorflow.keras import utils
from keras.callbacks import Callback
import json
from wandb.keras import WandbCallback
import wandb
# 初始化 Weights and Biases(Wandb)以追踪模型性能
run = wandb.init()
config = run.config
config.optimizer = "adam"
config.epochs = 10
config.hidden_nodes = 100
# 從 MNIST 數據集載入數據
(X_train, y_train), (X_test, y_test) = mnist.load_data()
img_width = X_train.shape[1]
img_height = X_train.shape[2]
# 將數據轉換為浮點數並進行正規化(將像素值縮放到 0 和 1 之間)
X_train = X_train.astype('float32')
X_train /= 255.
X_test = X_test.astype('float32')
X_test /= 255.
# 對目標(標籤)進行 one-hot 編碼
y_train = utils.to_categorical(y_train)
y_test = utils.to_categorical(y_test)
labels = range(10)
num_classes = y_train.shape[1]
# 建立 Sequential 模型
model = Sequential()
# 添加 Flatten 層以將 28x28 的圖片轉換為 784 維的向量
model.add(Flatten(input_shape=(img_width, img_height)))
# 添加一個全連接層(Dense layer)作為隱藏層,含有 100 個節點和 ReLU 激活函數
model.add(Dense(config.hidden_nodes, activation='relu'))
# 添加輸出層,含有 10 個節點(對應 10 個類別)和 Softmax 激活函數
model.add(Dense(num_classes, activation='softmax'))
# 編譯模型,設定損失函數、優化器和評估指標
model.compile(loss='categorical_crossentropy', optimizer=config.optimizer,
metrics=['accuracy'])
# 輸出模型的結構摘要
model.summary()
# 訓練模型,並使用 WandbCallback 來監控訓練過程
model.fit(X_train, y_train, validation_data=(X_test, y_test),
epochs=config.epochs,
callbacks=[WandbCallback(data_type="image", labels=labels)])
這段代碼主要是在進行一些基本的數據可視化和使用邏輯迴歸作為一個基礎分類器。這個分類器被用來對一個簡單的二維數據集進行分類。
這個數據集有兩個類別,每個類別的數據點都大致圍繞著一個中心點。
大致流程如下:
*** 初始化和數據生成***
基線模型(邏輯迴歸)
神經網絡設置
定義 buildmodel 函數,該函數使用梯度下降來訓練神經網絡。
可視化和比較
這個程式碼首先使用邏輯迴歸作為基線模型,然後訓練一個簡單的神經網絡來解決相同的分類問題。
最後,它通過繪製決策邊界來可視化模型的性能。
# 導入所需的函式庫和模組
import matplotlib.pyplot as plt
import numpy as np
import sklearn
import sklearn.datasets
import sklearn.linear_model
import matplotlib
# 設定 matplotlib 以嵌入模式顯示圖表,並設定默認圖表大小
%matplotlib inline
matplotlib.rcParams['figure.figsize'] = (10.0, 8.0)
# 設定隨機種子以確保結果可重現
np.random.seed(3)
# 使用 sklearn 的 make_moons 函數生成一個簡單的月亮形數據集
X, y = sklearn.datasets.make_moons(200, noise=0.20)
# 繪製數據集
plt.scatter(X[:,0], X[:,1], s=40, c=y, cmap=plt.cm.Spectral)
# 使用 sklearn 的 LogisticRegressionCV 類來訓練一個邏輯迴歸分類器
clf = sklearn.linear_model.LogisticRegressionCV()
clf.fit(X, y)
# 定義一個輔助函數來繪製決策邊界
def plot_decision_boundary(pred_func):
# 設定 x 和 y 的最小值和最大值並給它們一些邊距
x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
