這是我在網路上找到的一個蠻有趣的Blog,是一個在Open AI工作的工程師的貼文,感覺整個是把類似 Lagchain 這樣的套件運用到一個神乎其技的方法跟指引。
LLM 加上記憶(算一種的Prompt),調API工具跟連接向量資料庫就大概是某種 AI Agent ,可能也可以用類似RLHF或RLAIF這類的技術做個 MODEL 幫忙PLANING以及加強,感覺就蠻有前景的。
今天這篇算是不務正業的一篇就是了。
英文夠強的可以看這邊的原文:https://lilianweng.github.io/posts/2023-06-23-agent/
大型語言模型(LLM)驅動的自主程式代理
這部分主要探討了使用大型語言模型(LLM)作為自主代理(如AutoGPT、GPT-Engineer和BabyAGI等)的核心控制器是一個令人興奮的概念。LLM不僅能生成優質的文本、故事、論文和程序,還可以作為一個強大的通用問題解決器。這意味著LLM有潛力成為一個全面的解決方案,不僅僅是文本生成。
這一部分描述了一個由LLM驅動的自主代理系統的基本組件,包括計劃、記憶和工具使用。其中,計劃包括子目標和分解、反思和改進;記憶則包括短期和長期記憶;工具使用則涉及調用外部API以獲取缺失的信息。
這部分深入探討了計劃作為自主代理系統的一個重要組件。它包括任務分解、自我反思等方面。任務分解可以通過LLM的簡單提示、任務特定的指令或人類輸入來完成。自我反思則允許代理通過改進過去的行為決策和糾正以前的錯誤來不斷改進。
這部分著重於記憶作為自主代理系統的另一個重要組件。它包括短期記憶和長期記憶。短期記憶主要用於模型的即時學習,而長期記憶則提供了代理在長時間內保留和回憶信息的能力。
這部分主要探討了代理如何學習調用外部API以獲取模型權重中缺失的額外信息。這包括當前信息、代碼執行能力、訪問專有信息來源等。
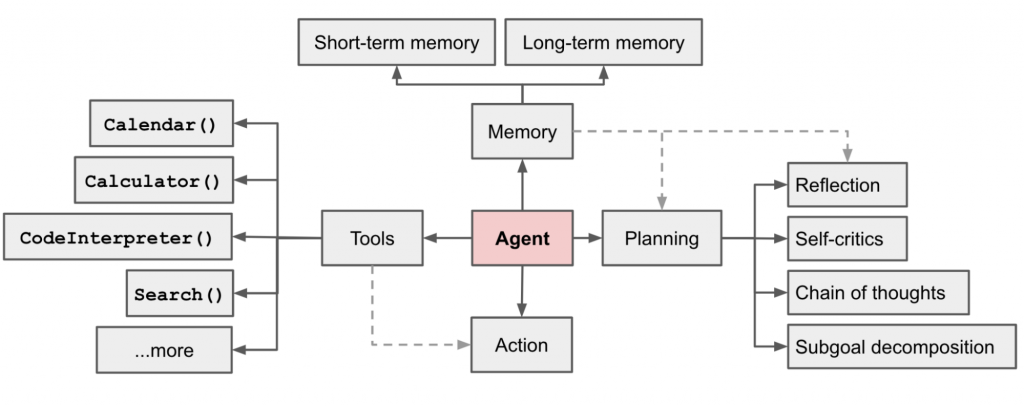
Fig. 1. Overview of a LLM-powered autonomous agent system.
計劃(Planning)是一個非常重要的組件。計劃涉及到多個方面,包括任務分解(Task Decomposition)和不同的計劃方法。
對於複雜的任務,一個有效的方法是將其分解成多個較小和更簡單的步驟。這裡提到了“思維鏈(Chain of thought (CoT; Wei et al. 2022))”作為一種標準的提示技術,它能夠提高模型在複雜任務上的性能。具體來說,模型會被指示“逐步思考”,以利用更多的測試時間來分解困難任務。這種方法不僅將大任務轉化為多個可管理的小任務,還為模型的思維過程提供了解釋。
另一個擴展是“思維樹(Tree of Thoughts (Yao et al. 2023))”,它在每一步探索多種推理可能性。這種方法首先將問題分解成多個思維步驟,然後在每一步生成多個思維,形成一個樹狀結構。搜索過程可以是廣度優先搜索(BFS)或深度優先搜索(DFS),每個狀態都由一個分類器(通過提示 prompt )或多數票來評估。
任務分解(Task Decomposition)可以通過以下三種方式來完成:
這三種方式提供了不同的途徑來進行任務分解,從而使大型語言模型能夠更有效地處理複雜的問題或任務。
除了上述的任務分解方法,還有一種完全不同的方法,即 LLM+P (Liu et al. 2023)。這種方法依賴於一個外部的經典規劃器來進行長期規劃。具體來說,這個方法使用規劃領域定義語言(Planning Domain Definition Language,簡稱PDDL)作為一個中介接口來描述規劃問題。
在這個過程中,大型語言模型(LLM)首先將問題翻譯成“問題PDDL”,然後請求一個經典規劃器基於現有的“領域PDDL”生成一個PDDL計劃,最後將這個PDDL計劃翻譯回自然語言。
本質上,這個規劃步驟是被外包給一個外部工具,這需要領域特定的PDDL和一個適當的規劃器,這在某些機器設置中是常見的,但在許多其他領域則不是。
總之,計劃在自主代理系統中是一個關鍵組件,它涉及到多種方法和技術,包括任務分解和不同類型的計劃方法。這些方法和技術為自主代理在處理複雜任務時提供了多種選項和靈活性。
自我反思(Self-Reflection)作為一個重要方面,它允許自主代理通過改進過去的行為決策和糾正以前的錯誤來不斷進步。這在現實世界的任務中起著至關重要的作用,因為試錯(trial and error)在這些任務中是不可避免的。
ReAct(由Yao等人於2023年提出)將推理和行動整合到大型語言模型(LLM)中,通過擴展行動空間來實現這一點。這個行動空間是任務特定的離散行動和語言空間的組合。前者使LLM能夠與環境互動(例如,使用維基百科搜索API),而後者則提示LLM用自然語言生成推理跡象。
ReAct的提示模板包含了讓LLM進行思考的明確步驟,大致的格式如下:
Thought: ...
