嗨嗨!大家週日好!昨天提到傳統 Dev 與 Ops 會產生的矛盾與衝突,並將內容延伸到為了解決這個問題, Google 組建了 SRE 團隊,期望將技術能力結合手邊業務的文化帶入職場中。今天會接續來看這個方法是怎麼實踐的吧!這裡是今天讀的原文出處:Introduction,話不多說,我們開始囉!
一般來說,SRE團隊要承擔以下幾類職責:可用性改進,延遲優化,性能優化,效率優化,變更管理,監控,緊急事務處理以及容量規劃與管理。
上述每項都可以在後面好幾天一一展開來說,這裡就先不贅述,給大家參考一下 Google 認為 SRE 團隊的輪廓,在這個輪廓下,Google 制訂了一套完整的溝通準則和行事規範,好讓其他團隊在協作上能夠更順利(團隊其他成員的 OS:真的不知道維運團隊是在做些什麼呀!只覺得設立了一堆有的沒的規定好麻煩 OAO,又不知道標準在哪裡 QQ)
今天就從第一條核心方法論開始!
SRE 管理人員應該經常度量團隊成員的時間分配,如果有必要的話,採取一些暫時性措施將過多的維運壓力轉移回開發團隊處理。
Google 會確保 SRE 成員在維運跟開發的比例上呈現各半的情況,甚至將在生產環境中,發現的 Bug 轉交給開發的管理人員去分配,或與開發團隊一起執行 on-call 的任務。會這樣規定是因為要使維運這件事情走向一個正向循環,像是下面兩張流程圖:

傳統流程下,沒有技術能力介入的平台,遇到的每個 issue 都需要人工干預,就如同昨天提到,這樣的模式下,維運團隊規模會根據服務量的大小呈現線性相關。
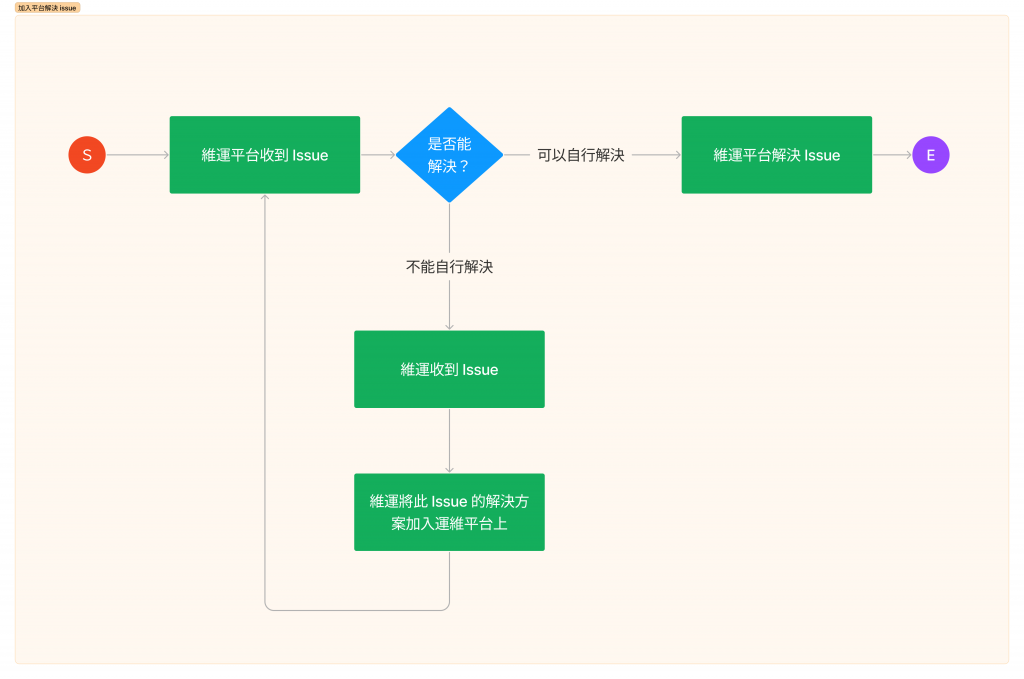
藉由維運團隊的技術能力,將部份 issue 自動化,或是將 Playbook 清楚地指派給應該修復的對象,便可以降低維運團隊壓力,也更有時間去處理那些尚未加入平台的 issue,或是處理緊急事件,讓系統能享有複利的果實。
SRE 處理維運工作的一項準則是:在每 8~12 小時的 on-call 輪值期間最多只處理兩個緊急事件。這個準則保證了 on-call 工程師有足夠的時間跟進緊急事件,這樣 SRE 可以正確地處理故障、恢復服務,並且要撰寫一份事後報告。
撰寫事故報告的優點有:
所有的產品事故都應該有對應的事後總結,無論有沒有觸發警報。這裡要注意的是,如果一個產品事故沒有觸發警報,那麼事後總結的意義可能更大:因為它將揭示監控系統中的漏洞。事後總結應該包括以下內容:事故發生、發現、解決的全過程,事故的根本原因,預防或者優化的解決方案。
關於事故報告書,本書也有提供一份範例!
先說結論,我認為具備程式語言能力一定是更好的。這並不是因為我本身是從工程師轉成 SRE 才這麼說,而是當團隊中沒有兩種視角具備的角色時,或是兩邊沒有磨合出「共通語言」時,就容易產生兩方人馬互不相讓的情況。
於是,經典的一句話就出現了!
為什麼我本地可以,上雲就不行!😤😤😤
開發認為維運團隊的基礎設施很不可靠,維運認為開發團隊沒有基本常識。在這種情況下,具備程式能力的 SRE 就可以很好地去排除問題,並且將事情的前因後果記錄下來,以避免類似情況在後續發生。
By the way, 開發也會在下次找你之前,把這些問題確認過一遍,真的解決不了,也排除他目前想到可能是開發產生的狀況之後,才會來找你。(我覺得這樣就足夠了 QAQ
P.S. 如果你的團隊成員都具備跨團隊的視野時,同時也具備足夠的軟實力時,那你真的好幸運,遇到神仙團隊 QQQ,希望有天我也能在這種環境裡學習 ><
原本以為到目前為止為期半年多的旅程沒什麼能紀錄的,但愈寫愈上手,沒想到假日就在寫文章跟柏德之門 3 之間速速流逝拉 OAO,好拉!明天第二條見!