h = 0.01
# 生成一個點網格,其中每個點的距離是 h
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
# 使用模型預測整個網格的類別標籤
Z = pred_func(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 繪製等高線圖和散點圖
plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Spectral)
# 繪製邏輯迴歸分類器的決策邊界
plot_decision_boundary(lambda x: clf.predict(x))
plt.title("Logistic Regression")
# 設定模型和數據集的參數
num_examples = len(X) # 數據集大小
nn_input_dim = 2 # 輸入層維度
nn_output_dim = 2 # 輸出層維度
# 設定梯度下降的參數
epsilon = 0.01 # 學習率
reg_lambda = 0.01 # 正則化強度
# 定義一個函數來計算模型的總損失
def calculate_loss(model):
W1, b1, W2, b2 = model['W1'], model['b1'], model['W2'], model['b2'] # 從模型字典中提取出各層的權重和偏差
# 前向傳播以計算預測結果 :前向傳播的第一層:線性變換和激活函數
z1 = X.dot(W1) + b1 # 線性部分(Wx + b)
a1 = np.tanh(z1) # 激活函數:tan函數
# 前向傳播的第二層:線性變換
z2 = a1.dot(W2) + b2
# 計算每個類別的"未歸一化"概率(指數得分)
exp_scores = np.exp(z2)
# 歸一化概率,使其和為1
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
# 計算對數概率的負值,並提取實際類標籤對應的對數概率
corect_logprobs = -np.log(probs[range(num_examples), y])
# 總和所有樣本的對數概率,得到總損失
data_loss = np.sum(corect_logprobs)
# 加入正則化項(可選),這有助於防止過度擬合
data_loss += reg_lambda/2 * (np.sum(np.square(W1)) + np.sum(np.square(W2)))
# 回傳平均損失
return 1./num_examples * data_loss
# 定義一個輔助函數來預測輸出(0或1)
def predict(model, x):
# 從模型字典中提取各層的權重和偏差
W1, b1, W2, b2 = model['W1'], model['b1'], model['W2'], model['b2']
# Forward propagation
# 前向傳播的第一層:線性變換和激活函數
z1 = x.dot(W1) + b1 # 線性部分(Wx + b)
a1 = np.tanh(z1) # 激活函數:雙曲正切函數
# 前向傳播的第二層:線性變換
z2 = a1.dot(W2) + b2
# 計算每個類別的"未歸一化"概率(指數得分)
exp_scores = np.exp(z2)
# 歸一化概率,使其和為1
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
# 取概率最大的類別作為預測結果
return np.argmax(probs, axis=1)
# 該函數學習神經網絡的參數並返傳到模型。
# - nn_hdim: 隱藏層的節點數量
# - num_passes: 梯度下降訓練數據的遍歷次數
# - print_loss: 如果為 True,則每 1000 次迭代打印損失
# 定義建立模型的函數
'''
模型建立的主要流程如下:
1. 初始化神經網絡的權重和偏差。
2. 使用梯度下降算法進行多次迭代以訓練模型。
3. 在每次迭代中,它都會進行前向傳播以計算預測和損失。
4. 然後進行反向傳播以計算梯度。
5. 更新模型參數。
6. 選擇性地打印出損失以監控訓練過程。
'''
def build_model(nn_hdim, num_passes=20000, print_loss=False):
# 初始化隨機權重和偏差
np.random.seed(0)
W1 = np.random.randn(nn_input_dim, nn_hdim) / np.sqrt(nn_input_dim)
b1 = np.zeros((1, nn_hdim))
W2 = np.random.randn(nn_hdim, nn_output_dim) / np.sqrt(nn_hdim)
b2 = np.zeros((1, nn_output_dim))
# 初始化模型字典來保存參數
model = {}
# 使用梯度下降進行模型訓練
for i in range(0, num_passes):
# 前向傳播
z1 = X.dot(W1) + b1 # 這一行計算隱藏層的輸入。X.dot(W1) 是輸入資料和第一層權重的點積,+ b1 添加了偏差項。