Action: ...
Observation: ...
... (Repeated many times)
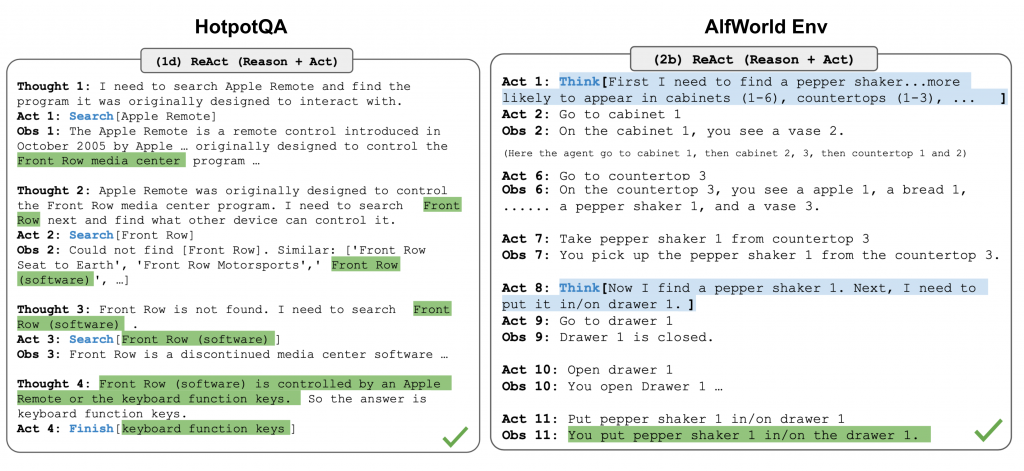
Fig. 2. Examples of reasoning trajectories for knowledge-intensive tasks (e.g. HotpotQA, FEVER) and decision-making tasks (e.g. AlfWorld Env, WebShop). (Image source: Yao et al. 2023).
在知識密集型任務和決策型任務的實驗中,ReAct的表現優於僅有行動(Act-only)的基線模型,其中刪除了“Thought: …”這一步。
Reflexion(由Shinn和Labash於2023年提出)是一個框架,旨在為代理裝備動態記憶和自我反思的能力,以提高推理技巧。Reflexion具有標準的強化學習(RL)設置,其中獎勵模型提供了一個簡單的二進制獎勵,而行動空間則遵循ReAct中的設置,即任務特定的行動空間會與語言相結合,以實現複雜的推理步驟。在每個行動a 後,代理h會計算一個啟發式指標,並根據自我反思的結果有選擇性地決定是否重置環境以開始新的試驗。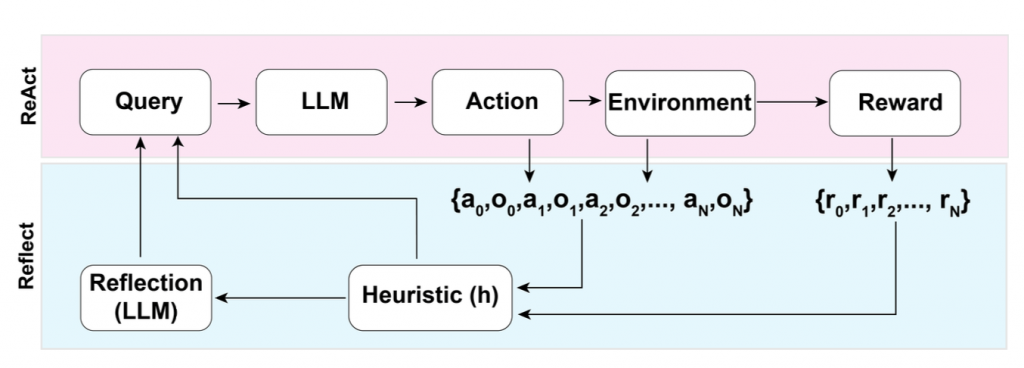
Fig. 3. Illustration of the Reflexion framework. (Image source: Shinn & Labash, 2023)
啟發式函數(heuristic function)的作用,它用於判斷軌跡(trajectory)是否低效或包含幻覺,並應當被停止。低效規劃指的是花費過長時間卻未能成功的軌跡。幻覺則被定義為遇到一系列連續相同的行動,這些行動在環境中導致相同的觀察結果。
自我反思是通過向大型語言模型(LLM)展示兩個示例來創建的,每個示例都是一對(失敗的軌跡,用於指導未來計劃變更的理想反思)。然後,這些反思被添加到代理的工作記憶中,最多三個,以用作查詢LLM的上下文。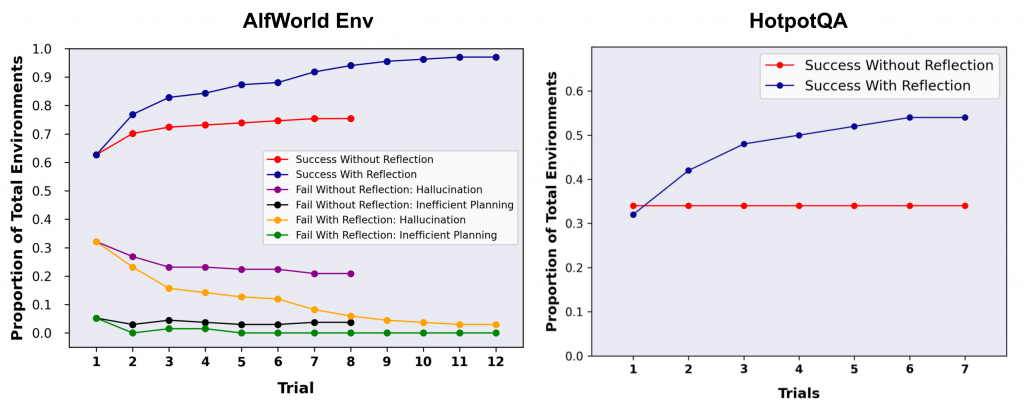
Fig. 4. Experiments on AlfWorld Env and HotpotQA. Hallucination is a more common failure than inefficient planning in AlfWorld. (Image source: Shinn & Labash, 2023)
「回顧鏈(Chain of Hindsight,簡稱CoH)」的方法,由Liu等人於2023年提出。這種方法鼓勵模型通過明確地向其展示一系列過去的輸出(每個輸出都帶有反饋)來改進自己的輸出。人類反饋數據是一個集合,其中包括提示、模型完成、人類對模型完成的評分,以及相應的人類提供的回顧反饋。假設這些反饋元組按照獎勵進行排序。
這個過程是一種監督式微調,其中數據是一個序列,模型被微調以僅預測基於序列前綴的輸出,這樣模型就可以根據反饋序列進行自我反思,以產生更好的輸出。在測試時,模型還可以選擇性地接收人類註釋者提供的多輪指令。
為了避免過擬合,CoH添加了一個正則化項,以最大化預訓練數據集的對數似然。為了避免使用捷徑和複製(因為反饋序列中有許多常用詞),他們在訓練過程中隨機遮蔽了0% - 5%的過去標記。
他們實驗中使用的訓練數據集是WebGPT比較、來自人類反饋的摘要和人類偏好數據集的組合。
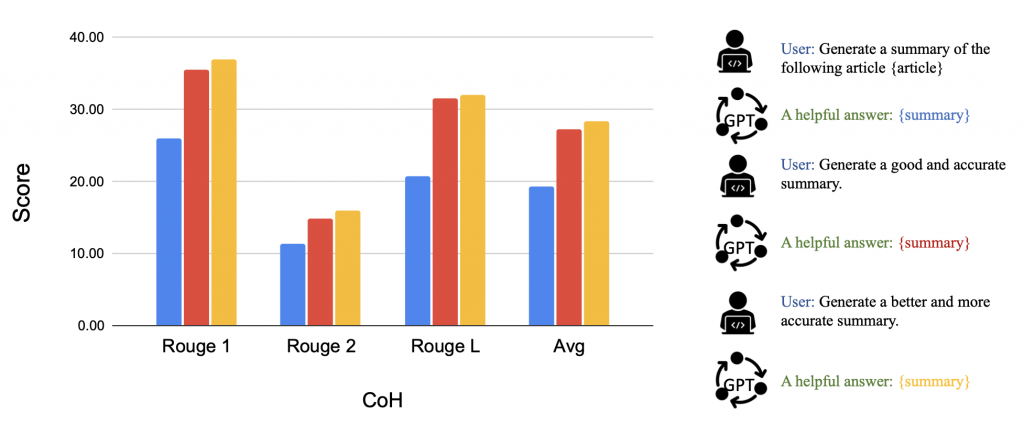
Fig. 5. After fine-tuning with CoH, the model can follow instructions to produce outputs with incremental improvement in a sequence. (Image source: Liu et al. 2023)
「回顧鏈(Chain of Hindsight,簡稱CoH)」的概念,其目的是在上下文中呈現一系列逐步改進的輸出,並訓練模型沿著這一趨勢產生更好的輸出。算法蒸餾(Algorithm Distillation,簡稱AD,由Laskin等人於2023年提出)將相同的概念應用於強化學習任務中的跨情節(cross-episode)軌跡,其中一個算法被封裝在一個長期受條件限制的策略中。
考慮到一個代理會多次與環境互動,並且在每個情節中代理的表現都會略有改善,AD將這一學習歷史連接起來並輸入到模型中。因此,我們應該期望下一個預測的行動會比以前的試驗表現得更好。目標是學習強化學習的過程,而不是訓練特定任務的策略本身。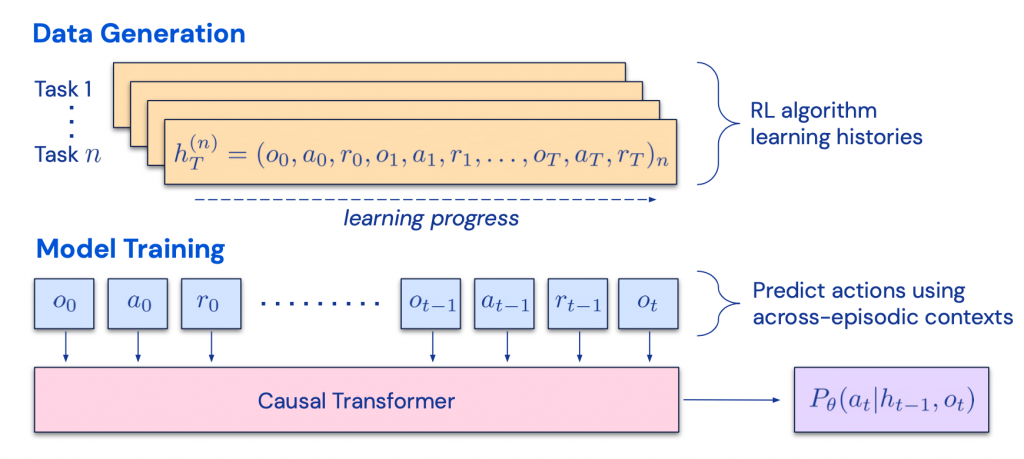
Fig. 6. Illustration of how Algorithm Distillation (AD) works.