a1 = np.tanh(z1) # 在這裡,我們對 z1 應用啟動函數(這裡是雙曲正切函數)來得到隱藏層的輸出。
z2 = a1.dot(W2) + b2 # 這一行計算輸出層的輸入。它是隱藏層輸出 a1 和第二層權重 W2 的點積,再加上偏差 b2。
exp_scores = np.exp(z2) #這一行計算softmax函數的指數部分。它對每個輸出層輸入應用指數函數。
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True) #這裡計算了最終的機率(或者說,softmax輸出)。每個指數得分除以所有得分的和。
# 反向傳播
delta3 = probs # 這一行初始化輸出層的梯度為輸出層的輸出(即機率)。
delta3[range(num_examples), y] -= 1 # 這一行從正確類別的梯度中減去 1,這是計算交叉熵損失梯度的一部分。
dW2 = (a1.T).dot(delta3) # 這一行計算了對 W2 的梯度。它是隱藏層輸出(a1 的轉置)和輸出層梯度(delta3)的點積。
db2 = np.sum(delta3, axis=0, keepdims=True) # 這一行計算了對 b2 的梯度,它是輸出層梯度(delta3)的和。
delta2 = delta3.dot(W2.T) * (1 - np.power(a1, 2)) # 這一行計算了隱藏層的梯度。它是輸出層梯度(delta3)和 W2 的點積,乘以隱藏層輸出(a1)的導數
dW1 = np.dot(X.T, delta2) # 這一行計算了對 W1 的梯度。它是輸入(X 的轉置)和隱藏層梯度(delta2)的點積。
db1 = np.sum(delta2, axis=0) # 這一行計算了對 b1 的梯度,它是隱藏層梯度(delta2)的和。
# # 添加正則化項(b1 和 b2 沒有正則化項)
dW2 += reg_lambda * W2
dW1 += reg_lambda * W1
# 更新權重和偏差
W1 += -epsilon * dW1
b1 += -epsilon * db1
W2 += -epsilon * dW2
b2 += -epsilon * db2
# 將新的參數保存到模型中
model = { 'W1': W1, 'b1': b1, 'W2': W2, 'b2': b2}
# O選擇性地打印損失
# 這是很花時間的,因為它使用整個數據集,所以我們不想太頻繁地這樣做。
if print_loss and i % 1000 == 0:
print("Loss after iteration %i: %f" %(i, calculate_loss(model)))
return model
# 建立三維隱藏層的模型
model = build_model(3, print_loss=True)
# 函數來繪製決策邊界
plot_decision_boundary(lambda x: predict(model, x))
plt.title("Decision Boundary for hidden layer size 3")
# 不同隱藏層尺寸的比較
plt.figure(figsize=(16, 32))
# 定義一個列表,其中包含我們想要試驗的不同隱藏層尺寸。
hidden_layer_dimensions = [1, 2, 3, 4, 5, 20, 50]
# 對列表 hidden_layer_dimensions 進行迭代,每次迭代都會獲取一個不同的隱藏層尺寸(nn_hdim)。
for i, nn_hdim in enumerate(hidden_layer_dimensions):
plt.subplot(5, 2, i+1) # 在5x2的子圖格局中創建一個新的子圖。
plt.title('Hidden Layer size %d' % nn_hdim) # 為當前的子圖設置標題,顯示隱藏層的大小。
model = build_model(nn_hdim) # 使用當前的 nn_hdim(隱藏層尺寸)來建立一個新的模型。
plot_decision_boundary(lambda x: predict(model, x)) # 繪製該模型的決策邊界。
plt.show()# 顯示所有子圖。
Loss after iteration 10000: 0.037463
Loss after iteration 11000: 0.037387
Loss after iteration 12000: 0.037334
Loss after iteration 13000: 0.037296
Loss after iteration 14000: 0.037269
Loss after iteration 15000: 0.037250
Loss after iteration 16000: 0.037236
Loss after iteration 17000: 0.037225
Loss after iteration 18000: 0.037218
Loss after iteration 19000: 0.037212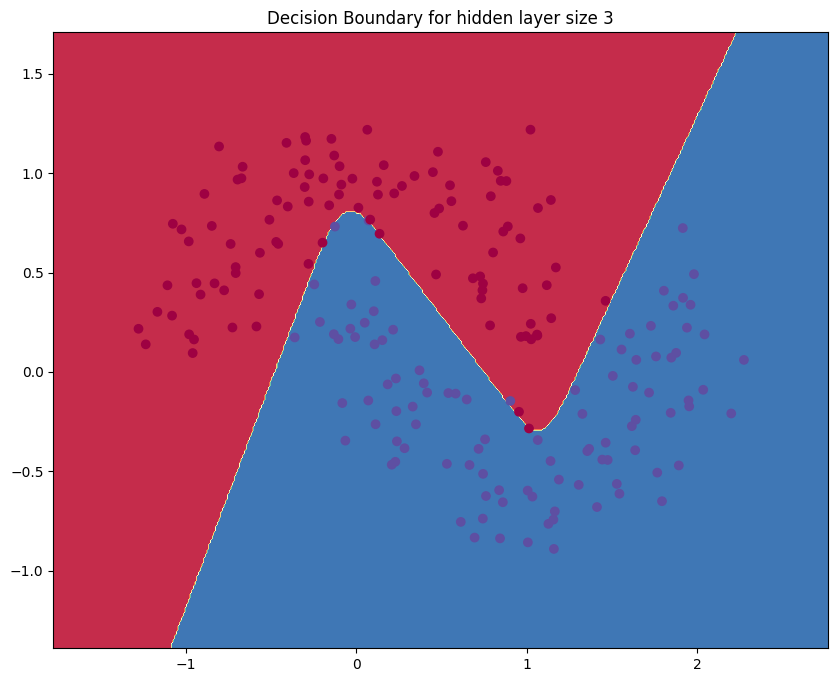


 iThome鐵人賽
iThome鐵人賽