(Image source: Laskin et al. 2023).
這篇論文假設任何生成一組學習歷史的算法都可以通過對行為進行克隆(behavioral cloning)來蒸餾成一個神經網絡。這些歷史數據是由一組針對特定任務訓練的源策略(source policies)生成的。在訓練階段,每次進行強化學習(RL)運行時,會隨機抽取一個任務,並使用多情節(multi-episode)歷史的一個子序列進行訓練,從而學習到的策略是任務不可知的(task-agnostic)。
實際上,模型有限的上下文窗口長度(可以理解為記憶或視野有限),因此情節(episodes)應該足夠短,以便構建多情節歷史。需要2-4個情節的多情節上下文,以學習近乎最優的在上下文中的強化學習(in-context RL)算法。在上下文中的強化學習的出現需要足夠長的上下文。
與三個基線(包括ED(專家蒸餾,即使用專家軌跡而非學習歷史進行行為克隆)、源策略(用於由UCB生成蒸餾軌跡)和RL^2(由Duan等人於2017年提出;用作上界,因為它需要在線強化學習))相比,AD在僅使用離線強化學習的情況下展示了與RL^2接近的在上下文中的強化學習性能,並比其他基線學習得更快。當基於源策略的部分訓練歷史進行條件化時,AD也比ED基線改進得更快。
Fig. 7. Comparison of AD, ED, source policy and RL^2 on environments that require memory and exploration. Only binary reward is assigned. The source policies are trained with A3C for "dark" environments and DQN for watermaze.
(Image source: Laskin et al. 2023)
(結果原文也有用Chatgpt 呵呵)
(特別感謝ChatGPT幫助我草擬這一部分。通過與ChatGPT的對話,我對人類大腦和用於快速MIPS的數據結構有了很多了解。)
記憶可以被定義為用於獲取、儲存、保留和稍後檢索信息的過程。人類大腦中有幾種不同類型的記憶。
感官記憶:這是記憶的最早階段,提供了在原始刺激結束後保留感官信息(視覺、聽覺等)的能力。感官記憶通常只持續幾秒鐘。子類別包括象形記憶(視覺)、迴聲記憶(聽覺)和觸覺記憶(觸摸)。
短期記憶(STM)或工作記憶:它儲存我們當前意識到的信息,並需要用於執行複雜的認知任務,如學習和推理。據信短期記憶的容量大約有7個東西(Miller 1956年提出)並持續20-30秒。
長期記憶(LTM):長期記憶可以儲存信息極長的時間,範圍從幾天到幾十年,儲存容量基本上是無限的。LTM有兩個子類型:

Fig. 8. Categorization of human memory.
我們大致可以考慮以下的對應關係:
外部記憶可以減輕有限注意力跨度的限制。一個標準的做法是將信息的嵌入表示保存到一個可以支持快速最大內積搜索(MIPS)的向量存儲數據庫中。為了優化檢索速度,常見的選擇是使用近似最近鄰(Approximate Nearest Neighbors,簡稱ANN)算法,以返回大約排名前k的最近鄰,從而用少量的精度損失換取巨大的速度提升。
一些常用的用於快速MIPS的ANN算法選擇:
LSH(Locality-Sensitive Hashing 局部敏感哈希):它引入了一個哈希函數,使得相似的輸入項以高概率映射到相同的桶(bucket)中,其中桶的數量遠小於輸入的數量。
ANNOY(近似最近鄰):核心數據結構是隨機投影樹,一組二叉樹,其中每個非葉節點代表一個將輸入空間一分為二的超平面,每個葉節點存儲一個數據點。樹是獨立並隨機建立的,因此在某種程度上,它模仿了一個哈希函數。ANNOY搜索會在所有樹中進行,以迭代地搜索與查詢最接近的一半,然後匯總結果。這個想法與KD樹相關,但更具可擴展性。
HNSW(分層可導航小世界):它受到小世界網絡的概念啟發,其中大多數節點可以在少數幾步內由任何其他節點到達;例如,社交網絡的“六度分隔”特性。HNSW建立這些小世界圖的分層層次,其中底層包含實際的數據點。中間的層創建了快捷方式以加速搜索。進行搜索時,HNSW從頂層的一個隨機節點開始,並導航到目標。當它不能再靠近時,它會下移到下一層,直到到達底層。上層中的每一步都可能在數據空間中覆蓋大的距離,而下層中的每一步都會提高搜索質量。
FAISS(Facebook AI相似性搜索):它基於一個假設,即在高維空間中,節點之間的距離遵循高斯分佈,因此應該存在數據點的聚類。FAISS通過將向量空間劃分為簇來應用向量量化,然後在簇內進一步精煉量化。搜索首先查找具有粗量化的簇候選者,然後進一步查看每個簇的更細的量化。
ScaNN(可擴展最近鄰):ScaNN的主要創新是各向異性向量量化。它將一個數據點 $x$ 量化為 $y$,使得內積 $ x⋅y $ 與 $x$ 的原始距離盡可能相似,而不是選擇最接近的量化中心點。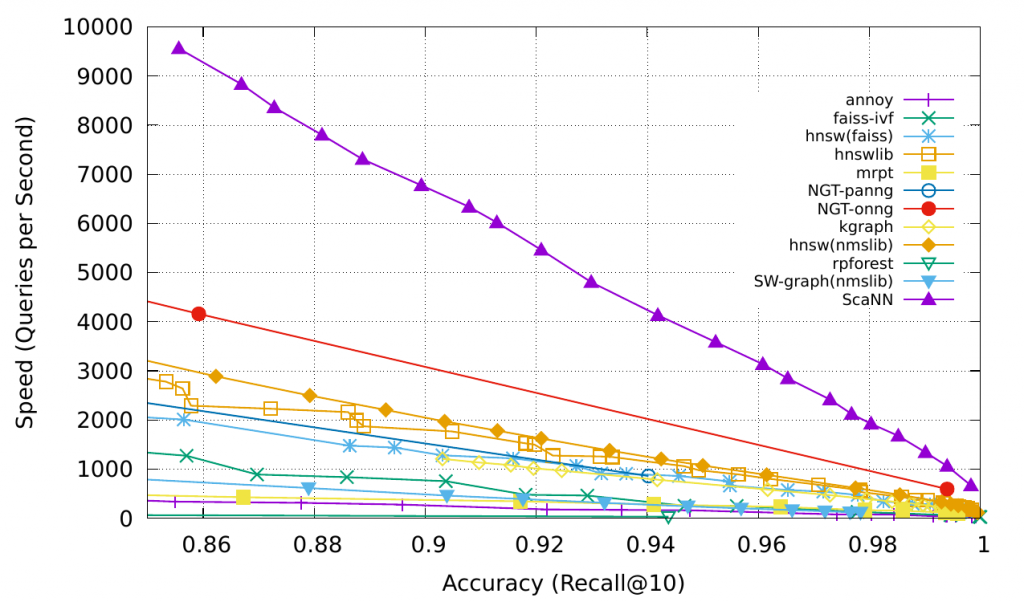
Fig. 9. Comparison of MIPS algorithms, measured in recall@10. (Image source: Google Blog, 2020)
Check more MIPS algorithms and performance comparison in ann-benchmarks.com.
工具使用是人類的一個顯著特徵。我們創造、修改和利用外部對象來完成超出我們身體和認知極限的事情。為大型語言模型(LLMs)配備外部工具可以顯著擴展模型的能力。

Fig. 10. A picture of a sea otter using rock to crack open a seashell, while floating in the water. While some other animals can use tools, the complexity is not comparable with humans. (Image source: Animals using tools)
MRKL(Karpas等人,2022年),縮寫為“模塊化推理、知識和語言”,是一種用於自主代理的神經符號架構。MRKL系統包含一系列的“專家”模塊,而通用型的LLM作為路由器,將查詢路由到最合適的專家模塊。這些模塊可以是神經的(例如深度學習模型)或符號的(例如數學計算器、貨幣轉換器、天氣API)。
他們進行了一個實驗,對LLM進行微調,以調用計算器,並使用算術作為測試案例。他們的實驗顯示,解決口頭數學問題比解決明確陳述的數學問題更困難,因為LLMs(7B Jurassic1-large模型)未能可靠地理解基本算術的正確參數。結果突顯出,當外部符號工具可以可靠地工作時,知道何時以及如何使用這些工具是至關重要的,這由LLM的能力決定。
TALM(工具增強語言模型;Parisi等人,2022年)和Toolformer(Schick等人,2023年)都對LM進行了微調,學會使用外部工具API。根據新添加的API調用註釋可以提高模型輸出的質量來擴展數據集。更多詳細信息可於Prompt Engineering的“外部APIs查看。
ChatGPT插件和OpenAI API函數調用是LLM在實踐中增強工具使用能力的好例子。工具API的集合可以由其他開發者提供(如在插件中)或自定義(如在函數調用中)。
HuggingGPT(Shen等人,2023年)是一個框架,使用ChatGPT作為任務計劃器,根據模型描述選擇HuggingFace平台上可用的模型,並根據執行結果對響應進行摘要。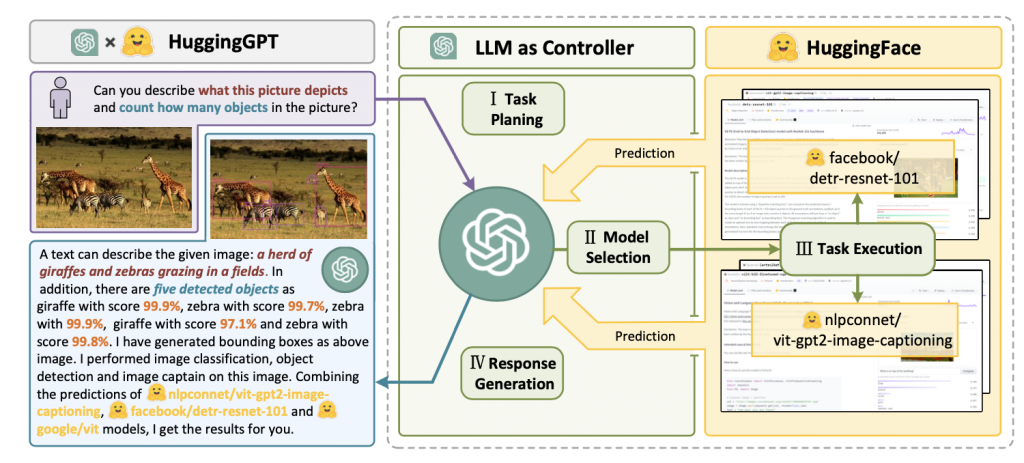
Fig. 11. Illustration of how HuggingGPT works. (Image source: Shen et al. 2023)
該系統由4個階段組成:
(1)任務規劃:LLM(大型語言模型)作為大腦,將用戶請求解析為多個任務。每個任務有四個相關的屬性:任務類型、ID、依賴性和參數。他們使用少量的示例來引導LLM進行任務解析和規劃。
指令:
The AI assistant can parse user input to several tasks: [{"task": task, "id", task_id, "dep": dependency_task_ids, "args": {"text": text, "image": URL, "audio": URL, "video": URL}}]. The "dep" field denotes the id of the previous task which generates a new resource that the current task relies on. A special tag "-task_id" refers to the generated text image, audio and video in the dependency task with id as task_id. The task MUST be selected from the following options: {{ Available Task List }}. There is a logical relationship between tasks, please note their order. If the user input can't be parsed, you need to reply empty JSON. Here are several cases for your reference: {{ Demonstrations }}. The chat history is recorded as {{ Chat History }}. From this chat history, you can find the path of the user-mentioned resources for your task planning.
(2)模型選擇:LLM將任務分發給專家模型,其中請求被框定為一個多選題。LLM會看到一個可供選擇的模型列表。由於上下文長度有限,需要基於任務類型進行過濾。
指令:
Given the user request and the call command, the AI assistant helps the user to select a suitable model from a list of models to process the user request. The AI assistant merely outputs the model id of the most appropriate model. The output must be in a strict JSON format: "id": "id", "reason": "your detail reason for the choice". We have a list of models for you to choose from {{ Candidate Models }}. Please select one model from the list.
(3)任務執行:專家模型對特定任務進行執行並記錄結果。
指令:
With the input and the inference results, the AI assistant needs to describe the process and results. The previous stages can be formed as - User Input: {{ User Input }}, Task Planning: {{ Tasks }}, Model Selection: {{ Model Assignment }}, Task Execution: {{ Predictions }}. You must first answer the user's request in a straightforward manner. Then describe the task process and show your analysis and model inference results to the user in the first person. If inference results contain a file path, must tell the user the complete file path.
(4)回應生成:LLM接收執行結果並向用戶提供總結的結果。
要將HuggingGPT投入實際使用,需要解決幾個挑戰:(1)由於LLM推理輪次和與其他模型的交互都會拖慢過程,因此需要提高效率;(2)它依賴於長上下文窗口來傳遞複雜的任務內容;(3)需要提高LLM輸出和外部模型服務的穩定性。
API-Bank(Li等人,2023年)是一個用於評估工具增強LLM性能的基準。它包含53個常用的API工具,一個完整的工具增強LLM工作流程,以及涉及568個API調用的264個註釋對話。API的選擇相當多樣,包括搜索引擎、計算器、日曆查詢、智能家居控制、日程管理、健康數據管理、帳戶認證工作流程等。由於有大量的API,LLM首先可以訪問API搜索引擎以找到合適的API進行調用,然後使用相應的文檔進行調用。

Fig. 12. Pseudo code of how LLM makes an API call in API-Bank. (Image source: Li et al. 2023)
在API-Bank工作流程中,LLMs需要做出幾個決定,我們可以在每一步評估該決定的準確性。決定包括:
這個基準測試評估代理的工具使用能力有三個層次:
ChemCrow(Bran等人,2023年)是一個特定領域中的例子,其中被13個專家設計的工具增強的LLM(大型語言模型)被用於完成有機合成、藥物發現和材料設計等任務。該工作流程是在LangChain中實現,也應用了之前在ReAct和MRKLs中描述的內容,並將CoT(Chain of Thought)推理與與任務相關的工具相結合:
Thought, Action, Action Input, Observation。一個有趣的觀察是,儘管基於LLM的評估得出GPT-4和ChemCrow的表現幾乎相當,專家針對解決方案的完成度和化學正確性進行的人工評估表明,ChemCrow 的性能大幅優於 GPT-4。這表明使用LLM來評估其自身在需要深厚專業知識的領域的表現存在潛在問題。 專業知識的缺乏可能會導致LLM不知道其缺陷,從而無法很好地判斷任務結果的正確性。
Boiko等人(2023年)也研究了用於科學發現的LLM(大型語言模型)驅動的代理程式,以處理自主設計、規劃和執行複雜的科學實驗。這個代理可以使用工具來瀏覽互聯網、閱讀文檔、執行代碼、調用機器人實驗API和使用其他LLM。
例如,當被要求develop a novel anticancer drug“開發一種新型抗癌藥物”時,該模型提出了以下推理步驟:
他們還討論了風險,尤其是與非法藥物和生物武器有關的風險。他們開發了一個包含已知化學武器劑的清單的測試集,並要求代理合成它們。11個請求中有4個(36%)被接受以獲得合成解決方案,代理嘗試查閱文檔以執行該程序。11個中有7個被拒絕,其中5個是在網絡搜索後被拒絕的,而2個是僅基於提示被拒絕的。
生成代理(Generative Agents,Park等人,2023年)是一個非常有趣的實驗,其中有25個虛擬角色,每個角色都由一個由LLM(大型語言模型)驅動的代理控制,他們在一個受到《模擬人生》(The Sims)啟發的沙盒環境中生活和互動。生成代理為交互式應用創造了可信的人類行為模擬。
生成代理的設計將LLM與記憶、規劃和反思機制相結合,使代理能夠根據過去的經驗進行行為調節,以及與其他代理進行互動。
{Intro of an agent X}. Here is X's plan today in broad strokes: 1)
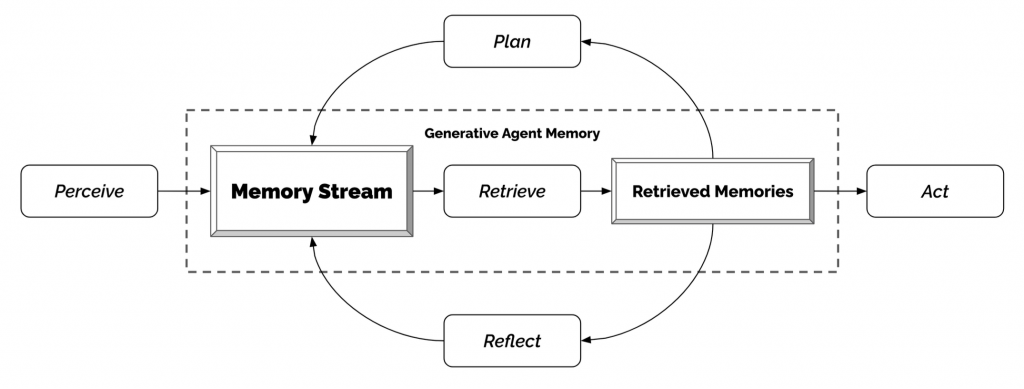
這個有趣的模擬結果產生了突現的社會行為,例如信息擴散、關係記憶(例如,兩個代理繼續對話主題)以及社會活動的協調(例如,舉辦一個派對並邀請許多其他人)。
AutoGPT 已經引起了大量關注,探討了使用大型語言模型(LLM)作為主控制器來設置自主代理的可能性。儘管自然語言界面存在相當多的可靠性問題,但它仍然是一個很酷的概念驗證演示。AutoGPT 中有很多代碼是關於格式解析的。
這是 AutoGPT 使用的系統消息,其中 {{...}} 是用戶輸入:
You are {{ai-name}}, {{user-provided AI bot description}}.
Your decisions must always be made independently without seeking user assistance. Play to your strengths as an LLM and pursue simple strategies with no legal complications.
GOALS:
1. {{user-provided goal 1}}
2. {{user-provided goal 2}}
3. ...
4. ...
5. ...
Constraints:
1. ~4000 word limit for short term memory. Your short term memory is short, so immediately save important information to files.
2. If you are unsure how you previously did something or want to recall past events, thinking about similar events will help you remember.
3. No user assistance
4. Exclusively use the commands listed in double quotes e.g. "command name"
5. Use subprocesses for commands that will not terminate within a few minutes
Commands:
1. Google Search: "google", args: "input": "<search>"
2. Browse Website: "browse_website", args: "url": "<url>", "question": "<what_you_want_to_find_on_website>"
3. Start GPT Agent: "start_agent", args: "name": "<name>", "task": "<short_task_desc>", "prompt": "<prompt>"
4. Message GPT Agent: "message_agent", args: "key": "<key>", "message": "<message>"
5. List GPT Agents: "list_agents", args:
6. Delete GPT Agent: "delete_agent", args: "key": "<key>"
7. Clone Repository: "clone_repository", args: "repository_url": "<url>", "clone_path": "<directory>"
8. Write to file: "write_to_file", args: "file": "<file>", "text": "<text>"
9. Read file: "read_file", args: "file": "<file>"
10. Append to file: "append_to_file", args: "file": "<file>", "text": "<text>"
11. Delete file: "delete_file", args: "file": "<file>"
12. Search Files: "search_files", args: "directory": "<directory>"
13. Analyze Code: "analyze_code", args: "code": "<full_code_string>"
14. Get Improved Code: "improve_code", args: "suggestions": "<list_of_suggestions>", "code": "<full_code_string>"
15. Write Tests: "write_tests", args: "code": "<full_code_string>", "focus": "<list_of_focus_areas>"
16. Execute Python File: "execute_python_file", args: "file": "<file>"
17. Generate Image: "generate_image", args: "prompt": "<prompt>"
18. Send Tweet: "send_tweet", args: "text": "<text>"
19. Do Nothing: "do_nothing", args:
20. Task Complete (Shutdown): "task_complete", args: "reason": "<reason>"
Resources:
1. Internet access for searches and information gathering.
2. Long Term memory management.
3. GPT-3.5 powered Agents for delegation of simple tasks.
4. File output.
Performance Evaluation:
1. Continuously review and analyze your actions to ensure you are performing to the best of your abilities.
2. Constructively self-criticize your big-picture behavior constantly.
3. Reflect on past decisions and strategies to refine your approach.
4. Every command has a cost, so be smart and efficient. Aim to complete tasks in the least number of steps.
You should only respond in JSON format as described below
Response Format:
{
"thoughts": {
"text": "thought",
"reasoning": "reasoning",
"plan": "- short bulleted\n- list that conveys\n- long-term plan",
"criticism": "constructive self-criticism",
"speak": "thoughts summary to say to user"
},
"command": {
"name": "command name",
"args": {
"arg name": "value"
}
}
}
Ensure the response can be parsed by Python json.loads
GPT-Engineer 是另一個項目,用於根據自然語言指定的任務創建整個代碼存儲庫。 GPT 工程師被指示考慮要構建的較小組件列表,並要求用戶輸入以根據需要澄清問題。
以下是發送到 GPT-Engineer 使用的 OpenAI ChatCompletion 端點的用於說明任務的示例對話。 用戶輸入包含在 {{user input text}} 包裹。
[
{
"role": "system",
"content": "You will read instructions and not carry them out, only seek to clarify them.\nSpecifically you will first summarise a list of super short bullets of areas that need clarification.\nThen you will pick one clarifying question, and wait for an answer from the user.\n"
},
{
"role": "user",
"content": "We are writing {{a Super Mario game in python. MVC components split in separate files. Keyboard control.}}\n"
},
{
"role": "assistant",
"content": "Summary of areas that need clarification:\n1. Specifics of the Super Mario game (e.g. level design, characters, gameplay mechanics)\n2. Details about the MVC components (e.g. which components are in each file)\n3. Keyboard control implementation (e.g. which keys to use, how to handle input)\n\nClarifying question:\nCan you provide more details about the Super Mario game, such as level design, characters, and gameplay mechanics?"
},
{
"role": "user",
"content": "{{There are 10 levels in total. The main character is a plumber named Mario, who can walk and jump. It is a classical platform game just like Super Mario. The main character moves from left to right, trying to get to the destination, where there are many obstacles and attacks from enemies in the process.}}\n\nIs anything else unclear? If yes, only answer in the form:\n{remaining unclear areas} remaining questions.\n{Next question}\nIf everything is sufficiently clear, only answer \"Nothing more to clarify.\"."
},
{
"role": "assistant",
"content": "Remaining unclear areas: 2 remaining questions.\nCan you provide more information about how the MVC components are split into separate files?"
},
{
"role": "user",
"content": "{{Make your own assumptions and state them explicitly before starting}}"
}
]
然後,在這些澄清之後,代理轉成了帶有不同系統消息的代碼編寫模式。
系統消息:
You will get instructions for code to write. You will write a very long answer. Make sure that every detail of the architecture is, in the end, implemented as code. Make sure that every detail of the architecture is, in the end, implemented as code.
Think step by step and reason yourself to the right decisions to make sure we get it right. You will first lay out the names of the core classes, functions, methods that will be necessary, as well as a quick comment on their purpose.
Then you will output the content of each file including ALL code. Each file must strictly follow a markdown code block format, where the following tokens must be replaced such that FILENAME is the lowercase file name including the file extension, LANG is the markup code block language for the code’s language, and CODE is the code:
FILENAME
CODE
You will start with the “entrypoint” file, then go to the ones that are imported by that file, and so on. Please note that the code should be fully functional. No placeholders.
Follow a language and framework appropriate best practice file naming convention. Make sure that files contain all imports, types etc. Make sure that code in different files are compatible with each other. Ensure to implement all code, if you are unsure, write a plausible implementation. Include module dependency or package manager dependency definition file. Before you finish, double check that all parts of the architecture is present in the files.
Useful to know: You almost always put different classes in different files. For Python, you always create an appropriate requirements.txt file. For NodeJS, you always create an appropriate package.json file. You always add a comment briefly describing the purpose of the function definition. You try to add comments explaining very complex bits of logic. You always follow the best practices for the requested languages in terms of describing the code written as a defined package/project.
Python toolbelt preferences:
pytest
dataclasses
對話範例:
[
{
"role": "system",
"content": "You will get instructions for code to write.\nYou will write a very long answer. Make sure that every detail of the architecture is, in the end, implemented as code.\nMake sure that every detail of the architecture is, in the end, implemented as code.\n\nThink step by step and reason yourself to the right decisions to make sure we get it right.\nYou will first lay out the names of the core classes, functions, methods that will be necessary, as well as a quick comment on their purpose.\n\nThen you will output the content of each file including ALL code.\nEach file must strictly follow a markdown code block format, where the following tokens must be replaced such that\nFILENAME is the lowercase file name including the file extension,\nLANG is the markup code block language for the code's language, and CODE is the code:\n\nFILENAME\n```LANG\nCODE\n```\n\nYou will start with the \"entrypoint\" file, then go to the ones that are imported by that file, and so on.\nPlease note that the code should be fully functional. No placeholders.\n\nFollow a language and framework appropriate best practice file naming convention.\nMake sure that files contain all imports, types etc. Make sure that code in different files are compatible with each other.\nEnsure to implement all code, if you are unsure, write a plausible implementation.\nInclude module dependency or package manager dependency definition file.\nBefore you finish, double check that all parts of the architecture is present in the files.\n\nUseful to know:\nYou almost always put different classes in different files.\nFor Python, you always create an appropriate requirements.txt file.\nFor NodeJS, you always create an appropriate package.json file.\nYou always add a comment briefly describing the purpose of the function definition.\nYou try to add comments explaining very complex bits of logic.\nYou always follow the best practices for the requested languages in terms of describing the code written as a defined\npackage/project.\n\n\nPython toolbelt preferences:\n- pytest\n- dataclasses\n"
},
# … same conversation as earlier, ended with "Make your own assumptions and state them explicitly before starting".
{
"role": "assistant",
"content": "Assumptions:\n1. Model: The model will contain the game's data, such as level information, character states, and enemy positions.\n2. View: The view will handle the game's visuals, including rendering the game objects, backgrounds, and updating the display.\n3. Controller: The controller will manage user input, such as keyboard controls, and update the model accordingly.\n\nWith these assumptions in mind, is there any specific aspect of the keyboard control implementation you would like me to clarify?"
},
{
"role": "user",
"content": "Please now remember the steps:\n\nThink step by step and reason yourself to the right decisions to make sure we get it right.\nFirst lay out the names of the core classes, functions, methods that will be necessary, As well as a quick comment on their purpose.\n\nThen you will output the content of each file including ALL code.\nEach file must strictly follow a markdown code block format, where the following tokens must be replaced such that\nFILENAME is the lowercase file name including the file extension,\nLANG is the markup code block language for the code's language, and CODE is the code:\n\nFILENAME\n```LANG\nCODE\n```\n\nPlease note that the code should be fully functional. No placeholders.\n\nYou will start with the \"entrypoint\" file, then go to the ones that are imported by that file, and so on.\nFollow a language and framework appropriate best practice file naming convention.\nMake sure that files contain all imports, types etc. The code should be fully functional. Make sure that code in different files are compatible with each other.\nBefore you finish, double check that all parts of the architecture is present in the files.\n"
}
]
在了解了構建以 LLM 為中心的代理的關鍵想法和演示之後,我開始看到一些常見的限制:
上下文長度有限:上下文容量有限,限制了歷史信息、詳細說明、API 調用上下文和響應的引用。 系統的設計必須適應這種有限的通信帶寬,而從過去的錯誤中學習的自我反思等機制將從長或無限的上下文窗口中受益匪淺。 儘管向量存儲和檢索可以提供對更大知識庫的訪問,但它們的表示能力不如充分關注那麼強大。
長期規劃和任務分解的挑戰:長期規劃和有效探索解決方案空間仍然具有挑戰性。 LLMs 士在遇到意外錯誤時很難調整計劃,這使得它們與從試錯中學習的人相比不太穩健。
自然語言接口的可靠性:當前的代理系統依賴自然語言作為LLMs與外部組件(例如LLMs的記憶內存和工具)之間的接口。 然而,模型輸出的可靠性是令人懷疑的,因為LLMs可能會出現格式錯誤,並且偶爾會表現出叛逆行為(例如拒絕遵循指示)。 因此,大部分代理演示代碼都專注於解析模型輸出。

